Python 快速入门:学习Python的基础操作
@
变量赋值
单变量赋值
python中的变量赋值不需要声明类型, 但是变量使用前必须要先赋值, 用等号=来给变量赋值
counter = 100
多变量赋值
在 Python 中,多变量赋值是指同时给多个变量赋值。这是通过将多个变量名列在左侧,并将它们与右侧的值列表一一对应来实现的
a = b = c = 1
a = b = c = 1
a,b,c = 1,2,"test"
a, b, c = [1, 2, 3]
数据类型
python3中有6个标准的数据类型:
Number:数字String:字符串List:列表Tuple:元组Set:集合Dictionary:字典
Number类型
定义
Python3 支持 int、float、bool、complex(复数)
a, b, c, d = 20, 5.5, True, 4+3j
print(type(a), type(b), type(c), type(d)) #输出:<class 'int'> <class 'float'> <class 'bool'> <class 'complex'>
print(isinstance(a, int)) #输出True
数字类型转换
a = 1.0
b = 3
print(int(a)) #输出1
print(float(b)) #输出3.0
运算
print(17//3) #输出5
print(17%3) #求余,输出2
print(5**2) #求平方,输出25
print(25**0.5) #开根号,输出5.0
相关函数
| Number类型函数 | 返回值 ( 描述 ) |
|---|---|
abs(x) |
返回数字的绝对值,如abs(-10) 返回 10 |
math.ceil(x) |
返回数字的上入整数,如math.ceil(4.1) 返回 5 |
math.floor(x) |
返回数字的下舍整数,如math.floor(4.9)返回 4 |
math.exp(x) |
返回e的x次幂,如math.exp(1) 返回2.718281828459045 |
math.log10(x)] |
返回以10为基数的x的对数,如math.log10(100)返回2.0 |
max(x1, x2,...) |
返回给定参数的最大值,参数可以为序列。例如max([1,2,3,4]), 返回4 |
min(x1, x2,...) |
返回给定参数的最小值,参数可以为序列。 |
math.pow(x, y) |
返回x**y运算后的值。 |
round(x,n) |
返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。 |
math.sqrt(x) |
返回数字x的平方根。如math.sqrt(100)返回10 |
String类型
定义
可对字符串进行切片操作
str = 'HelloWorld'
print(str) # 输出字符串: HelloWorld
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符: HelloWorl
print(str[0]) # 输出字符串第一个字符: H
print(str[2:5]) # 输出从第三个开始到第五个的字符: llo
print(str[2:]) # 输出从第三个开始的后的所有字符: lloWorld
print(str * 2) # 输出字符串两次: HelloWorldHelloWorld
print(str + "TEST") # 连接字符串: HelloWorldTEST
字符串格式化
| 字符串格式符号 | 描述 |
|---|---|
%c |
格式化字符及其ASCII码 |
%s |
格式化字符串 |
%d |
格式化整数 |
%u |
格式化无符号整型 |
%o |
格式化无符号八进制数 |
%x |
格式化无符号十六进制数 |
%X |
格式化无符号十六进制数(大写) |
%f |
格式化浮点数字,可指定小数点后的精度 |
%e |
用科学计数法格式化浮点数, 默认保留6位小数 |
%E |
作用同%e,用科学计数法格式化浮点数 |
%g |
根据数值的大小采用%f和%e |
%G |
作用同%g |
%p |
用十六进制数格式化变量的地址 |
print("%.2f"%(10.556)) #输出10.56
print ("我叫%s今年%d岁" % ('henry', 20)) #输出:我叫henry今年20岁
print("%x" % 16) #输出16的十六进制数: 10
print("%e" % 10000) #输出: 1.000000e+04,
print("%.3e" % 0.001) #输出: 1.000e-03
print("%g" % 1000) #输出: 1000
print("%g" % 1000000000) #输出: 1e+09
多行字符串
python可以使用三引号"""包裹多行字符串
para_str = """这是一个多行字符串的实例
多行字符串可以使用制表符
"""
print(para_str)
str.format()
str.format的常用语法:
print("MY NAME IS {},AGE is {}".format('herry','15'))
#输出MY NAME IS herry,AGE is 15
可在format()使用位置参数
>>> print('{0} 和 {1}'.format('Henry', 'Tom'))
Henry 和 Tom
>>> print('{1} 和 {0}'.format('Henry', 'Tom'))
Tom 和 Henry
可在format()使用关键字参数, 它们的值会指向使用该名字的参数
print("MY NAME IS {name},AGE is {age}".format(name='herry',age='15'))
#输出MY NAME IS herry,AGE is 15
也可以位置参数和关键字参数混合
print('名字列表 {0}, {1}, 和 {other}。'.format('Henry', 'Tom', other='Lee'))
#输出:名字列表 Henry, Tom, 和 Lee。
通过:和格式符号可以对值更好的格式化, 例如保留小数点后几位
import math
