痞子衡嵌入式:串行NOR Flash的页编程模式对于量产效率的影响
大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家分享的是串行NOR Flash的页编程模式对于量产效率的影响。
任何嵌入式产品最终都绕不开量产效率话题,尤其是对于主控是非内置 Flash 型 MCU(比如恩智浦的 i.MXRT 系列、意法半导体的 H7 系列等),单片量产时间直接决定了工厂生产效率,对于那种百万级出货量的消费类产品,任何关于量产时间的重大优化都能带来明显受益(据说产线都是按分钟来计费的)。
目前市面上的量产方案主要如下三类,其中方案二是最通用灵活的方式,因为其下载算法可由用户自由调整,所以这种量产方案下产品最终 Flash 型号选择上相对不受限。
- 方案一:利用专门的编程器直接对 Flash 进行离线烧录,不需要连接目标 MCU;
- 方案二:利用通用的调试器连接目标 MCU 板卡对 Flash 进行在线烧录;
- 方案三:利用目标 MCU 里的厂商/自定义 Bootloader 对 Flash 进行在线烧录;
说到下载算法设计,就离不开 Flash 擦写命令模式,其中写命令是 Page Program(页编程),即一次性写入一个 Page 大小的数据块到 Flash 中。我们知道关于 Flash 读命令有非常多的模式(Single, Dual, Quad, Octal, SPI/QPI, SDR/DTR等),而对于 Flash 写命令,从手册里看模式寥寥无几,为什么写命令模式这么少?不同写命令模式有何区别?痞子衡今天从其对量产时间/效率的影响角度跟大家聊一聊:
一、量产过程中时间组成
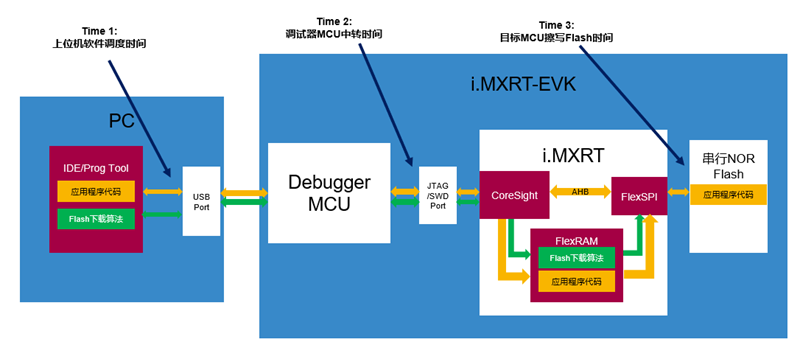
下图是咱们前面提到的量产方案二的功能示意简图,这里目标 MCU 是以恩智浦 i.MXRT 系列来示例的,调试器就以 Segger J-Link 为例,上位机量产软件即 Segger J-Flash。量产时间一共由三部分时间共同决定:
- 时间一:上位机软件 J-Flash 调度时间(将用户程序二进制文件分包通过 USB 口发送给调试器硬件,并与调试器实时交互);
- 时间二:硬件调试器 J-Link 中转时间(调试器从 USB 口收到上位机传来的一包包用户程序数据后,通过 SWD/JTAG 口转存到目标 MCU - i.MXRT 的内部 RAM 中);
- 时间三:目标 MCU - i.MXRT 执行下载算法时间(执行下载算法中的擦写函数,将 RAM 中缓存的用户程序数据写入 Flash 中);
最终量产总时间并不是简单的三部分时间之和,这三部分时间之间实际上是互有交叠的,简单地说,量产过程是以流水线方式进行的。时间一、二主要取决于 Segger 的设计,我们轻易无法改动,而时间三是我们可以量化和分析改进的地方,本文要讨论的也是这个时间三。
二、Flash页编程模式
