
Spark大数据技术与应用
第1章 Spark概述
1.1 认识Spark
1.1.1 Spark的发展
- Spark在2009年诞生:交互式查询和迭代算法设计,支持内存存储和高效的容错恢复。
- 2010年,Spark开源。
- 2016年,Spark2.0发布。
1.1.2 Spark的特点
- 快速
- 易用
- 通用
- 随处运行
- 代码简洁
1.1.3 Spark生态圈
Spark的重要组件:
- Spark Core
- BlinkDB
- Spark SQL:可以执行SQL查询,包括基本的SQL语法和HiveQL语法。
- Spark Streaming
- MLBase
- MLlib
- Graphx
1.1.4 Spark的应用场景
- 腾讯
- Yahoo
- 淘宝
- 优酷土豆
1.2 搭建Spark环境
1.2.1 搭建单机版环境
将安装包解压后,在spark的bin目录下计算SparkPi。
./run-example SparkPi 2
1.2.2 搭建单机伪分布式环境
(跳过)
1.2.3 搭建完全分布式环境
- Java版本:https://www.oracle.com/webapps/redirect/signon?nexturl=https://download.oracle.com/otn/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-windows-x64.exe
- scala版本:https://downloads.lightbend.com/scala/2.11.2/scala.msi
- hadoop版本:https://archive.apache.org/dist/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
- spark版本:Index of /dist/spark/spark-2.4.0 (apache.org)
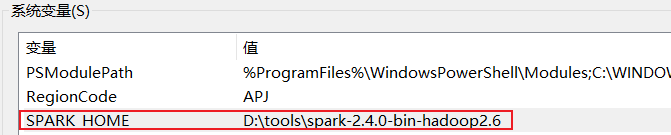
Path变量:

1.3 Spark运行架构与原理
1.3.1 Spark集群架构
1.3.2 Spark作业运行流程
①Standalone运行模式
②YARN运行模式
③Mesos运行模式
1.3.3 Spark核心数据集RDD
RDD:弹性分布式数据集。一个提供了许多操作接口的数据集合。
- RDD的实际数据被划分为一到多个分区,所有分区数据分布存储于一批机器中(内存或磁盘中)。
RDD的两大操作:转换(Transformations)和操作(Actions)。
转换:把原始数据集加载到RDD以及把一个RDD转换为另外一个RDD
操作:把RDD存储到硬盘或触发转换执行。
如:map是一个Transformation操作,该操作作用于数据集上的每一个元素,并且返回一个新的RDD作为结果。
reduce是一个Action操作,该操作通过一些函数聚合RDD中的所有元素并且返回最终的结果给Driver程序。
1.3.4 Spark核心原理
窄依赖:子RDD的一个分区只依赖于某个父RDD中的一个分区。
宽依赖:子RDD的每一个分区都依赖于某个父RDD的一个以上分区。
第2章 Scala基础
2.1 Scala简介及安装,数组与函数
2.2 Scala循环判断、数据结构与类
类和对象
模式匹配
- Scala提供了强大的模式匹配机制。
- 一个模式匹配包含了一系列备选项,每个都开始于关键字case。
- 每个备选项都包含了一个模式及一到多个表达式。
- 模式和表达式之间用“=>”隔开。


1 object test1 { 2 def main(args: Array[String]): Unit = { 3 matchTest(3) 4 } 5 6 def matchTest(x: Int): Unit = x match { 7 case 1 => println("one") 8 case 2 => println("two") 9 case _ => println("many") 10 } 11 }