print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi)) #输出:常量 PI 的值近似为 3.142。
在 : 后传入一个整数, 可以保证该域至少有这么多的宽度。
table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
for name, number in table.items():
print('{0:10} ==> {1:10d}'.format(name, number))
#输出内容如下:
#Google ==> 1
#Runoob ==> 2
#Taobao ==> 3
f-string
f-string是 python3.6之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
格式化字符串以 f 开头, 后面接着字符串, 字符串中的表达式用大括号{}包起来,它会将变量或表达式计算后的值替换进去
name = 'Herry'
print(f'Hello {name}') #输出Hello Herry
print(f'{1+2}') #输出3
a = {'id':1,'name':'faker'}
print(f'我叫{a["name"]},排名第{a["id"]}') #我叫faker,排名第1
相关函数
| python函数 | 描述 |
|---|---|
len(str) |
返回字符串str的长度 |
max(str) |
返回字符串 str 中最大的字母。 |
min(str) |
返回字符串 str 中最小的字母。 |
| String内置函数 | 描述 |
|---|---|
str.capitalize() |
将字符串的第一个字符转换为大写 |
str.center(width,fillchar) |
返回一个宽度为width, str居中的字符串,fillchar为填充的字符, 默认为空格。 |
str.count(sub, beg= 0,end=len(string)) |
返回sub在 str 里面出现的次数,如果 beg 或者 end 指定了, 则返回指定范围内 str 出现的次数 |
bytes.decode(encoding="utf-8") |
Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来对bytes对象进行解码,这个bytes对象可以由 str.encode() 来编码返回。 |
str.encode(encoding='UTF-8') |
对字符串str进行encoding 指定的编码格式编码, 返回bytes对象 |
str.endswith(suffix, beg=0, end=len(string)) |
检查str是否以suffix结束,如果beg 或者 end 指定, 则检查指定的范围内是否以suffix结束,如果是,返回 True,否则返回 False. |
str.expandtabs(tabsize=8) |
把字符串str中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
str.find(sub, beg=0, end=len(str)) |
检测 sub 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
str.index(sub, beg=0, end=len(string)) |
跟find()方法一样,只不过如果sub不在字符串中会报一个异常。 |
str.isalnum() |
如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
str.isalpha() |
如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False |
str.isdigit() |
如果字符串只包含数字则返回 True 否则返回 False..` |
str.islower() |
`如果字符串的字符全是小写字母则返回 True,否则返回 False |
str.isnumberic() |
如果字符串中只包含数字字符,则返回 True,否则返回 False |
str.isspace() |
如果字符串中只包含空白,则返回 True,否则返回 False. |
str.istitle() |
如果字符串是标题化的(见 title())则返回 True,否则返回 False |
str.isupper() |
如果字符串中的字符全是大写,则返回 True,否则返回 False |
str.join(seq) |
以指定字符串str作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
str.ljust(width,fillchar) |
返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
str.lower() |
转换字符串中所有大写字符为小写. |
str.lstrip(chars) |
截掉字符串左边的空格或指定字符chars。 |
str.replace(old,new) |
把将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 |
str.rjust(width,fillchar) |
返回一个原字符串右对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
str.rstrip(chars) |
删除字符串末尾的空格或指定字符chars。 |
str.split(chars="") |
以 chars为分隔符对字符串str进行切片来返回列表 |
str.splitlines(keepends) |
按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
str.startswith(substr, beg=0,end=len(string)) |
检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
str.strip(chars) |