常用的 NOR Flash 一共有三类:QSPI、OctalFlash、HyperFlash,这三类 Flash 关于 Page Program 模式设计本质上都一样(Hyper Flash目前一线写模式暂时还不支持),我们就以最常见的 QSPI 为例来介绍。下图是典型的 QSPI Flash IS25WP064A 支持的全部三种写模式:Single SPI Page Program(命令地址数据全在 IO0 上传输),Quad Input Page Program(命令地址在 IO0 上传输,数据在 IO[x:0] 上传输)、QPI Page Program(命令地址数据全在 IO[x:0] 上传输)。
- 注:四线 Flash,QPI 模式是传输效率最高的模式,八线 Flash,OPI 模式是传输效率最高的模式。
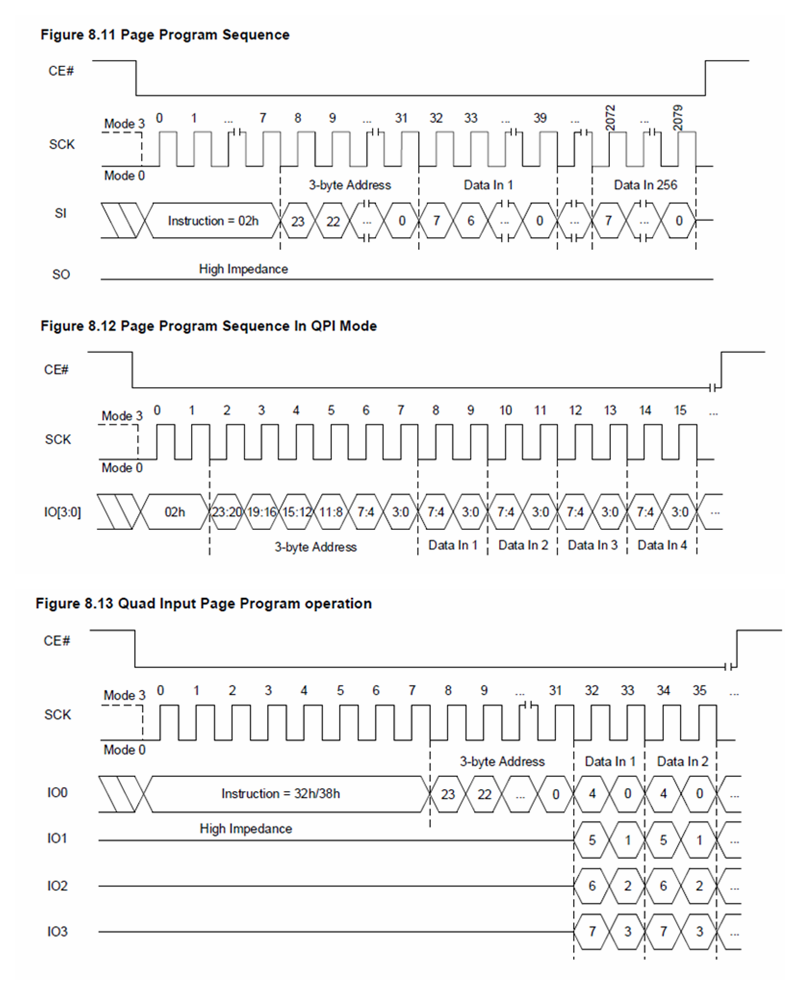
单从页数据传输的角度而言,QPI Page Program 效率最高,Single SPI Page Program 效率最低,相同 Flash 工作频率下,前者所花时间仅后者的 1/4(如果是Octal/Hyper Flash,则是 1/8)。按道理在量产过程中应尽可能选择 QPI/OPI 模式并以最高 Flash 工作频率去做 Page Program,但实际量产过程中往往是 Single SPI 模式且较低 Flash 工作频率去 Page Program 用得更多,这是为什么?继续往下看。
三、不同类型Flash量产时间分析
带着上一节留下的疑问,我们从几个实际 Flash 型号入手,根据手册里给的 AC 特性数据来量化分析下 Flash 量产时间,擦写等待时间均选用典型值,然后分别以 50MHz Single SPI 模式 和 最高频率 QPI/OPI 模式 Page Program 来看两者带来的差异有多大。
3.1 四线QSPI Flash
首先出场的是来自芯成的 IS25WP064A,这是一颗最高工作频率为 133MHz,页大小是 256Bytes,总存储空间大小是 8MB 的 Flash。
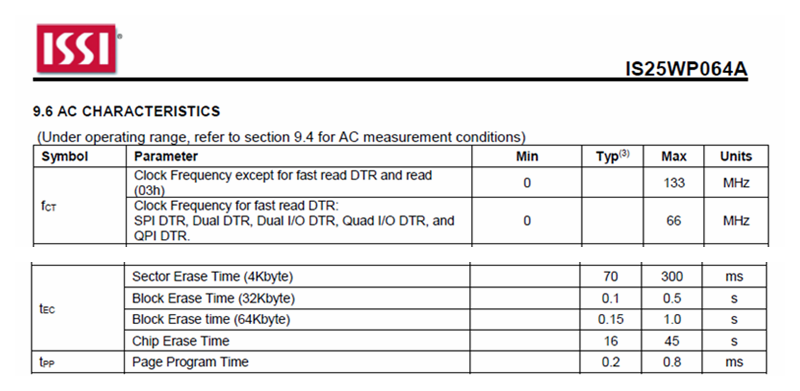
- 50MHz Single SPI SDR 模式下单页数据传输时间 = (8bit + 24bit + 256 * 8bit) / 50Mbps = 41.6us
- 133MHz QPI SDR 模式下单页数据传输时间 = (8bit + 24bit + 256 * 8bit) / 4 / 133Mbps = 3.91us
| 程序长度 | 数据传输时间 | Program总等待时间 | Erase总等待时间 | 量产总时间T3 | ||
|---|---|---|---|---|---|---|
| 50MHz Single SPI SDR | 133MHz QPI SDR | 50MHz Single SPI SDR | 133MHz QPI SDR | |||
| 4KB | 665.6us | 62.556us | 0.2ms * 16 = 3.2ms | 70ms * 1 = 70ms | 73.8656ms | 73.262556ms |
