痞子衡嵌入式:实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形(无缓存)
大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家介绍的是实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形。
上一篇文章 《i.MXRT中FlexSPI外设对AHB Burst Read特性的支持》 里痞子衡介绍了FlexSPI外设在不开启Prefetch功能下响应AHB master的访问请求完全受AHB总线Burst Read特性决定,这是FlexSPI外设最基础的对Flash访问支持功能,研究这个其实是很有意义的,这可以反映出XiP下最原始的代码执行效率。
我们知道在实际项目中,XiP应用程序常常是在L1 Cache和Prefetch加持下运行的,代码执行效率会得到大大提升,但无论是怎样的缓存策略,极限情况下(比如大数据块搬移,长跳转指令)最终还是拼得FlexSPI最基础的读访问支持。今天痞子衡就从抓Flash信号波形角度带大家真切感受下这最基础的AHB读访问情形(为更清晰地分析结果,本次主要涉及数据总线AHB访问,暂不涉及指令总线AHB访问):
一、实验准备
痞子衡用i.MXRT1050-EVKB来做这个AHB读访问实验,这块板子上的Flash被痞子衡更换过,目前的型号是华邦W25Q64JWS-IQ。我们基于 \SDK_2.9.1_EVKB-IMXRT1050\boards\evkbimxrt1050\demo_apps\led_blinky\iar 例程(记得切换到 flexspi_nor_debug build)来简单修改一下,把启动头FDCB修改如下,设置Flash工作于30MHz Fast Read Quad I/O SDR模式,调成30MHz低速是为了方便后续用示波器抓Flash信号去分析。
const flexspi_nor_config_t qspiflash_config = {
.memConfig =
{
.tag = FLEXSPI_CFG_BLK_TAG,
.version = FLEXSPI_CFG_BLK_VERSION,
.readSampleClkSrc = kFlexSPIReadSampleClk_LoopbackFromDqsPad,
.csHoldTime = 3u,
.csSetupTime = 3u,
.controllerMiscOption = 0x10,
.deviceType = kFlexSpiDeviceType_SerialNOR,
.sflashPadType = kSerialFlash_4Pads,
// Flash工作于30MHz
.serialClkFreq = kFlexSpiSerialClk_30MHz,
.sflashA1Size = 8u * 1024u * 1024u,
.lookupTable =
{
// Quad I/O Fast Read SDR LUTs