在字符串上执行 lstrip()和 rstrip() |
str.swapcase() |
将字符串中大写转换为小写,小写转换为大写 |
str.title() |
返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写 |
str.upper() |
转换字符串中的小写字母为大写 |
str.isdecimal |
检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
List类型
定义
列表可以使用方括号 [] 来定义,元素之间使用逗号 , 分隔
# 定义一个空列表
lst = []
# 定义一个包含整数的列表
lst = [1, 2, 3, 4, 5]
# 定义一个包含字符串的列表
lst = ['apple', 'banana', 'cherry']
# 定义一个包含多种类型元素的列表
lst = [1, 'apple', 3.14, [1, 2, 3]]
常用操作
读取列表元素和列表的切片与拼接
list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ]
tinylist = [123, 'runoob']
print(list) # 输出完整列表:['abcd', 786, 2.23, 'runoob', 70.2]
print(list[0]) # 输出列表第一个元素:abcd
print(list[1:3]) # 从第二个开始输出到第三个元素:[786, 2.23]
print(list[2:]) # 输出从第三个元素开始的所有元素:[2.23, 'runoob', 70.2]
print(list[-1]) # 输出最后一个元素70.2
print(list[0:-2]) # 输出第一个至倒数第三个元素:['abcd', 786, 2.23]
print(list[1:]) # 输出[786, 2.23, 'runoob', 70.2]
print(list[1::2]) # 输出[786, 'runoob']
print(list[::-1]) # 逆序输出[70.2, 'runoob', 2.23, 786, 'abcd']
print(tinylist * 2) # 输出两次列表:[123, 'runoob', 123, 'runoob']
print(list + tinylist) # 拼接列表,输出['abcd', 786, 2.23, 'runoob', 70.2, 123, 'runoob']
列表与字符串不一样的是, 列表的元素是可以改变的
a = [1,2,3,4,5,6]
a[0] = 9
a[2:5] = [13,14,15]
print(a) #输出[9, 2, 13, 14, 15, 6]
a[2:5] = [] #设置对应的元素为空
print(a) #输出[9, 2, 6]
更新列表元素
list = ['Google', 'Runoob', 1997, 2000]
print ("第三个元素为 : ", list[2])
list[2] = 2001
print ("更新后的第三个元素为 : ", list[2])
list1 = ['Google', 'Runoob', 'Taobao']
list1.append('Baidu')
print ("更新后的列表 : ", list1)
删除列表元素
list = ['Google', 'Runoob', 1997, 2000]
print("原始列表 : ", list) #输出: ['Google', 'Runoob', 1997, 2000]
del list[2]
print("删除后的列表: ", list) #输出: ['Google', 'Runoob', 2000]
相关函数
| python内置函数 | 描述 |
|---|---|
len(list) |
返回列表元素个数 |
max(list) |
返回列表元素最大值 |
min(list) |
返回列表元素最小值 |
| list函数 | 描述 |
|---|---|
list(seq) |
将元组(序列)转换为列表 |
list.append(obj) |
在列表末尾添加新的对象 |
list.count(obj) |
返回某个元素在列表中出现的次数 |
list.extend(seq) |
在列表末尾一次性追加另一个序列中的多个值, 此序列可以是列表,元组,集合 |
list.index(obj,start) |
返回obj元素在列表匹配的第一个索引位置, start表示查找的起始位置 |
list.insert(index,obj) |
在列表的指定索引插入元素 |
list.pop(index) |
移除列表的指定索引元素, 若index为空则默认移除最后一个元素 |
list.remove(obj) |
移除列表中某个值的第一个匹配项 |
list.reverse() |
逆转列表元素的索引位置 |
list.sort(key=None,reverse=False)
key: 将key作标准来进行排序, 可以是表达式或者函数
reverse: False表示升序, True表示降序
如下代码所示, 将列表元素按字符串长度进行排序输出, 以下有两种解决思路:
fruits = ['grape','pear','apple','water melon']
#lambda声明匿名函数,使用格式为lambda arguments : expression,执行表达式并返回结果
fruits.sort(key=lambda x:len(x))
print(fruits)
fruits = ['grape','pear','apple','water melon']
fruits.sort(key=len)
print(fruits)
元组类型
定义
元组与列表类似,但是元组的元素不能修改。
元组使用小括号 ( ),列表使用方括号 [ ]。
tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5 )
tup3 = "a", "b", "c", "d"
print(type(tup3)) #tup1,tup2,tup3均为元组类型
若元组中只包含一个元素,则需要在元素后面添加逗号, 否则()会被识别成运算符
tup1 = (60)
