吴恩达《机器学习》课程总结(17)_大规模机器学习
17.1大型数据集的学习
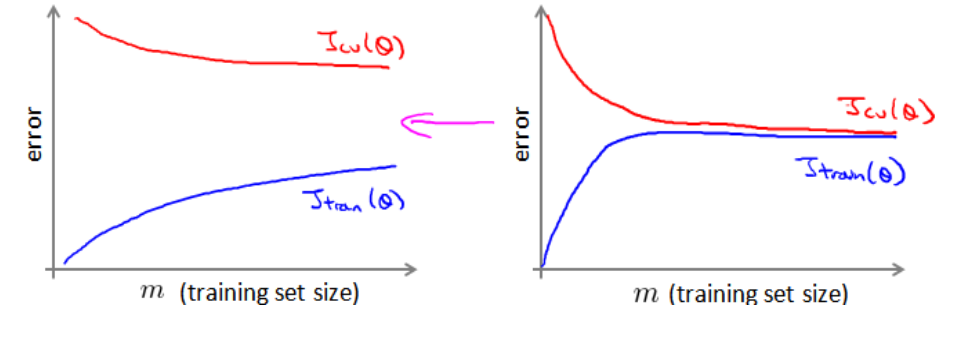
首先通过学习曲线判断是否增大数据集有效:
高方差时(交叉验证集误差减去训练集误差大时)增加数据集可以提高系统。下图中左图增加数据集有效,右图无效。
17.2随机梯度下降法
随机梯度下降法是只使用一个样本来迭代,其损失函数为:
![]()
迭代过程为:
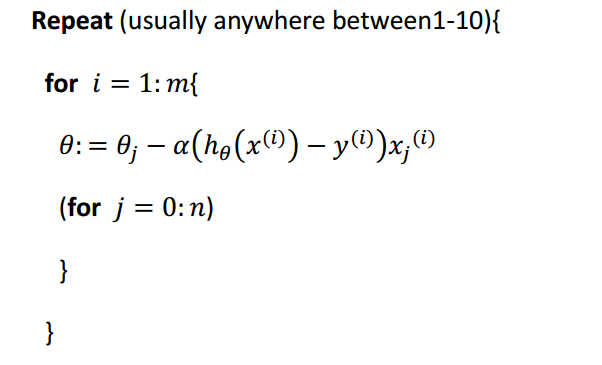
特点:
(1)计算量小,迭代速度快;
(2)在最小值附近徘徊,无法求得最小值。
17.3小批量梯度下降
每次迭代所使用的样本数介于批量梯度下降法和随机梯度下降法之间,通常是2-100。

17.4随机梯度下降收敛
(1)对于批量梯度下降法而言,每次迭代求其代价函数的计算量太大,不现实;
(2)对于随机梯度下降法而言,每次迭代计算代价函数,然后经过x次迭代之后求x次代价函数的平均值,然后将该值与迭代次数绘制到图上。
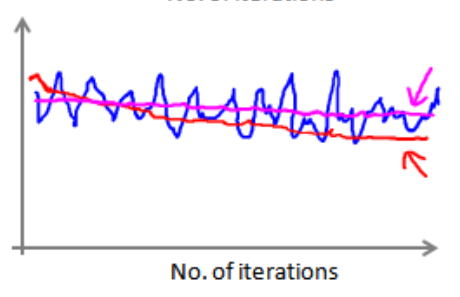
(3)如果得到的图颠簸切看不到明显减少的函数图像,如下图中蓝色所示,可以增加α来时函数更加平缓,如下图红色所示,如果是洋红色可能说明模型本身有问题。
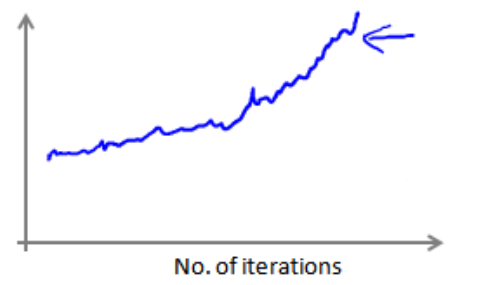
(4)如果出现代价函数随迭代次数的增加而增加,学习率α可能需要随着迭代的次数而减小:
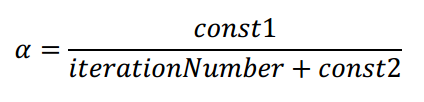
17.5在线学习
常用于网站中,有连续的数据流可供模型来学习,与传统的模型学习没有什么大的差别;如果有连续的数据集,这种方法着重考虑。


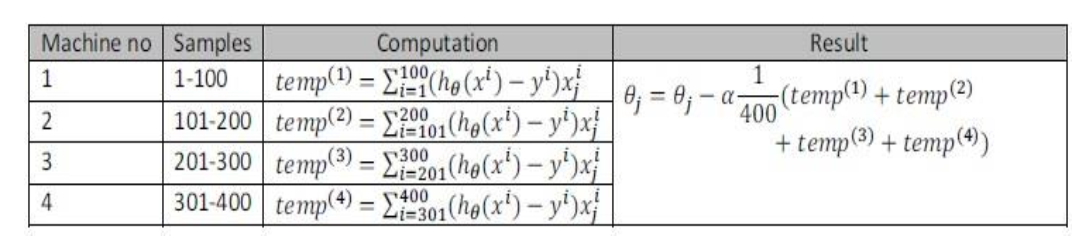
17.6映射简化和数据并行
如果任何学习算法能够表达为对训练集的函数求和,便可以分配到多台计算机中计算子集,然后再求和(也叫做映射简化mapreduce),如下所示(其实就并行计算):
作者:你的雷哥
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号