[4*CMD_LUT_SEQ_IDX_READ + 0] = FLEXSPI_LUT_SEQ(CMD_SDR, FLEXSPI_1PAD, 0xEB, RADDR_SDR, FLEXSPI_4PAD, 0x18),
[4*CMD_LUT_SEQ_IDX_READ + 1] = FLEXSPI_LUT_SEQ(MODE8_SDR, FLEXSPI_4PAD, 0xF0, DUMMY_SDR, FLEXSPI_4PAD, 0x04),
[4*CMD_LUT_SEQ_IDX_READ + 2] = FLEXSPI_LUT_SEQ(READ_SDR, FLEXSPI_4PAD, 0x04, STOP, FLEXSPI_1PAD, 0x00),
[4*CMD_LUT_SEQ_IDX_READ + 3] = 0,
},
},
.pageSize = 256u,
.sectorSize = 4u * 1024u,
.blockSize = 64u * 1024u,
.isUniformBlockSize = false,
};
下图是华邦W25Q64JWS-IQ芯片的Fast Read Quad I/O SDR传输时序图,Dummy Cycle连同MODE8_SDR序列一共6个SCK周期,此外还有个特别注意点,MODE8_SDR序列参数值需要被设成0xFx,我们上面修改的FDCB启动头是符合要求的。
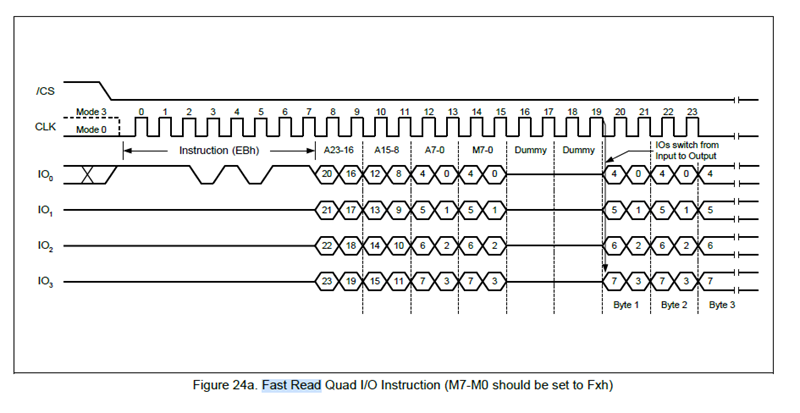
现在让我们把示波器拿出来,四路探头分别连到板载Flash器件的CE#、SCK、SI_IO0、SO_IO1引脚(IO2、IO3因探头有限就不抓取了,IO[1:0]足够我们分析时序了),然后将 led_blinky 工程下载进Flash运行便可以观测结果了。

二、实验代码
因为我们下载的是一个XIP工程,代码的执行本身也会触发Flash中的指令读取,这会影响我们在示波器上观测AHB读数据测试结果,所以我们可以在main()函数里把SysTick初始化去掉(不要中断),并且调用如下ramfunc型函数 test_ahb_read() 来做测试(痞子衡直接利用了IAR软件的特性),这样代码跑起来后,Flash上发生的读访问均来自我们想要测试的AHB读数据操作(这也意味着ICache是否开启对本系列测试结果没有影响,但不管怎么,我们统一关掉):
Note: DCache和Prefetch必须要全部关闭,否则哪怕测试代码里对同一个地方循环读取,但在Flash引脚上根本看不到周期性信号波形,因为系统做了缓存,后续的读取操作可能直接发生在缓存区里(32KB DCache, 1KB AHB RX prefetch buffer)了。
#define AHB_ADDR_START (0x60002400)
#if (defined(__ICCARM__))
#pragma optimize = none
__ramfunc
#endif
void test_ahb_read(void)
{
/* Disable L1 I-Cache*/
SCB_DisableICache();
/* Disable L1 D-Cache*/
SCB_DisableDCache();