print(type(tup1)) #输出<class 'int'>
tup2 = (60,)
print(type(tup2)) #输出<class 'tuple'>
常用操作
使用下标索引来访问元组中的值, 也可以对元组进行切片操作
tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7)
print(tup1[0]) #输出Google
print(tup2[1:5]) #输出(2, 3, 4, 5)
虽然元组中的元素值是不允许修改的,但可以对元组进行拼接组合
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
tup3 = tup1 + tup2
print (tup3) #输出(12, 34.56, 'abc', 'xyz')
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组
tup = ('Google', 'Runoob', 1997, 2000)
del tup
print (tup) #输出直接报错,因为元组已被删除
相关函数
| python内置函数 | 描述 |
|---|---|
len(tuple) |
计算元组元素个数 |
max(tuple) |
返回元组中元素最大值 |
min(tuple) |
返回元组中元素最小值 |
tuple(iterable) |
将可迭代系列转换为元组。 |
字典类型
定义
字典用大括号{}来定义。
键必须是唯一的, 值是可变的。
mydict = {'name': 'runoob', 'likes': 123, 1: 'www.runoob.com'}
print(mydict[1]) #输出www.runoob.com
print(mydict['name']) #输出runoob
常用操作
使用dict()函数创建字典
emptyDict = dict()
print(emptyDict) #输出空字典:{}
print(len(emptyDict)) #输出字典的长度:0
访问字典的值
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print (tinydict['Name']) #输出
print (tinydict['Age'])
修改和更新字典的值
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
tinydict['Age'] = 8 # 更新 Age
tinydict['School'] = "北京大学" # 添加信息
print (tinydict['Age']) #输出8
print (tinydict['School']) #输出'北京大学'
删除字典元素
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
del tinydict['Name'] # 删除键 'Name'
tinydict.clear() # 清空字典
del tinydict # 删除字典
print (tinydict['Age']) #输出直接报错,因为字典已被删除
相关函数
| 函数 | 描述 |
|---|---|
len(dict) |
计算字典元素个数, 即键的总数。 |
str(dict) |
用字符串的形式输出字典, 例如输出:"{'Name': 'Runoob', 'Class': 'First', 'Age': 7}" |
dict.clear() |
删除字典内所有元素 |
dict.copy() |
返回一个字典的浅复制 |
dict.fromkeys(seq,values) |
用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值 |
dict.get(key,[value]) |
返回指定键的值,如果键不在字典中返回默认值 None 或者设置的默认值。 |
key in dict |
如果键在字典dict里返回true,否则返回false |
dict.items() |
Python 字典 items() 方法以列表返回视图对象,是一个可遍历的key/value 对 |
dict.keys()dict.values() |
返回一个视图对象 |
dict.pop(key) |
删除字典key键所对应的值,返回被删除的值 |
dict.popitem() |
返回并删除字典中最后一对键和值 |
dict.fromkeys(seq,values)
country = ['China','England','America','France']
dict = {}
dict = dict.fromkeys(country,'')
print(dict)
使用dict.items()同时遍历字典的键与值, 使用dict.keys()和dict.values()分别遍历字典的键与值
dict = {'China':1,'England':2,'America':3,'France':4}
for key,value in dict.items():
print(key+" ===> "+str(value))
'''输出如下:
China ===> 1
England ===> 2
America ===> 3
France ===> 4
'''
for key in dict.keys():
print(key)
'''输出如下:
China
England
America
France
'''
for value in dict.values():
print(value)
'''输出如下:
1
2
3
4
'''
集合类型
定义
集合是一个无序的不重复元素序列, 使用大括号{ }或set()函数来创建
常用操作
以下是两个集合之间的运算
a = set('abacha')
print(a) #输出{'c', 'a', 'h', 'b'}
b = set('jabka')
print(b) #输出{'k', 'a', 'j', 'b'}
print(a|b) #输出a与b的并集:{'a', 'k', 'b', 'h', 'j', 'c'},
print(a&b) #输出a与b的交集:{'b', 'a'}
print(a^b) #输出不同时包含于a和b的元素:{'c', 'j', 'h', 'k'}