样例类
- 在Scala中,使用了case关键字定义的类称为样例类,样例类是一种特殊的类,经过优化用于模式匹配。
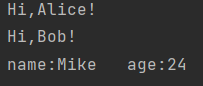
1 object test1 { 2 def main(args: Array[String]): Unit = { 3 4 } 5 6 // 样例类 7 case class Person(name: String, age: Int) 8 9 val alice = new Person("Alice", 25) 10 val bob = new Person("Bob", 22) 11 val mike = new Person("Mike", 24) 12 for (person <- List(alice, bob, mike)) { 13 person match { 14 case Person("Alice", 25) => 15 println("Hi,Alice!") 16 case Person("Bob", 22) => 17 println("Hi,Bob!") 18 case Person(name, age) => 19 println("name:" + name + "\t" + "age:" + age) 20 } 21 } 22 }
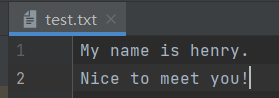
写文件
- Scala不提供任何特殊文件写入能力,所以进行文件的写操作使用的是Java的I/O类中的PrintWriter来实现。
1 object test1 { 2 def main(args: Array[String]): Unit = { 3 import java.io._ 4 val pw = new PrintWriter(new File("test.txt")) 5 pw.write("My name is henry.\nNice to meet you!") 6 pw.close() 7 } 8 }
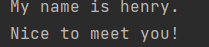
读文件
1 object test2 { 2 import scala.io.Source 3 def main(args: Array[String]): Unit = { 4 Source.fromFile("test.txt").foreach{print} 5 6 7 } 8 }
第3章 Spark编程初步
3.1 创建RDD
(1)启动Spark shell交互式命令终端
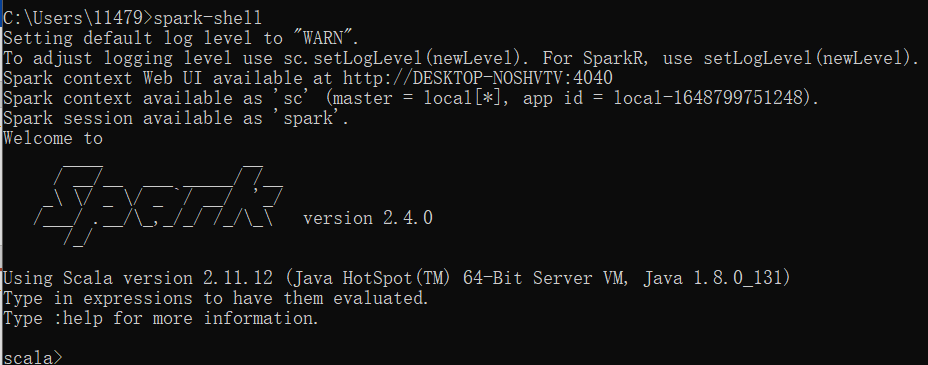
(2)设置日志级别
1 org.apache.log4j.Logger.getLogger("org").setLevel(org.apache.log4j.Level.WARN) 2 org.apache.log4j.Logger.getLogger("akka").setLevel(org.apache.log4j.Level.WARN)
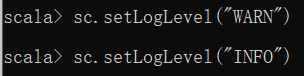
(3)创建RDD的方式
从集合中创建RDD
-
parallelize():通过parallelize函数把一般数据结构加载为RDD
-
makeRDD():通过makeRDD函数把一般数据结构加载为RDD
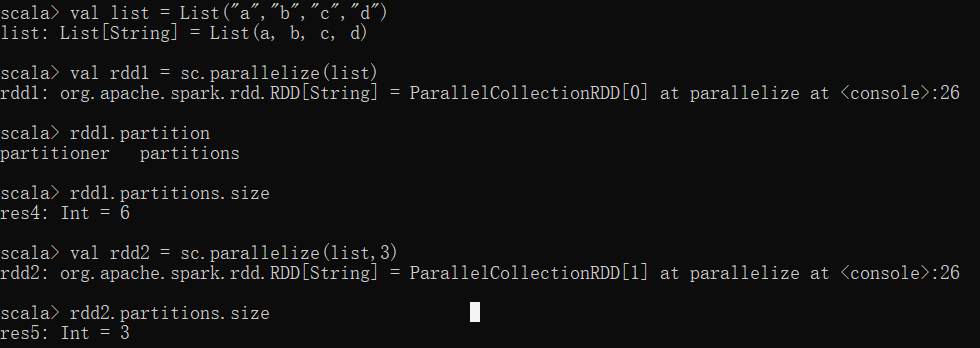
从外部存储创建RDD
-
通过textFile直接加载数据文件为RDD
1.textFile逐行读取,读取后以逗号分隔每行
2.rdd.take(元素个数)返回String类型的数组


