痞子衡嵌入式:实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形(全加速)
大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家介绍的是实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形。
上一篇文章 《实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形(有预取)》 里痞子衡抓取了Cache关闭但Prefetch开启下的AHB读访问对应的Flash端时序波形图,我们知道了FlexSPI的Prefetch功能确实在一定程度上改善了Flash访问效率,但是AHB RX Buffer最大仅1KB(对i.MXRT1050而言),不可拆分成更小粒度Buffer去缓存不同Flash地址处的数据(对于同一AHB master而言),这样对于代码中多个不同小数据块重复的Flash空间访问,Prefetch机制并没有明显提升访问效率。
针对这种不连续Flash地址空间频繁访问低效情况,ARM Cortex-M7内核给出了解决方案,那就是L1 Cache技术,今天痞子衡就来继续测一测开启L1 Cache下的Flash AHB读访问情形(本文主要针对D-Cache):
一、Cortex-M7的Cache功能
对于Cortex-M系列家族(M0+/M3/M4/M7/M23/M33/M35P/M55)来说,L1 Cache仅在Cortex-M7和Cortex-M55内核上存在,说白了,L1 Cache是专为高性能内核配置的,而目前的i.MXRT1xxx系列微控制器都是基于Cortex-M7内核。
下面是i.MXRT1050的内核系统框图,可以看到它集成了32KB D-Cache,Cache经由AXI64总线连到SIM_M7和SIM_EMS模块,最终转成AHB总线连接到FlexSPI模块,因此对于Flash的AHB读访问是可以受到D-Cache加速的。
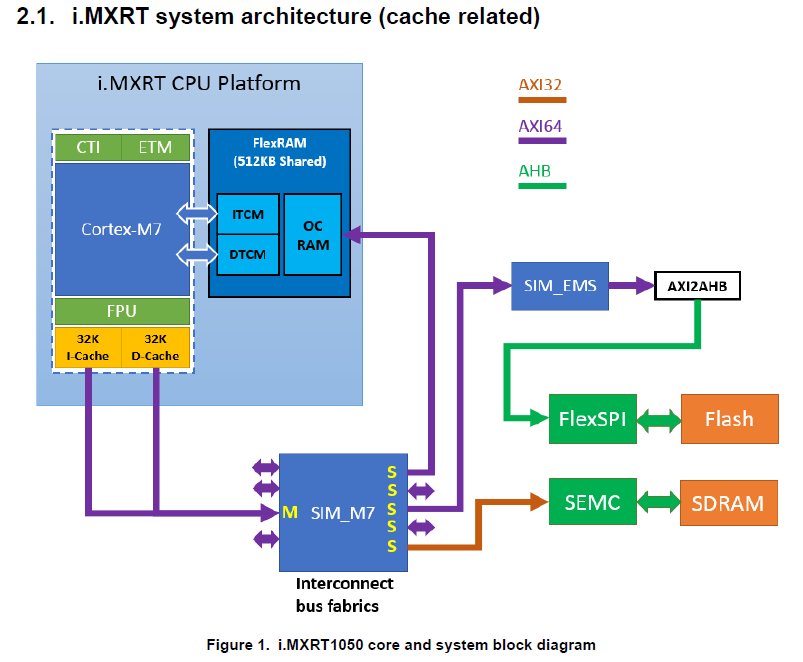
关于D-Cache工作机制,可以在 ARM Cortex-M7 Processor Technical Reference Manual 手册中找到详细解释。简单地概括就是32KB D-Cache会被划分成1024个Cache Line,每个Cache Line大小为32个字节,四个Cache Line是一组(即所谓的4-way set associative),每一组Cache Line会有一个地址标签,地址标签用来记录Cache所缓存的数据所在目标地址信息。
L1 D-Cache使能时,对目标存储器的AHB读访问总共有两大类:Hit(要访问的数据在Cache里面)、Miss(要访问的数据不在Cache里面),Hit没什么好说的,直接从Cache里取数据就行了;Miss后则会先把数据从目标存储器中读到Cache里,然后再从Cache读出数据(这就是所谓的Read-Allocate,实际上有另一个名词Read-Through与之对应,Read-Through即直接从目标存储器中读出数据,一般是Cache不使能时的行为)。
对目标地址空间的Cache策略控制主要是属性配置(在内核MPU模块里)和开关控制(在内核SCB模块里),下面 BOARD_ConfigMPU() 函数即是典型的对FlexSPI地址映射空间所分配的Flash区域的Cache属性配置,这个代码里将0x60000000开始的64MB空间属性配成了Normal Memory,不共享,Cache使能并且写访问行为是Write-Back(写访问还有另一种策略Write-Through),读访问行为不用配置(固定Read-Allocate)。
/* MPU configuration. */
void BOARD_ConfigMPU(void)
{
/* Disable I cache and D cache */
SCB_DisableICache();
SCB_DisableDCache();