集合添加元素: set.add()、set.update()
thisset = set(("Google", "Runoob", "Taobao"))
thisset.add("Facebook")
print(thisset) #输出{'Taobao', 'Runoob', 'Facebook', 'Google'}
thisset.update([1,2])
print(thisset) #输出{1, 2, 'Taobao', 'Runoob', 'Facebook', 'Google'}
集合移除元素: set.remove(element)、set.discard(element)、set.pop()
thisset = set(("Google", "Runoob", "Taobao"))
thisset.remove("Taobao") #若元素不存在则会报错
print(thisset) #输出{'Google', 'Runoob'}
thisset = set(("Google", "Runoob", "Taobao"))
thisset.discard("Taobao") #若元素不存在不会报错
print(thisset) #输出{'Google', 'Runoob'}
thisset = set(("Google", "Runoob", "Taobao"))
x = thisset.pop() #随机删除一个元素
求集合元素的个数: len(set)
thisset = set(("Google", "Runoob", "Taobao"))
print(len(thisset)) #输出3
清空集合元素: set.clear()
thisset = set(("Google", "Runoob", "Taobao"))
thisset.clear()
print(thisset) #输出set()
强制转换
在 Python 中,可以使用一些内置的函数来强制转换数据类型
| 强制转换函数 | 描述 |
|---|---|
int(x) |
将x转换为一个整数 |
float(x) |
将x转换到一个浮点数 |
str(x) |
将对象 x 转换为字符串 |
repr(x) |
将对象 x 转换为表达式字符串 |
eval(str) |
用来计算在字符串中的有效Python表达式,并返回一个对象 |
tuple(s) |
将序列 s 转换为一个元组 |
list(s) |
将序列 s 转换为一个列表 |
set(s) |
转换为可变集合 |
dict(d) |
创建一个字典。d 必须是一个 (key, value)元组序列。 |
frozenset(s) |
转换为不可变集合 |
chr(x) |
将一个整数转换为一个字符 |
ord(x) |
将一个字符转换为ASCII码 |
hex(x) |
将一个整数转换为一个十六进制字符串 |
oct(x) |
将一个整数转换为一个八进制字符串 |
推导式
定义
Python 推导式可实现从一个数据序列构建另一个新的数据序列
Python 支持各种数据结构的推导式
- 列表推导式
- 字典推导式
- 集合推导式
- 元组推导式
列表推导式
过滤掉长度小于或等于3的字符串列表,并将剩下的转换成大写字母:
names = ['Bob','Tom','alice','Jerry','Wendy','Smith']
new_names = [name.upper() for name in names if len(name)>3]
print(new_names) #输出:['ALICE', 'JERRY', 'WENDY', 'SMITH']
计算 30 以内可以被 3 整除的整数
multiples = [i for i in range(30) if i % 3 == 0]
print(multiples) #输出:[0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
字典推导式
将列表转换成字典, 其中键为字符串值, 值为字符串长度
listdemo = ['Google','Runoob', 'Taobao']
newdict = {key:len(key) for key in listdemo}
print(newdict) #输出{'Google': 6, 'Runoob': 6, 'Taobao': 6}
集合推导式
判断不是abc的字母并输出
a = {x for x in 'abracadabra' if x not in 'abc'}
print(a) #输出{'d', 'r'}
元组推导式
生成一个包含1~9的元组
a = (x for x in range(1,10))
print(a) #输出生成器对象:<generator object <genexpr> at 0x000001DB1C5EF270>
print(tuple(a)) #(1, 2, 3, 4, 5, 6, 7, 8, 9)
迭代器与生成器
迭代器
定义
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退
迭代器主要涉及两个函数: iter()和next()
iter(): 将可迭代对象转换为迭代器next(): 依次访问迭代器里面的函数
常用操作
创建迭代器对象
list=[1,2,3,4]
it = iter(list) #创建迭代器对象
print(next(it)) #输出1
print(next(it)) #输出2
for语句遍历迭代器对象
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ") #输出1 2 3 4
生成器
定义
在 Python 中,有一种特殊的函数叫做生成器,它使用 yield 关键字返回值。生成器能够在循环的过程中不断推算出后续的值,而不必创建完整的列表,从而节省空间。
列表生成式是一种快速创建列表的方式,但当列表中的元素数量很多时,会占用大量的存储空间。使用生成器能够在循环的过程中推算出后续的元素,而不必一次性创建完整的列表。这样就能节省大量的空间
常用操作
著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到, 例如:1, 1, 2, 3, 5, 8, 13, 21, 34, ...