/* Disable FlexSPI AHB read prefetch */
FLEXSPI->AHBCR &= ~(FLEXSPI_AHBCR_PREFETCHEN_MASK | FLEXSPI_AHBCR_CACHABLEEN_MASK);
while (1)
{
SDK_DelayAtLeastUs(10, SystemCoreClock);
for (uint32_t i = 1; i <= 8; i++)
{
SDK_DelayAtLeastUs(2, SystemCoreClock);
memcpy((void *)0x20200000, (void *)AHB_ADDR_START, i);
}
}
}
因为我们用了memcpy来做Flash数据拷贝,memcpy功能实际上是IAR软件自带库 ABImemcpy.a 里面的 __aeabi_memcpy、__aeabi_memcpy4、__aeabi_memcpy8 等函数实现的,因此我们还需要在工程链接文件里将 ABImemcpy.o 链接到RAM区;并且我们还用了SDK_DelayAtLeastUs()来分隔每次memcpy()波形结果,还需要将这个函数里调用的相关代码放到RAM区(fsl_common.c里)。
initialize by copy { readwrite,
section .textrw,
// 确保 memcpy() 相关代码全在RAM里
object ABImemcpy.o,
// 确保 SDK_DelayAtLeastUs() 相关代码全在RAM里
object fsl_common.o,
object I64DivZer.o,
object I64DivMod.o
};
do not initialize { section .noinit };
一切准备就绪后具体测试就是设置不同的AHB_ADDR_START值(这里主要是考虑地址对齐)来观测Flash信号的实际波形。此外为了便于分辨IO[1:0]上的数据,我们最好定义一块特殊const数据区,根据Flash传输时序图,其中数据Byte[4]和Byte[0]是在IO0线上传输、Byte[5]和Byte[1]是在IO1线上传输的,这4bit共有16种不同值组合,我们将这16种不同值放在ahbRdBlock[16]数组中,并将其链接在 0x60002400 - 0x6000240f 地址空间里。
// 在工程源文件中
const uint8_t ahbRdBlock[16] @ ".ahbRdBuffer" = {0x00, 0x01, 0x02, 0x03,
0x10, 0x11, 0x12, 0x13,
0x20, 0x21, 0x22, 0x23,
0x30, 0x31, 0x32, 0x33};
// 在工程链接文件中
keep{ section .ahbRdBuffer };
place at address mem:0x60002400 { readonly section .ahbRdBuffer };
三、实验结果
因为既没有Cache,也没有Prefetch,所以用户代码中memcpy语句(哪怕存在循环重复读取)与Flash端实际信号时序波形图几乎是一一对应的,唯一不确定的就是AHB master是如何拆分CS信号周期的。
