痞子衡嵌入式:链接函数到8字节对齐地址或可进一步提升i.MXRT1xxx内核执行性能
大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家分享的是i.MXRT上进一步提升代码执行性能的经验。
今天跟大家聊的这个话题还是跟痞子衡最近这段时间参与的一个基于i.MXRT1170的大项目有关,痞子衡在做其中的开机动画功能,之前写过一篇文章 《降低刷新率是定位LCD花屏显示问题的第一大法》 介绍了开机动画功能的实现以及LCD显示注意事项,在此功能上,痞子衡想进一步测试从芯片上电到LCD屏显示第一幅完整图像的时间,这个时间我们暂且称为1st UI时间,该时间的长短对项目有重要意义。
痞子衡分别测试了代码在XIP执行下和在TCM里执行下的1st UI时间,得到的结果竟然是XIP执行比TCM执行还要快50ms,这是怎么回事?这完全颠覆了我们的理解,i.MXRT上TCM是与内核同频的,Flash速度远低于TCM。如果是XIP执行,即使有I-Cache加速,也最多与TCM执行一样快,怎么可能做到比TCM执行快这么多。于是痞子衡便开始深挖这个奇怪的现象,然后发现了进一步提升代码执行性能的秘密。
一、引出计时差异问题
痞子衡的开机动画程序是基于 \SDK_2.x.x_MIMXRT1170-EVK\boards\evkmimxrt1170\jpeg_examples\sd_jpeg 例程的,只是去了SD卡和libjpeg库相关代码。工程有两个build,一个是TCM里执行(即debug),另一个是XIP执行(即flexspi_nor_debug)。
项目板上的Flash型号是MX25UW51345G,痞子衡将其配成Octal mode, DDR, 166MHz用于启动。项目板上还有两个LED灯,痞子衡在LED灯上飞了两根线,连同POR引脚一起连上示波器,用于精确测量1st UI各部分时间组成。

示波器通道1连接POR引脚,表明1st UI时间起点;通道2连接LED1 GPIO,表明ROM启动时间(进入用户APP的时间点);通道3连接LED2 GPIO,做两次电平变化,分别是1st图像帧开始和结束的时间点。翻转LED GPIO代码位置如下:
void light_led(uint32_t ledIdx, uint8_t ledVal);
void SystemInit (void) {
// 将LED1置1,标示ROM启动时间
light_led(1, 1);
SCB->CPACR |= ((3UL << 10*2) | (3UL << 11*2));
// ...
}
void APP_InitDisplay(void)
{
// ...
g_dc.ops->enableLayer(&g_dc, 0);
// 将LED2置1,标示1st图像帧开始时间点
light_led(2, 1);
}
int main(void)
{
BOARD_ConfigMPU();
BOARD_InitBootPins();
BOARD_BootClockRUN();
BOARD_ResetDisplayMix();
APP_InitDisplay();
while (1)
{
// ...
}
}
static void APP_BufferSwitchOffCallback(void *param, void *switchOffBuffer)
{
s_newFrameShown = true;
// 将LED2置0,标示1st图像帧结束时间点
light_led(2, 0);
}
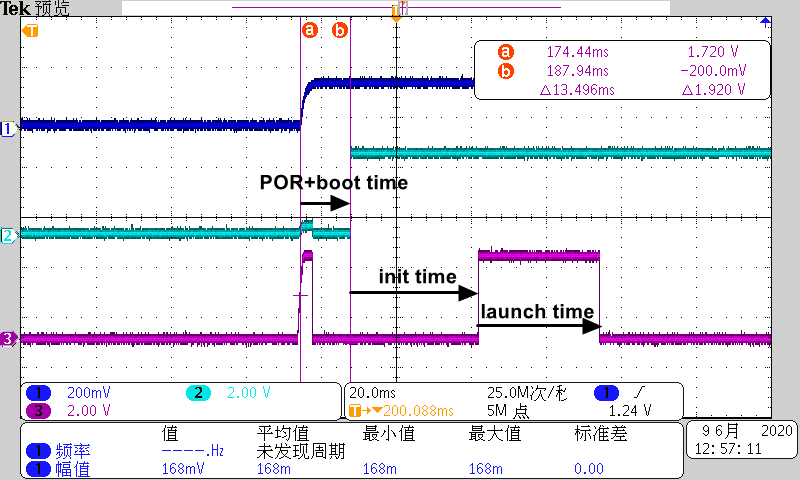
上图是痞子衡抓到的波形(30Hz,XIP),痞子衡一共做了四次测试,分别是30Hz LCD刷新率下的XIP/TCM以及60Hz LCD刷新率下的XIP/TCM,结果如下表所示。表中的Init Time一栏表示的是开机动画程序代码执行时间(从SystemInit()函数开始执行到APP_InitDisplay()函数结束的时间),可以看到TCM执行比XIP执行慢近50ms,这便是奇怪问题所在。
| 代码位置 | LCD刷新率 | POR Time | Boot Time | Init Time | Launch Time |