def fib(sum):
a, b, c = 0, 1, 0
while c < sum:
yield b # 代码执行到这里,会跳出这个函数,并将b的值返回到使用next的代码处
a, b = b, a + b
c += 1
p = fib(6)
print(next(p)) #输出1
print(next(p)) #输出1
print(next(p)) #输出2
print(next(p)) #输出3
print(next(p)) #输出5
print(next(p)) #输出8
在 Python 中,生成器函数使用 yield 语句返回值,而不是使用 return 语句。如果想要在生成器中使用 return 语句, 可通过捕获生成器的 StopIteration 异常。当生成器的 return 语句被执行时,会抛出 StopIteration 异常,并结束生成器的执行, return语句的返回值包含在StopIteration的value中
def fib(sum):
a, b, c = 0, 1, 0
while c < sum:
yield b
a, b = b, a + b
c += 1
return "返回值只能传递给异常"
g = fib(3)
while True:
try:
x = next(g)
print('g:', x)
except StopIteration as e:
print('Generator return value:', e.value)
break
def fib(sum):
a, b, c = 0, 1, 0
while c < sum:
yield b
a, b = b, a + b
c += 1
return "返回值只能传递给异常"
g = fib(3)
while True:
try:
x = next(g)
print('g:', x)
except StopIteration as e:
print('Generator return value:', e.value)
break
"""
输出如下所示:
g: 1
g: 1
g: 2
Generator return value: 返回值只能传递给异常
"""
函数
参数
1.必须参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样,调用 printme() 函数,你必须传入一个参数,不然会出现语法错误
def printme(str):
"打印任何传入的字符串"
print (str)
return
# 调用printme 函数,不加参数会报错
printme()
2.关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值
def printme(str):
"打印任何传入的字符串"
print (str)
return
#调用printme函数
printme(str="HelloWorld") #输出"HelloWorld"
3.默认参数
调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值
# 可写函数说明
def printinfo(name, age=35):
"打印任何传入的字符串"
print("名字: ", name)
print("年龄: ", age)
return
# 调用printinfo函数
printinfo(name="Henry", age=22) #输出:"名字:Henry 年龄:22"
printinfo(name="Tom") #输出:"名字:Tom 年龄:35"
4.不定长参数
不定长参数是指函数的参数个数是不确定的。不定长参数可以接受任意数量的参数,并将它们作为一个元组返回
可以使用 * 操作符定义不定长参数。例如,下面是一个函数,它使用不定长参数计算传入的所有数字的平均值
def avg(*args):
total = 0
for arg in args:
total += arg
return total / len(args)
print(avg(1, 2, 3)) # 2.0
print(avg(1, 2, 3, 4, 5)) # 3.0
print(avg()) # 0.0
不定长关键字参数可以接受任意数量的关键字参数,并将它们作为一个字典返回
在 Python 中,可以使用 ** 操作符定义不定长关键字参数。例如下面是一个函数,它使用不定长关键字参数打印传入的所有关键字参数
def my_func(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
my_func(a=1,b=2,c=3)
'''
Output:
a: 1
b: 2
c: 3
'''
匿名函数
定义
Python 使用 lambda 来创建匿名函数。所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数
虽然 lambda 函数看起来只能写一行,却不等同于 C 或 C++ 的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率
lambda 函数的使用语法如下:
lambda [arg1 [,arg2,.....argn]]:expression
使用实例
定义一个返回两个参数相加后的结果的匿名函数
sum = lambda arg1, arg2: arg1 + arg2
# 调用sum函数
print ("相加后的值为 : ", sum( 10, 20 ))
print ("相加后的值为 : ", sum( 20, 20 ))
#输出结果如下:
#相加后的值为 : 30
#相加后的值为 : 40
读写文件
文件模式
| 模式 | 描述 | 若文件不存在 |
|---|---|---|
r |
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 | 出错 |
rb |
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 | 出错 |
r+ |
打开一个文件用于读写。文件指针将会放在文件的开头。 | 出错 |