/* Disable MPU */
ARM_MPU_Disable();
/* Region 0 setting: Instruction access disabled, No data access permission. */
MPU->RBAR = ARM_MPU_RBAR(0, 0x00000000U);
MPU->RASR = ARM_MPU_RASR(1, ARM_MPU_AP_NONE, 2, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_4GB);
/* Region 2 setting: Memory with Device type, not shareable, non-cacheable. */
MPU->RBAR = ARM_MPU_RBAR(2, 0x60000000U);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 2, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_512MB);
#if defined(XIP_EXTERNAL_FLASH) && (XIP_EXTERNAL_FLASH == 1)
/* Region 3 setting: Memory with Normal type, not shareable, cacheable, outer/inner write back. */
MPU->RBAR = ARM_MPU_RBAR(3, 0x60000000U);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_RO, 0, 0, 1, 1, 0, ARM_MPU_REGION_SIZE_64MB);
#endif
/* Enable MPU */
ARM_MPU_Enable(MPU_CTRL_PRIVDEFENA_Msk);
/* Enable I cache and D cache */
SCB_EnableDCache();
SCB_EnableICache();
}
最后再提一下跟本文主题不相干的Cache使能下写访问行为策略:
- (Hit情形下)Write-Through模式: 直接写到目标存储器中并且也在Cache里更新(无多Master访问造成的数据一致性问题,但没有提升写访问性能)
- (Hit情形下)Write-Back模式: Cache line会被标为dirty,等到此行被invalidate时,才会执行实际的写操作,将Cache Line里面的数据写到目标存储器。(提升了写访问性能,但有隐患,如果 Cache 命中,此时仅 Cache 更新了,目标存储器没有更新,其他Master从目标存储器里面读出来的数据是错误的)
- (Miss情形下)Write-Allocate: 先把要写的数据载入到Cache,然后再flush进目标存储器。
- (Miss情形下)no-Write-Allocate: 直接写入目标存储器。
二、D-Cache实验准备
参考文章 《实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形(无缓存)》 里的第一小节 实验准备,本次实验需要做一样的准备工作。
三、D-Cache实验代码
参考文章 《实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形(无缓存)》 里的第二小节 实验代码,本次实验代码关于工程和链接文件方面是一样的设置,但是具体测试函数改成如下ramfunc型函数 test_cacheable_read()。关于D-Cache这次会有很多种不同测试,while(1)语句前的系统配置保持不变,while(1)里面的语句可根据实际测试情况去调整:
#if (defined(__ICCARM__))
#pragma optimize = none
__ramfunc
#endif
void test_cacheable_read(void)