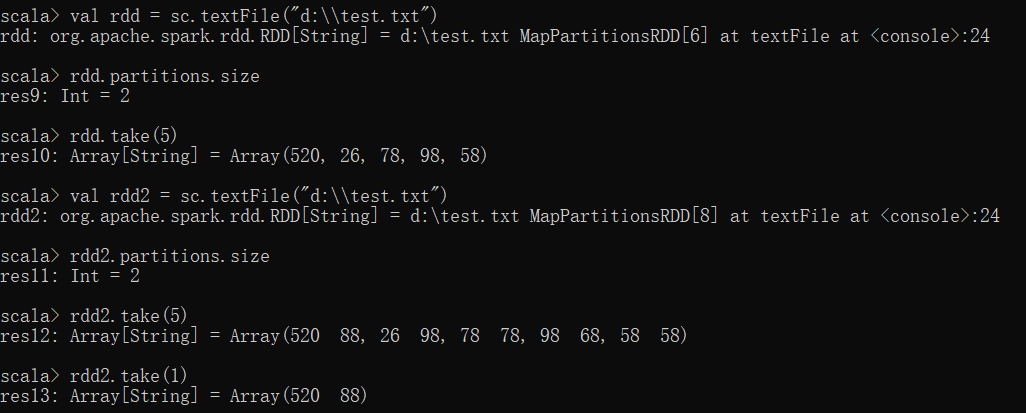

(4)任务实现
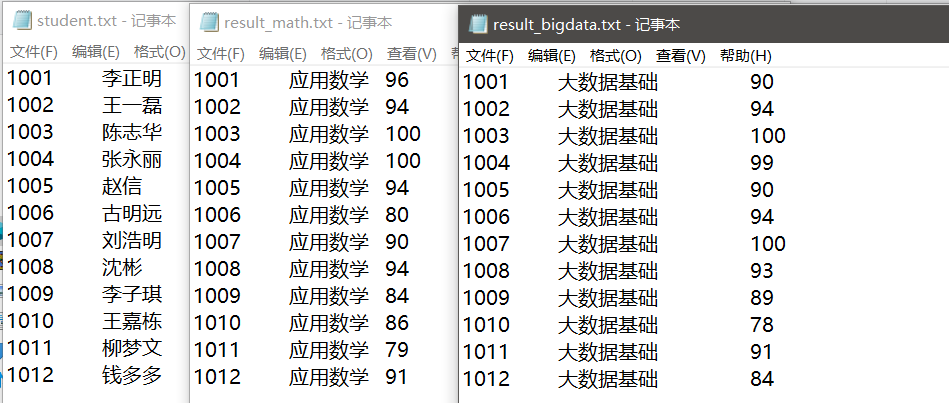
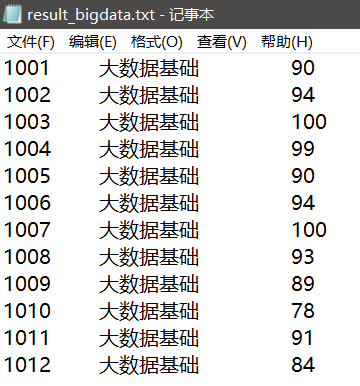
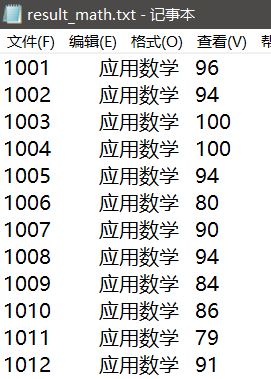
有三份文件,分别为student.txt(学生信息表),result_bigdata.txt(大数据基础成绩表),result_math.txt(数学成绩表)
加载result_bigdata.txt名称为bigdata的RDD数据,result_math.txt名称为math的RDD数据