rb+ |
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 | 出错 |
w |
打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 | 建立 |
wb |
以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 | 建立 |
w+ |
打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 | 建立 |
wb+ |
以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 | 建立 |
a |
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件进行写入。 | 建立 |
ab |
以而二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件进行写入。 | 建立 |
a+ |
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写 | 建立 |
ab+ |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写 | 建立 |
file对象函数
| file对象函数 | 描述 |
|---|---|
file.close() |
关闭文件。 |
file.flush() |
刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入 |
file.fileno() |
返回一个整型的文件描述符, 可以用在如os模块的read方法等一些底层操作上 |
file.isatty() |
如果文件连接到一个终端设备返回 True,否则返回 False |
file.read([size]) |
从文件读取指定的字节数,如果未给定或为负则读取所有 |
file.readline([size]) |
读取整行,包括 "\n" 字符。 |
file.readlines([sizenint]) |
读取所有行并返回列表 |
file.seek(offset,[whence]) |
移动文件读取指针到指定位置 |
file.tell() |
返回文件当前位置 |
file.truncate([size]) |
从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除 |
file.write(str) |
将字符串写入文件, 并返回写入字符的长度 |
file.writelines(sequence) |
向文件写入一个字符串列表,如果需要换行则要自己加入每行的换行符 |
文件操作常用函数
file.read()
file = open('text.txt','r+')
print(file.read())
# 输出文件所有内容:
# www.taobao.com
# www.jd.com
# www.baidu.com
file.close()
file = open('text.txt','r+')
print(file.read(10))
#输出10个字节的文件内容:www.taobao
file.close()
file.readline()
file = open('text.txt','r+')
print(file.readline())
# 输出文件一行内容:
# www.taobao.com
file.readlines()
file = open('text.txt','r+')
print(file.readlines())
#输出含有文件所有内容的列表(包含换行符):
['www.taobao.com\n', 'www.jd.com\n', 'www.baidu.com\n', '\n']
file.close
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
>>> f.close()
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: I/O operation on closed file
当处理一个文件对象时, 使用 with 关键字是非常好的方式。在结束后, 它会帮你正确的关闭文件
with open('result.txt','w+') as f:
f.write("this is testing")
print(f.closed) #判断文件是否关闭,输出True
file.seek(offset,[whence])
-
offset: 移动偏移的字节数
-
whence: 默认值为0; 0表示从文件开头开始, 1表示从当前位置开始, 2表示从文件末尾开始
f = open('workfile', 'rb+')
f.write("0123456789abcdef")
f.seek(5) #移动至第六个字节
print(f.read(1)) #输出5
f.seek(-3,2) #移动到文件倒数第三个字节
print(f.read(1)) #输出'd'
file.write(str)
- str: 要写入的字符串
# 打开文件
fo = open("test.txt", "r+")
print ("文件名: ", fo.name)
str = "6:www.test.com"
# 在文件末尾写入一行
fo.seek(0,2) #移动至文件内容末尾
line = fo.write(str )
# 读取文件所有内容
fo.seek(0,0) #移动至文件内容开头
for index in range(6):
line = next(fo)
print ("文件行号 %d - %s" % (index, line))
# 关闭文件
fo.close()
file.writelines(seq)
- seq: 要写入文件的字符串序列
fo = open("test.txt", "w")
print ("文件名为: ", fo.name)