| 4MB | 681.574ms | 64.058ms | 0.2ms * 16384 = 3.2768s | 0.1s * 128 = 12.8s | 16.758374s | 16.140858s |
| 4MB | 681.574ms | 64.058ms | 0.2ms * 16384 = 3.2768s | 0.15s * 64 = 9.6s | 13.558374s | 12.940858s |
| 8MB | 1.36315s | 128.115ms | 0.2ms * 32768 = 6.5536s | 16s | 23.91675s | 22.681715s |
3.2 八线Octal Flash
其次出场的是来自旺宏的 MX25UM51345G,这是一颗最高工作频率为 200MHz,页大小是 256Bytes,总存储空间大小是 64MB 的 Flash。
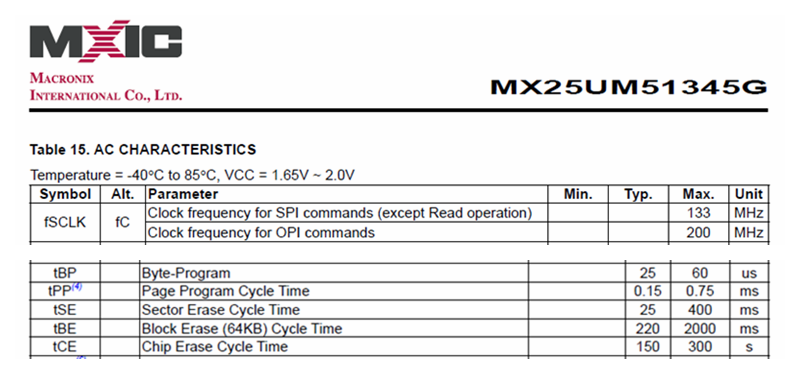
- 50MHz Single SPI SDR 模式下单页数据传输时间 = (8bit + 32bit + 256 * 8bit) / 50Mbps = 41.76us
- 200MHz OPI SDR 模式下单页数据传输时间 = (16bit + 32bit + 256 * 8bit) / 8 / 200Mbps = 1.31us
| 程序长度 | 数据传输时间 | Program总等待时间 | Erase总等待时间 | 量产总时间T3 | ||
|---|---|---|---|---|---|---|
| 50MHz Single SPI SDR | 200MHz OPI SDR | 50MHz Single SPI SDR | 200MHz OPI SDR | |||
| 4KB | 668.16us | 20.96us | 0.15ms * 16 = 2.4ms | 25ms * 1 = 25ms | 28.06816ms | 27.42096ms |
| 32MB | 5.4736s | 0.171704s | 0.15ms * 131072 = 19.6608s | 0.22s * 512 = 112.64s | 137.7744s | 132.472504s |
| 64MB | 10.9471s | 0.343409s | 0.15ms * 262144 = 39.3216s | 150s | 200.2687s | 189.665009s |
3.3 八线Hyper Flash
最后出场的是来自赛普拉斯的 S26KS512S,这是一颗最高工作频率为 166MHz,页大小是 512Bytes,总存储空间大小是 64MB 的 Flash(这是第一代Hyper Flash,不支持一线写模式,据说后面新一代会支持)。
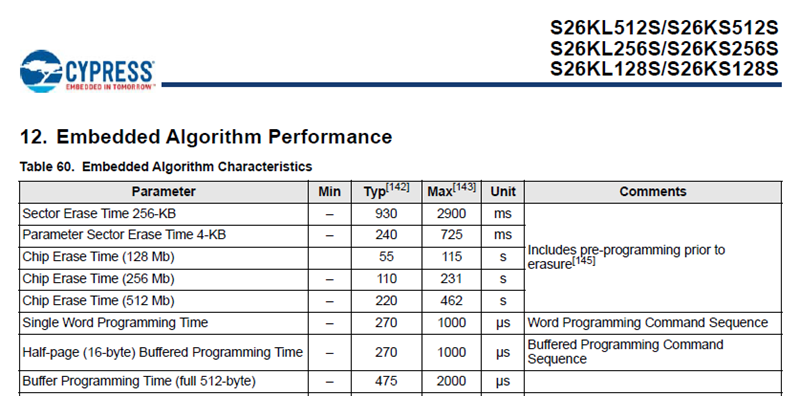
- 50MHz DTR 模式下单页数据传输时间 = (64bit * 4 + 256 * 64bit + 64bit) / 8 / 2 / 50Mbps = 20.88us
