
理解Python中进程和线程模块
工作上刚好遇到需要用多进程方法提高程序运行效率的问题,梳理一下如何使用Python中线程(threading),子进程(subprocess)和多进程(multiprocessing)模块来实现并发/并行操作,提高代码效率。本文重在比较各模块的适用场景,每个模块的用法只做简单概述。
1,线程和进程的区别是什么?
简言之,一个任务就是一个进程,而线程是任务中最小执行单元。多个线程可以存在于同一个进程之中,同一个进程里的线程之间共享同一块内存区域(这意味着不同线程可能会读写同一个变量,线程彼此干扰)。进程不共享内存,进程间的交互需要通过其他方式(如files,pipes 或 sockets)。

多线程编程的优点在于线程创建和管理比进程更快,线程内通信速度也更快,线程的缺点在于线程有相互干扰风险,需要保证共享数据有序地修改,编程难度更大。
2, Python GIL全局解释器锁概述
GIL全称Global Interpreter Lock,中文名:全局解释器锁。python代码的执行由python主解释器(最常见的为CPython)来控制。GIL控制着python解释器的访问权限,从而保证同一时刻只有一个线程在运行。
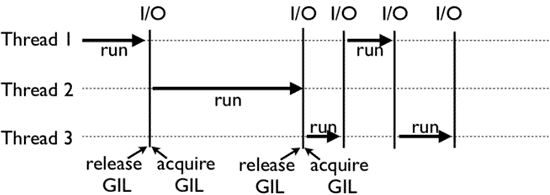
每个线程执行前需先获取GIL,在跑多线程的情况下,始终只有一个线程在CPU上运行。因此Python通常只能发挥单核的功能,程序效率并不高。
3,多进程mutilprocessing
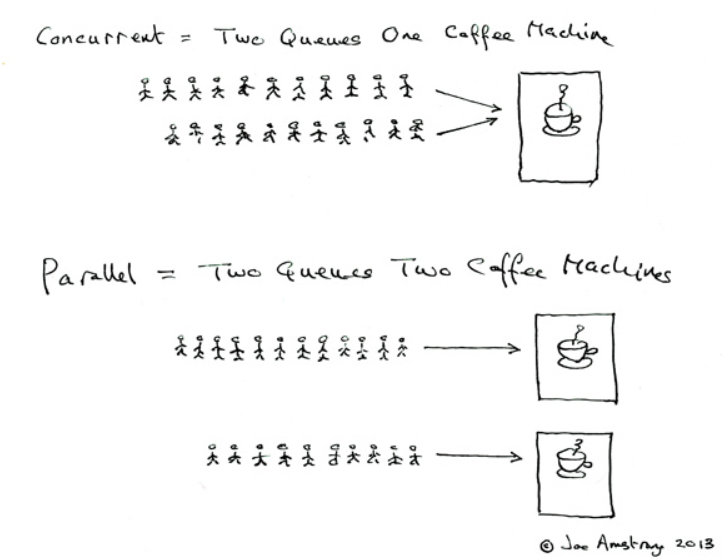
mutilprocessing包支持在python程序中启动新的进程,很大程度上可以弥补因GIL导致的程序低效,因为每个进程使用独立的GIL,在多核CPU上可以并行多个进程。
最基础的用法是通过multiprocessing.Process对象创建一个新进程:
P = multiprocessing.Process( target=None, args=()) #创建进程,target参数传入可调用的函数,通过args为该函数传参
P.start() #启动进程
P.join() #等待进程结束
如果需要创建多个子进程,可以采用进程池,Pool返回的是进程的集合,适合对进程进行批量处理:
pl=multiprocessing.Pool(processes=None) #创建进程池,processes为进程数量,如果为None,则使用os.cpu_count()返回值
pl.apply_async(func, args=(),callback=None) #单独地执行子进程func,执行完后调用callback
pl.map(func, iterable) #批量执行子进程func
pl.close() #关闭进程池,关闭后不能往pool中增加新的子进程
pl.join() #等待进程池中的子进程执行完毕,需在close()后调用
如果多进程间需要数据通信,我们可以用multiprocessing.Manager:
manager= multiprocessing.Manager() #创建共享数据对象
m_list=manager.list() #设置列表共享对象
m_dict=manager.dict() #设置字典共享对象
4, 子进程库subprocess
同样是关于创建子进程的模块,subprocess和multiprocessing的区别在于,前者更适用执行外部的程序或命令行(multiprocessing其实也能调用外部程序,只是由于机制不同,会比subprocess更占用资源),后者更适合调用当前文件内的某个函数作为子进程。
subprocess模块中进程的创建与管理是通过Popen类来实现:
P = subprocess.Popen(args) #启动子进程,args表示要执行的命令
P.wait() #等待子进程结束
基于Popen的封装subprocess里还提供了其他创建子进程的方法,如subprocess.run()用法和直接Popen差不多,主要区别在于无需用wait()来等待子进程完成。此外Popen支持的参数更多,以满足各种复杂的子进程使用场景。
5,线程库Threading
什么场景应该使用多线程,什么场景更适合多进程?如果你的程序需要长时间等待数据传输,适用多线程。如果你的程序时间开销主要用于CPU计算,则适合多进程。因为采用了相似的应用程序接口,线程的构造和使用的语法和multiprocessing中的进程非常相似:
t= Thread( target=None, args=()) #创建线程,target参数定义线程调用的函数,通过args为该函数传参
t.start() #启动线程
t.join() #等待线程结束
为了操作同一块内存中的资源不产生冲突,线程模块中还提供了锁Rlock:
lock = threading.RLock()
lock.acquire() #获得锁。线程进入同步阻塞状态
#中间可以进行数据操作
lock.release() #释放锁
6,总结
多进程模块很好地补偿了Python中GIL机制对程序性能的限制,可以让我们充分使用多核CPU资源;多线程模块适用于优化需要长时间数据传输/文件读写的程序(如爬虫)。合理使用上述方法可以帮助我们写出更高效的程序。
*代码环境为Win10上的Python3.7.4