3.1 AHB_ADDR_START = 0x60002400 即八字节对齐
我们先来看AHB_ADDR_START = 0x60002400时抓取一次完整for循环结果的波形(见下图),可以看到在八字节对齐的地址下使用memcpy拷贝1/2/4/8字节,均仅产生一次CS信号有效周期(拉低),在这CS有效期间完成全部所需数据的读取。但是拷贝3/5/6/7字节时,会拆分出多个CS有效周期。
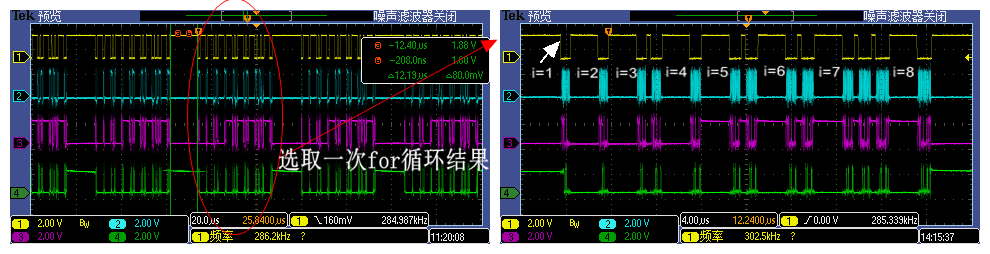
当使用memcpy拷贝3/5/6字节时,会拆分出2个CS有效周期(见下图),这里第一个CS周期看起来似乎是多余的,为什么是这种结果,这需要深入研究AHB机制(痞子衡会另写文章分析);
- 当拷贝3字节时,第一个CS周期实际读取了前2个字节 [0x60002400, 0x60002401],第二个CS周期读取了全部3字节 [0x60002400, 0x60002402]。
- 当拷贝5字节时,第一个CS周期实际读取了前4个字节 [0x60002400, 0x60002403],第二个CS周期读取了全部5字节 [0x60002400, 0x60002404]。
- 当拷贝6字节时,第一个CS周期实际读取了前4个字节 [0x60002400, 0x60002403],第二个CS周期读取了全部6字节 [0x60002400, 0x60002405]。
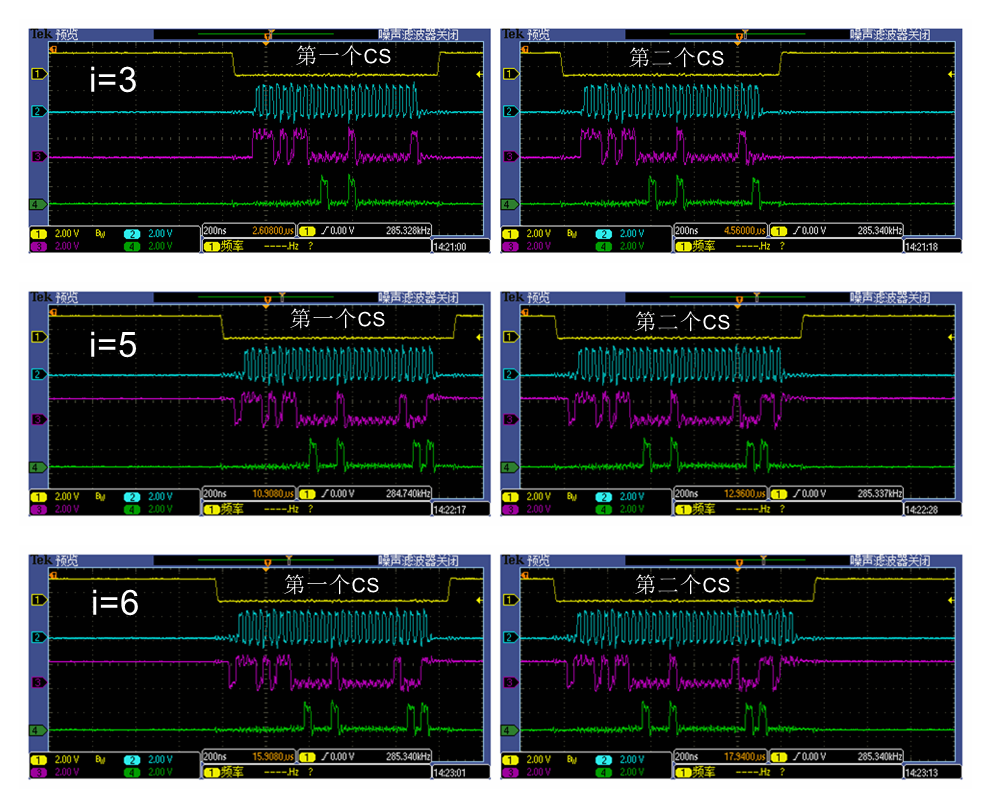
当使用memcpy拷贝7字节时,会拆分出3个CS有效周期(见下图),这里前两个CS周期看起来似乎都是多余的;
- 当拷贝7字节时,第一个CS周期实际读取了前4个字节 [0x60002400, 0x60002403],第二个CS周期实际读取了前6个字节 [0x60002400, 0x60002405],第三个CS周期读取了全部7字节 [0x60002400, 0x60002406]。

3.2 AHB_ADDR_START = 0x60002404 即四字节对齐
AHB_ADDR_START = 0x60002404时抓取一次完整for循环结果的波形(见下图),可以看到在四字节对齐的地址下使用memcpy拷贝1/2/4字节,均仅产生一次CS信号有效周期(拉低),在这CS有效期间完成全部所需数据的读取。
但是拷贝3/5/6/7/8字节时,会拆分出多个CS有效周期。不过其中拷贝5/6/8字节,是合理的拆分,并没有冗余读取。
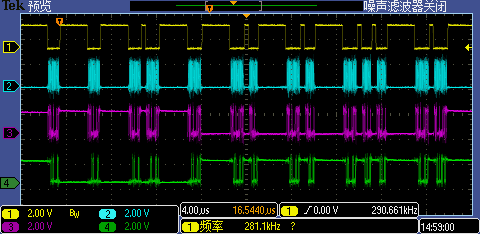
3.3 AHB_ADDR_START = 0x60002401 即奇地址
AHB_ADDR_START = 0x60002401时抓取一次完整for循环结果的波形(见下图),这种情况下CS拆分特别严重,几乎都存在冗余读取。
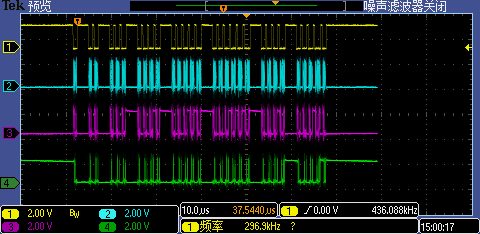
3.4 AHB_ADDR_START = 0x60002402 即偶地址