- 166MHz DTR模式下单页数据传输时间 = (64bit * 4 + 256 * 64bit + 64bit) / 8 / 2 / 166Mbps = 6.289us
| 程序长度 | 数据传输时间 | Program总等待时间 | Erase总等待时间 | 量产总时间T3 | ||
|---|---|---|---|---|---|---|
| 50MHz DTR | 166MHz DTR | 50MHz DTR | 166MHz DTR | |||
| 256KB | 10.691ms | 3.22ms | 0.475ms * 512 = 0.2432s | 0.93s * 1 = 0.93s | 1.18389s | 1.17642s |
| 32MB | 1.3684s | 0.412166s | 0.475ms * 65536 = 31.1296s | 0.93s * 128 = 119.04s | 151.538s | 150.582s |
| 64MB | 2.7368s | 0.824332s | 0.475ms * 131072 = 62.2592s | 220s | 284.996s | 283.084s |
从上面的量化结果来看,因为擦除和写入等待时间较长,相比较下单纯数据传输时间在总量产时间 T3 里占比太小,因此 Single SPI 模式相比 QPI/OPI 模式的 Page Program 并没有显出多大劣势。那么低速 Single SPI 模式 Page Program 好处体现在哪呢?我们知道影响 Flash 器件最大的因素是擦写次数(寿命),低速 Single SPI 模式在数据传输上的抗干扰能力远比高速 QPI/OPI 模式要强,对于 Flash 写入而言,正确性才是最重要的,低速一次写成功比高速下因为发生传输错误而重复去擦写更有利于延长 Flash 使用寿命。
至此,串行NOR Flash的页编程模式对于量产效率的影响痞子衡便介绍完毕了,掌声在哪里~~~
欢迎订阅
文章会同时发布到我的 博客园主页、CSDN主页、知乎主页、微信公众号 平台上。
微信搜索"痞子衡嵌入式"或者扫描下面二维码,就可以在手机上第一时间看了哦。

最后欢迎关注痞子衡个人微信公众号【痞子衡嵌入式】,一个专注嵌入式技术的公众号,跟着痞子衡一起玩转嵌入式。



衡杰(痞子衡),目前就职于恩智浦(NXP)半导体MCU系统应用部门,担任高级嵌入式系统应用工程师。
专栏内所有文章的转载请注明出处:http://www.cnblogs.com/henjay724/
与痞子衡进一步交流或咨询业务合作请发邮件至 hengjie1989@foxmail.com
可以关注痞子衡的Github主页 https://github.com/JayHeng,有很多好玩的嵌入式项目。
关于专栏文章有任何疑问请直接在博客下面留言,痞子衡会及时回复免费(划重点)答疑。
痞子衡邮箱已被私信挤爆,技术问题不推荐私信,坚持私信请先扫码付款(5元起步)再发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号