3.2 RDD转换与操作
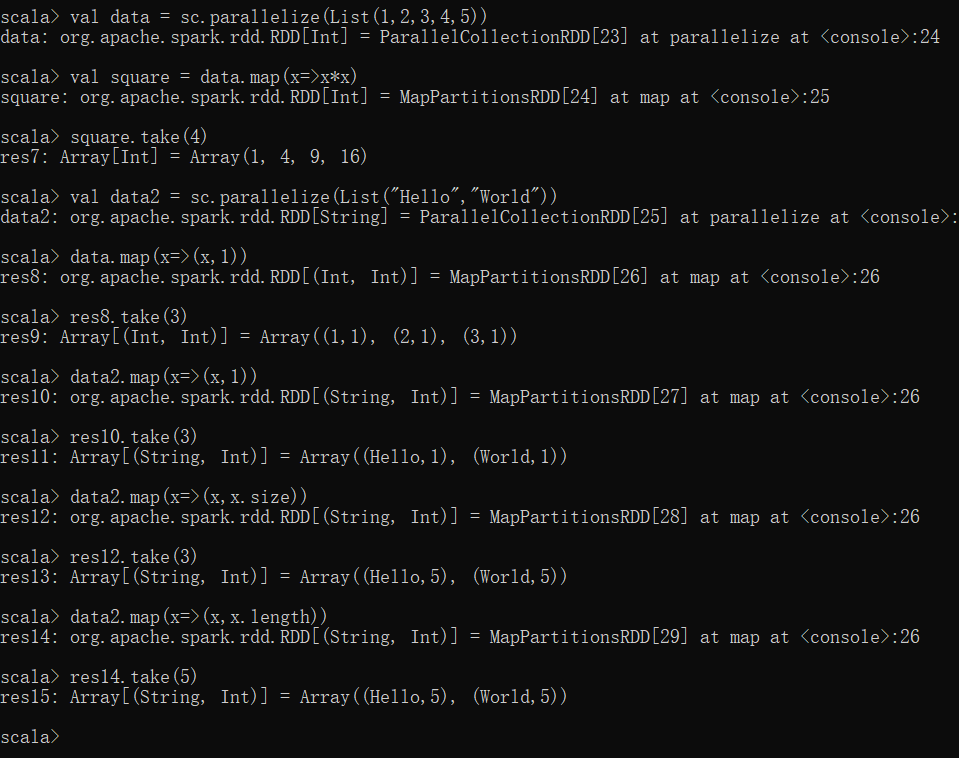
(1)map
-
使用map函数对RDD中每个元素进行倍数操作

-
使用map函数产生键值对RDD

2022.4.8.练习:
(2)flatMap
-
使用flatMap对集合中的每个元素进行操作再扁平化
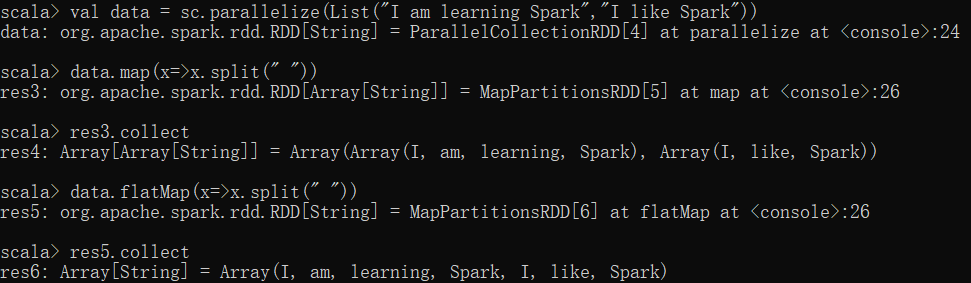
练习:


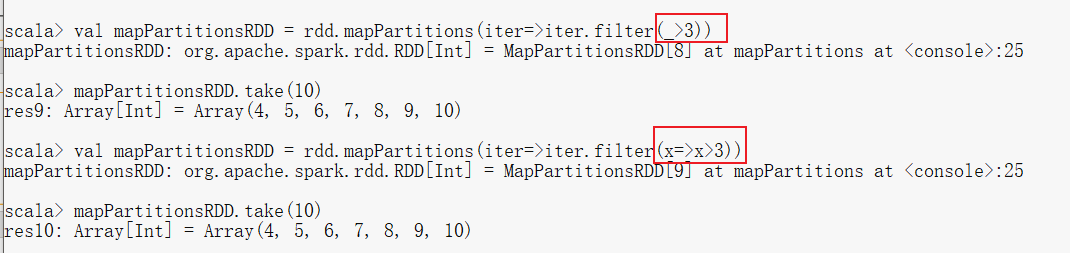
(3)mapPartitions
- mapPartitions:和map功能类似,但是输入的元素是整个分区,即传入函数的操作对象是每个分区的Iterator集合,该操作不会导致Partitions数量的变化