{
// 系统配置
/* Disable L1 I-Cache*/
SCB_DisableICache();
/* Enable L1 D-Cache*/
SCB_EnableDCache();
SCB_CleanInvalidateDCache();
// 根据测试需求,开/关FlexSPI的Prefetch特性
while (1)
{
// 测试用例代码,可按情况调整
}
}
为了便于分辨IO[1:0]上的数据去帮助分析本系列测试用例结果,我们需要拓展下特殊const数据区.ahbRdBuffer设置如下:
const uint8_t ahbRdBlock1[1024] @ ".ahbRdBuffer1" = {
// 正顺序
0x00, 0x01, 0x02, 0x03, 0x10, 0x11, 0x12, 0x13,
0x20, 0x21, 0x22, 0x23, 0x30, 0x31, 0x32, 0x33,
// 倒顺序
0x33, 0x32, 0x31, 0x30, 0x23, 0x22, 0x21, 0x20,
0x13, 0x12, 0x11, 0x10, 0x03, 0x02, 0x01, 0x00,
// 正插序
0x01, 0x00, 0x03, 0x02, 0x11, 0x10, 0x13, 0x12,
0x21, 0x20, 0x23, 0x22, 0x31, 0x30, 0x33, 0x32,
// 倒插序
0x32, 0x33, 0x30, 0x31, 0x22, 0x23, 0x20, 0x21,
0x12, 0x13, 0x10, 0x11, 0x02, 0x03, 0x00, 0x01,
};
const uint8_t ahbRdBlock2[1024] @ ".ahbRdBuffer2" = {
// 倒插序
0x32, 0x33, 0x30, 0x31, 0x22, 0x23, 0x20, 0x21,
0x12, 0x13, 0x10, 0x11, 0x02, 0x03, 0x00, 0x01,
// 正插序
0x01, 0x00, 0x03, 0x02, 0x11, 0x10, 0x13, 0x12,
0x21, 0x20, 0x23, 0x22, 0x31, 0x30, 0x33, 0x32,
// 倒顺序
0x33, 0x32, 0x31, 0x30, 0x23, 0x22, 0x21, 0x20,
0x13, 0x12, 0x11, 0x10, 0x03, 0x02, 0x01, 0x00,
// 正顺序
0x00, 0x01, 0x02, 0x03, 0x10, 0x11, 0x12, 0x13,
0x20, 0x21, 0x22, 0x23, 0x30, 0x31, 0x32, 0x33,
};
// 在工程链接文件中
keep{ section .ahbRdBuffer1, section .ahbRdBuffer2 };
place at address mem:0x60002400 { readonly section .ahbRdBuffer1 };
place at address mem:0x60002800 { readonly section .ahbRdBuffer2 };
四、D-Cache实验结果
4.1 重做无缓存一文中的实验
现在让我们在开启D-Cache的情况下重新做文章 《实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形(无缓存)》 中全部实验:
#define AHB_ADDR_START (0x60002400)
void test_cacheable_read(void)
{
// 略去系统配置(I-Cache、Prefetch关闭,D-Cache开启)
while (1)
{
SDK_DelayAtLeastUs(10, SystemCoreClock);
for (uint32_t i = 1; i <= 8; i++)
{
SDK_DelayAtLeastUs(2, SystemCoreClock);