AHB_ADDR_START = 0x60002402时抓取一次完整for循环结果的波形(见下图),这种情况下CS拆分特别严重,几乎都存在冗余读取。
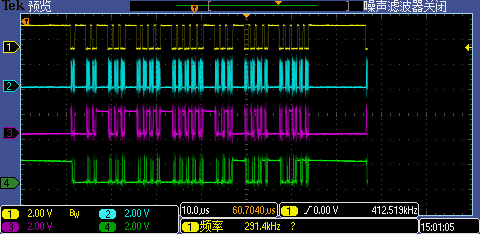
3.5 AHB_ADDR_START = 0x60002403
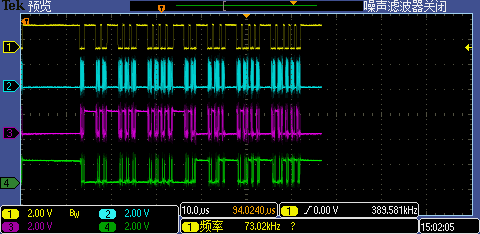
AHB_ADDR_START = 0x60002403时抓取一次完整for循环结果的波形(见下图),这种情况下CS拆分特别严重,几乎都存在冗余读取。
四、追加实验
上一节的实验主要侧重于memcpy拷贝源Flash首地址对齐方式的不同,而拷贝长度最大仅设到8byte,那么如果我们一次拷贝超过8byte会是什么情形呢?痞子衡做了如下实验,这次从0x60002400开始一次拷贝1KB,从结果波形上来看,1KB的数据拷贝被拆分成了128个CS有效周期,每个CS有效期间拷贝8byte。
#if (defined(__ICCARM__))
#pragma optimize = none
__ramfunc
#endif
void test_ahb_read(void)
{
/* Disable L1 I-Cache*/
SCB_DisableICache();
/* Disable L1 D-Cache*/
SCB_DisableDCache();
/* Disable FlexSPI AHB read prefetch */
FLEXSPI->AHBCR &= ~(FLEXSPI_AHBCR_PREFETCHEN_MASK | FLEXSPI_AHBCR_CACHABLEEN_MASK);
while (1)
{
SDK_DelayAtLeastUs(10, SystemCoreClock);
memcpy((void *)0x20200000, (void *)0x60002400, 0x400);
}
}

至此,实抓Flash信号波形来看i.MXRT的FlexSPI外设下AHB读访问情形痞子衡便介绍完毕了,掌声在哪里~~~
欢迎订阅
文章会同时发布到我的 博客园主页、CSDN主页、知乎主页、微信公众号 平台上。
微信搜索"痞子衡嵌入式"或者扫描下面二维码,就可以在手机上第一时间看了哦。

最后欢迎关注痞子衡个人微信公众号【痞子衡嵌入式】,一个专注嵌入式技术的公众号,跟着痞子衡一起玩转嵌入式。



衡杰(痞子衡),目前就职于恩智浦(NXP)半导体MCU系统应用部门,担任高级嵌入式系统应用工程师。
专栏内所有文章的转载请注明出处:http://www.cnblogs.com/henjay724/
与痞子衡进一步交流或咨询业务合作请发邮件至 hengjie1989@foxmail.com
可以关注痞子衡的Github主页 https://github.com/JayHeng,有很多好玩的嵌入式项目。
关于专栏文章有任何疑问请直接在博客下面留言,痞子衡会及时回复免费(划重点)答疑。
痞子衡邮箱已被私信挤爆,技术问题不推荐私信,坚持私信请先扫码付款(5元起步)再发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号