(4)sortBy()
- sortBy()是对标准RDD进行排序的方法。
- sortBy()可接受三个参数
- 第一个参数是一个函数f:(T) => K,左边是要被排序对象中的每一个元素,右边返回的值是元素中要进行排序的值。
- 第二个参数是ascending,决定排序后RDD中的元素是升序还是降序,默认是true,也就是升序。
- 第三个参数是numPartitions,该参数决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的个数相等,即为this.partitions.size。



(5)任务实现
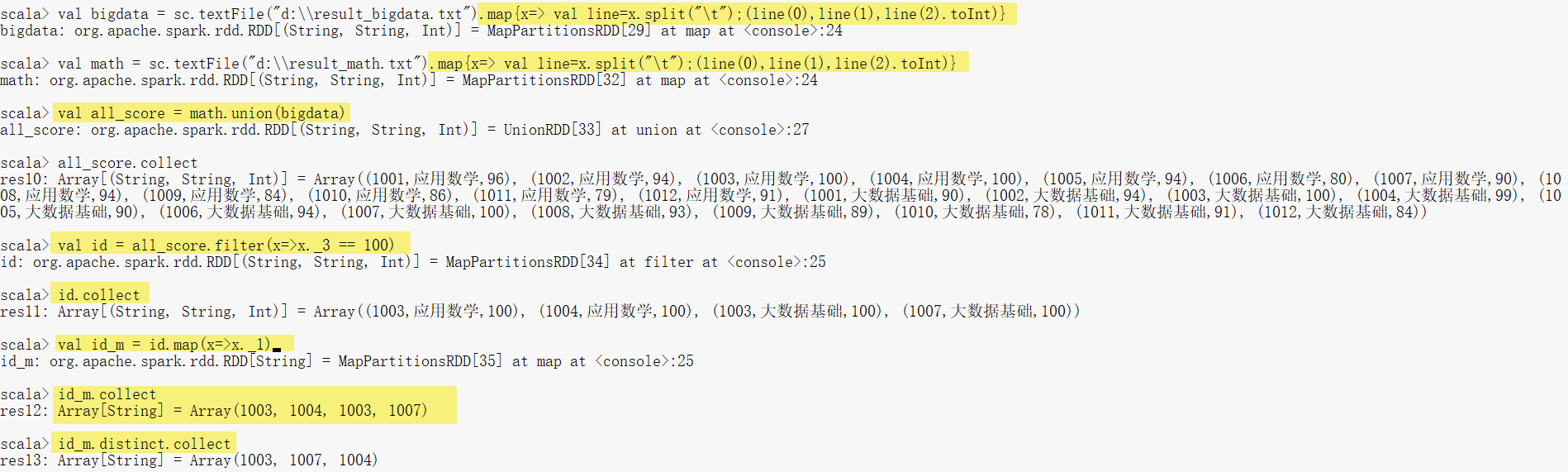
- 根据 3.1 (4)任务实现得到的RDD bigdata及math,取出成绩排名前5的学生成绩信息
- 先将两个成绩表的RDD中的数据进行转换,每条数据被分成3列,表示学生ID、课程、成绩,分隔符为“\t”,存储为三元组格式,成绩要求转化为Int类型,可以直接通过toInt的转化。