seq = ["Henry", "Tom"]
fo.writelines( seq )
# 关闭文件
fo.close()
命名空间和作用域
命名空间
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python字典来实现的
命名空间提供了在项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系的,所以一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响
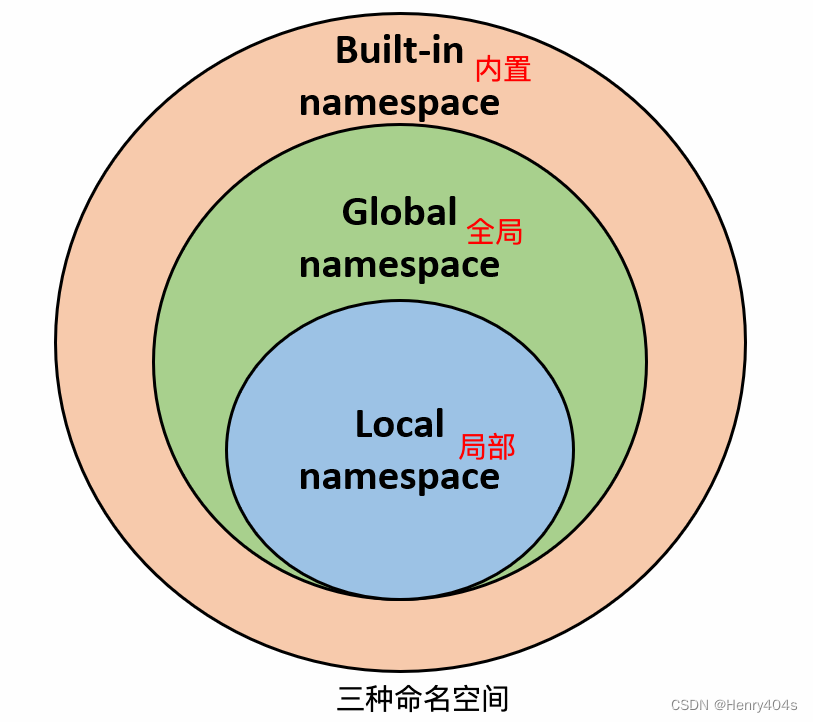
分类
一般有三种命名空间, 其查找顺序为: 局部名称 -> 全局名称 -> 内置名称
- 内置名称(built-in names): Python 语言内置的名称,比如函数名
abs、char和异常名称BaseException、Exception等等。 - 全局名称(global names): 模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names): 函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量,类中定义的也是
生命周期
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。因此, 我们无法从外部命名空间访问内部命名空间的对象
作用域
作用域就是一个 Python 程序可以直接访问命名空间的正文区域
在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。
分类
Python 的作用域一共有4种, 其搜索顺序为:L –> E –> G –> B
- L(Local):最内层, 包含局部变量,例如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于B中的名称来说 A 中的作用域就为非局部(nonlocal)。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
global和nonlocal
当内部作用域想修改外部作用域的变量时,就要用到 global 和 nonlocal 关键字了
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num) #输出1
num = 123
print(num) #输出123
fun1()
print(num) #输出123
如果要修改嵌套作用域(enclosing 作用域)中的变量则需要nonlocal关键字了
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
上述代码中使用关键字
nonlocal声明了num变量, 表示此变量非局部变量, 其作用域为outer函数
异常处理
异常捕捉
Python中使用try、except、finally组合来捕捉异常,except中的Exception是所有异常的父类
try:
int("12a") # 抛出可能出现异常的代码
except IndexError as e: # 捕捉索引异常的子异常
print("IndexError:",e) #输出:ValueError: invalid literal for int() with base 10: '12a'
except ValueError as e: # 捕捉value错误的子异常
print("ValueError:",e)
except Exception as e: # 使用Exception捕获,Exception能够捕获所有的异常
print("Exception:",e)
else: # 如果都没有异常发生,执行else中的代码块
print("true")
finally: # 不管是否发生异常,在最后都会执行finally中的代码,假如try里面的代码正常执行,先执行else中的代码,再执行finally中的代码
print("finally")
#输出内容如下:
# ValueError: invalid literal for int() with base 10: '12a'
# finally
自定义异常
因为Exception是所有异常的父类,所以可以自定义Exception的子类,实现自定义异常处理
class TypeErrorException(Exception):
def __init__(self, message):
self.message = message
def __str__(self): # 打印异常的时候会调用对象里面的__str__方法返回一个字符串
return self.message
if __name__ == "__main__":
try:
raise TypeErrorException("Type error") #抛出TypeErrorException异常
except TypeErrorException as e:
print("TypeErrorException:", e) #输出异常:TypeErrorException: Type error
except Exception as e:
print("Exception:", e)
else:
print("true")
finally:
print("finally")
断言
断言assert一般用在判断执行环境上, 只要断言的条件不满足, 就会抛出异常且后续代码不会被执行
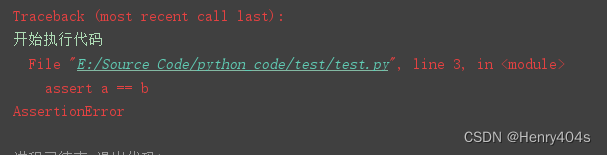
如下所示为断言条件不满足:
print("开始执行代码")
a,b=1,2
assert a == b
print("结束执行代码")
如下所示为断言条件满足:
print("开始执行代码")
a,b=1,1
assert a == b
print("结束执行代码")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号