memcpy((void *)0x20200000, (void *)AHB_ADDR_START, i);
}
}
}
4.1.1 AHB_ADDR_START 取值 [0x60002400 - 0x60002418]
当 AHB_ADDR_START 取值范围在 [0x60002400 - 0x60002418] 中时,Flash端的时序波形图都是如下同一个。因为有了D-Cache,现在我们看不到周期性的CS信号了,说明除了Flash新地址访问是必须要通过FlexSPI外设去读取Flash之外,其后的同一Flash地址的重复访问都直接发生在D-Cache里了。
另外D-Cache起始缓存地址永远是32字节对齐的地址处,并且一次缓存32byte的数据(因为D-Cache Line大小就是32byte),所以波形结果里看,起始地址都是0x60002400,一次读取32byte数据(存在一个D-Cache Line里),因此之前不开D-Cache和Prefetch下的AHB Burst Read策略导致的访问不同对齐地址的波形差异测试结果在这里就不存在了。

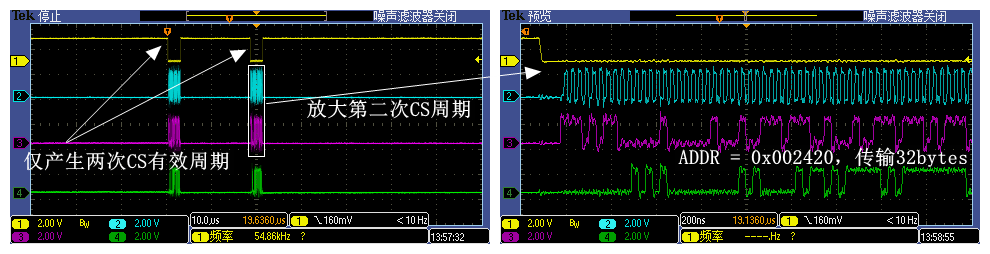
4.1.2 AHB_ADDR_START = 0x60002419
当实际代码中要读取的Flash数据会横跨两个相邻32字节对齐的数据块(0x60002400 - 0x6000241f, 0x60002420 - 0x6000243f),此时Flash端会出现两次CS有效信号,每次均传输32byte数据,D-Cache一直在持续作用,这次动用了两个D-Cache Line(D-Cache总大小有32KB,共有1024个Cache Line),因此在Flash端我们还是看不到周期性CS信号。
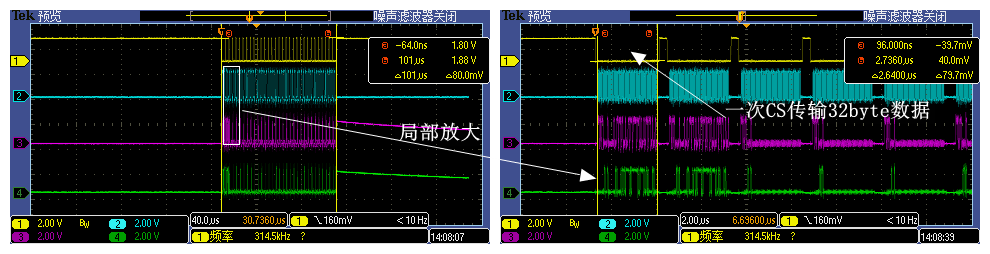
4.1.3 追加实验,从0x60002400处读取1KB
当代码循环读取1KB数据时,波形图上可以看到32个CS有效信号,每个CS有效期间传输32byte数据,总计1KB数据的传输,D-Cache这次派出了32个 Cache Line,在Flash端我们依然看不到周期性CS信号。
4.2 重做有预取一文中的实验
现在让我们在开启D-Cache的情况下重新做文章 《实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形(有预取)》 中全部实验:
4.2.1 循环读取首地址32字节对齐的1KB空间内的任意长度数据块,起始拷贝地址位于前31个字节内
这种情况下,Flash端实际波形与 《实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形(有预取)》 中 4.1 里的测试结果差不多,这里就不再贴图了。Prefetch机制做第一层缓存,D-Cache获取Prefetch Buffer里的结果做二次缓存,唯一的差异是因为D-Cache的存在,缓存起始地址可能会发生变化(从八字节对齐变成了32字节对齐):
#define PREFETCH_TEST_ALIGNMENT (7) // 可取值 0 - 31
#define PREFETCH_TEST_START (0x60002400 + PREFETCH_TEST_ALIGNMENT)
uint32_t testLen = 0x1; // 可取值 1 - (1KB-PREFETCH_TEST_ALIGNMENT)
void test_cacheable_read(void)
{
// 略去系统配置(I-Cache关闭,Prefetch开启,D-Cache开启)
while (1)
{
memcpy((void *)0x20200000, (void *)PREFETCH_TEST_START, testLen);
}
}
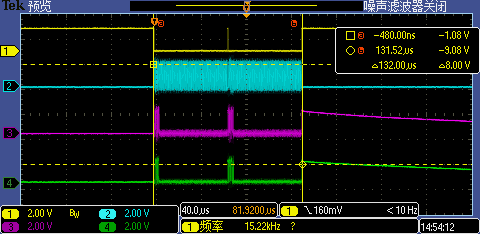
4.2.2 循环读取大于1KB的数据块或首地址非32字节对齐的1KB数据块