- 通过sortBy对元组中的成绩列降序排序,排序位置是每个元组的第3位的成绩

- 通过take操作取出每个RDD的前5个值就是成绩排在前5的学生

(6)filter

(7)distinct:去重

(8)union

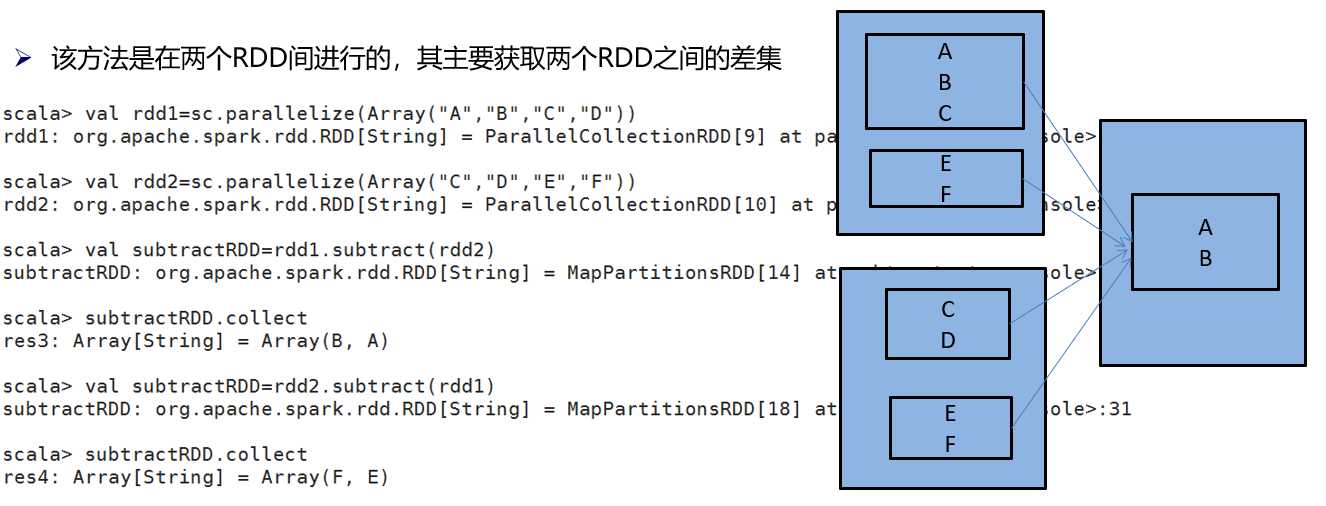
(9)subtract
(10)intersection

(11)cartesian

(12)任务2及实现


思路2:
(13)键值对RDD



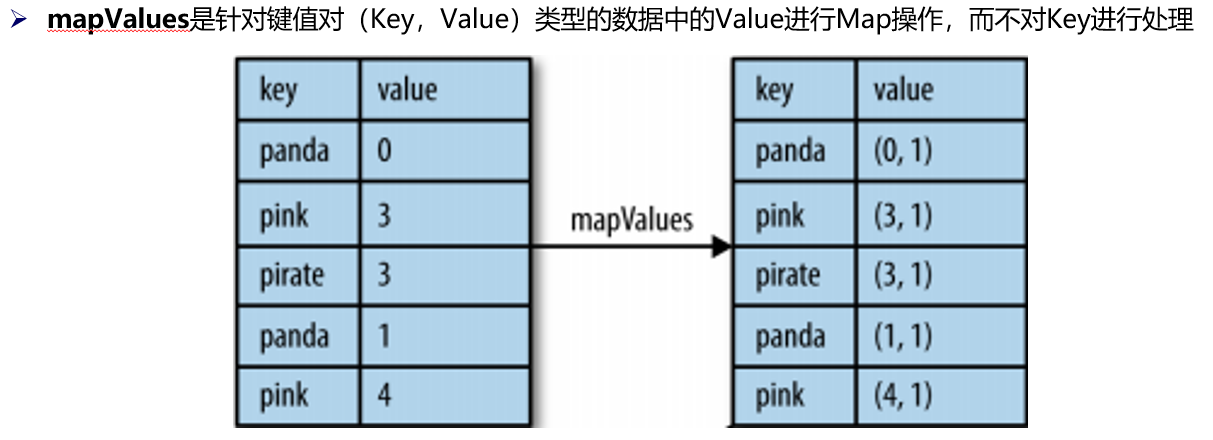
(14)mapValues

(15)groupBy

(16)groupByKey

(17)reduceByKey
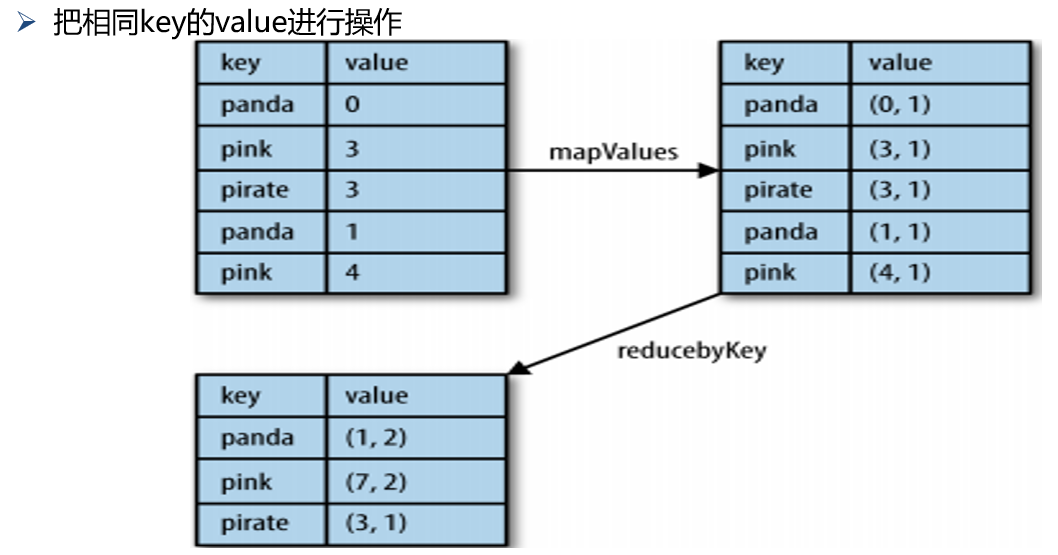

(18)任务3及实现

(19)join
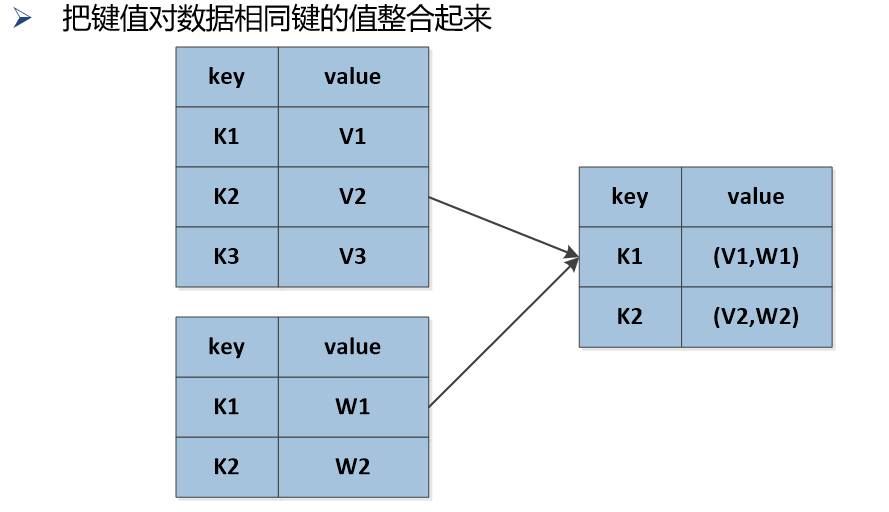