这种情况下,Flash端会有两次完整的1KB Prefetch操作,第一次Prefetch操作读取了0x60002400处的1KB,第二次Prefetch操作读取了0x60002800处的1KB。因为有D-Cache的存在,第二次Prefetch操作有了足够时间去完成,不用额外插入软延时去避免其被while(1)循环回来的下一次访问需求打断了:
void test_cacheable_read(void)
{
// 略去系统配置(I-Cache关闭,Prefetch开启,D-Cache开启)
while (1)
{
memcpy((void *)0x20200001, (void *)0x60002401, 0x400);
}
}
4.2.3 循环读取两个不同数据块(在首地址32字节对齐的两个不同1KB空间内)
这种情况下,即使有D-Cache存在,第一次CS期间的Prefetch操作(即memcpy((void *)0x20200000, (void *)0x60002400, 0x100);引发的)还是被第二次CS的Prefetch操作打断了(即memcpy((void *)0x20200400, (void *)0x60002800, 0x100);),但是第二次CS期间的Prefetch操作不会再被打断,因为接下来while(1)循环回来的Flash数据访问需求已经缓存在D-Cache里:
void test_cacheable_read(void)
{
// 略去系统配置(I-Cache关闭,Prefetch开启,D-Cache开启)
while (1)
{
memcpy((void *)0x20200000, (void *)0x60002400, 0x100);
memcpy((void *)0x20200400, (void *)0x60002800, 0x100);
}
}
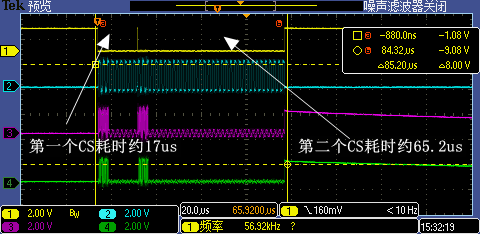
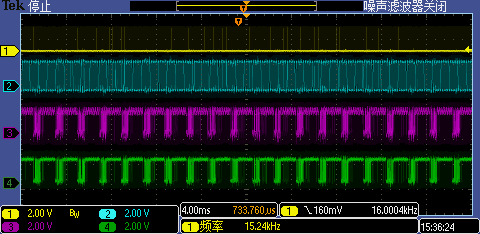
4.3 如何在D-Cache使能的情况下看到周期性CS信号
前面测试了那么多种情况,我们有没有可能在Flash端看到周期性CS信号呢,即Flash持续地被读取呢?当然可以,我们知道D-Cache总大小是32KB,我们只要循环拷贝32KB以上数据,D-Cache就开始hold不住了,这不,下面代码就能让我们看到久违的周期时序波形图了(小心,Flash持续工作会多耗电的,哈哈)。
void test_cacheable_read(void)
{
// 略去系统配置(I-Cache关闭,Prefetch开启,D-Cache开启)
while (1)
{
memcpy((void *)0x20200000, (void *)0x60002400, 0x8000 + 1);
}
}
至此,实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形痞子衡便介绍完毕了,掌声在哪里~~~
欢迎订阅
文章会同时发布到我的 博客园主页、CSDN主页、知乎主页、微信公众号 平台上。
微信搜索"痞子衡嵌入式"或者扫描下面二维码,就可以在手机上第一时间看了哦。

最后欢迎关注痞子衡个人微信公众号【痞子衡嵌入式】,一个专注嵌入式技术的公众号,跟着痞子衡一起玩转嵌入式。



衡杰(痞子衡),目前就职于恩智浦(NXP)半导体MCU系统应用部门,担任高级嵌入式系统应用工程师。
专栏内所有文章的转载请注明出处:http://www.cnblogs.com/henjay724/
与痞子衡进一步交流或咨询业务合作请发邮件至 hengjie1989@foxmail.com
可以关注痞子衡的Github主页 https://github.com/JayHeng,有很多好玩的嵌入式项目。
关于专栏文章有任何疑问请直接在博客下面留言,痞子衡会及时回复免费(划重点)答疑。
痞子衡邮箱已被私信挤爆,技术问题不推荐私信,坚持私信请先扫码付款(5元起步)再发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号