(20)zip

(21)CombineByKey


(22)lookup

(23)任务4及实现

(24)collect

(25)saveAsTextFile
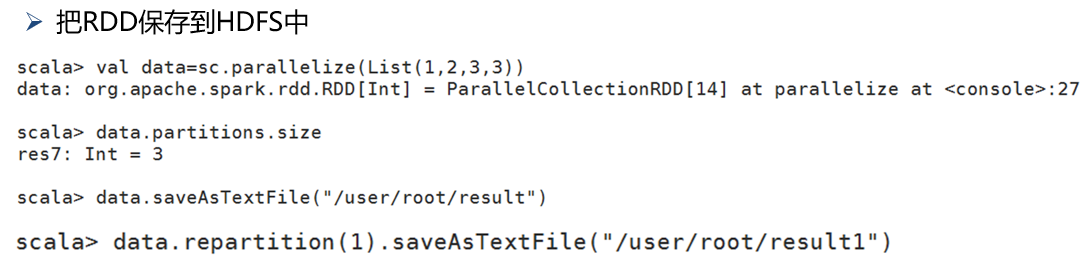
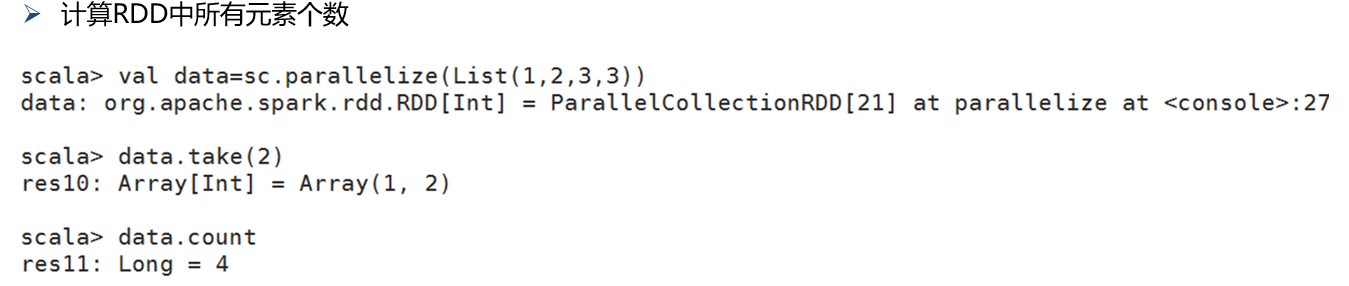
(26)take(num)

(27).count()
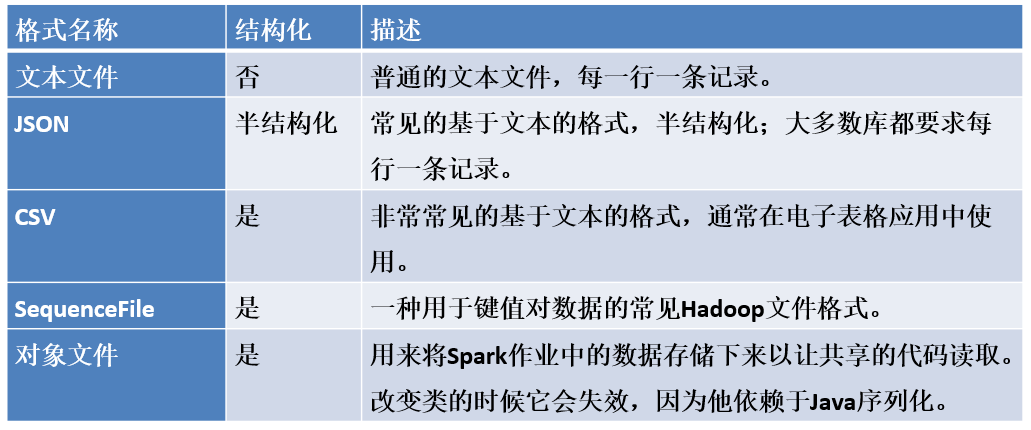
3.3 文件的读取与存储
第4章 Spark编程进阶
持久化
转化一个集合为RDD,
然后将RDD中的每个值都进行平方,
设置存储级别为MEMORY_ONLY,
通过RDD的数值计算方法分别计算平均值和求和,并输出结果。
如下图所示,如果不持久化RDD data,那么求和和求均值时都会对data进行计算,
而持久化RDD后,只有在输出求和结果时会计算data,求均值时是直接从内存中读取数据的。

数据分区
Spark RDD是多个分区组成的数据集合,在分布式程序中,通信的代价是很大的,因此控制数据分区、减少网络传输是提高整体性能的一个重要的方面。
只有键值对类型的RDD才能设置分区方式,非键值对类型的RDD分区的值是None。系统是根据一个针对键的函数对元素进行分区的,虽然不能控制每个键具体划分到哪个节点,但是可以控制相同的键落在同一个分区。
每个RDD的分区ID范围是0~numPartitions-1,决定这个值是属于哪个分区的,numPartitions是分区的个数。
设置分区方式使用的是partitionBy()方法,需要传递一种分区方式作为参数
要获取RDD的分区方式,可以使用RDD的partitioner方法


自定义一个分区器 MyPartition,要求根据键的奇偶性将数据分布在两个分区中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号