|---|---|---|---|---|---|
| XIP | 30Hz | 3.414ms | 10.082ms | 34.167ms + 153ms | 32.358ms |
| TCM | 30Hz | 3.414ms | 10.854ms | 33.852ms + 203ms | 32.384ms |
| XIP | 60Hz | 3.414ms | 9.972ms | 18.142ms + 153ms | 16.166ms |
| TCM | 60Hz | 3.414ms | 10.92ms | 17.92ms + 203ms | 16.104ms |
二、定位计时差异问题
对于开机动画代码,XIP执行比TCM执行快这个结果,痞子衡是不相信的,于是痞子衡便用二分法逐步查找,发现时间差异是BOARD_InitLcdPanel()函数里的DelayMs()调用引起的,这些人为插入的延时是LCD屏控制器手册里的要求,总延时时间应该是153ms,但是这个函数的执行在XIP下(153ms)和TCM里(203ms)时间不同。
static void BOARD_InitLcdPanel(void)
{
// ...
#if (DEMO_PANEL == DEMO_PANEL_TM103XDKP13)
// ...
/* Power LCD on */
GPIO_PinWrite(LCD_RESET_GPIO, LCD_RESET_GPIO_PIN, 1);
DelayMs(2);
GPIO_PinWrite(LCD_RESET_GPIO, LCD_RESET_GPIO_PIN, 0);
DelayMs(5);
GPIO_PinWrite(LCD_RESET_GPIO, LCD_RESET_GPIO_PIN, 1);
DelayMs(6);
GPIO_PinWrite(LCD_STBYB_GPIO, LCD_STBYB_GPIO_PIN, 1);
DelayMs(140);
#endif
// ...
}
所以现在的问题就是为何在TCM里执行DelayMs(153)需要203ms,而XIP执行下是精确的。让我们进一步查看DelayMs()函数的原型,这个函数其实调用的是SDK_DelayAtLeastUs()函数,SDK_DelayAtLeastUs()函数从命名上看就很有意思,AtLeast即保证软延时一定能满足用户设置的时间,但也可能超过这个时间。为何是AtLeast设计,其实这里就涉及到Cortex-M7内核一个很重要的特性 - 指令双发射,软件延时的本质是靠CPU执行指令来消耗时间,但是CPU拿指令到底是单发射还是双发射有一定的不确定性,因此无法做到精确,如果以全双发射来计算,就能得出最小延时时间。
#define DelayMs VIDEO_DelayMs
#if defined(__ICCARM__)
static void DelayLoop(uint32_t count)
{
__ASM volatile(" MOV R0, %0" : : "r"(count));
__ASM volatile(
"loop: \n"
" SUBS R0, R0, #1 \n"
" CMP R0, #0 \n"
" BNE loop \n");
}
#endif
void SDK_DelayAtLeastUs(uint32_t delay_us, uint32_t coreClock_Hz)
{
assert(0U != delay_us);
uint64_t count = USEC_TO_COUNT(delay_us, coreClock_Hz);
assert(count <= UINT32_MAX);
#if (__CORTEX_M == 7)
count = count / 3U * 2U;
#else
count = count / 4;
#endif
DelayLoop(count);
}
void VIDEO_DelayMs(uint32_t ms)
{
SDK_DelayAtLeastUs(ms * 1000U, SystemCoreClock);
}
分析到现在,问题已经转化成为何XIP下执行指令双发射概率比TCM里执行指令双发射概率更大,关于这个现象并没有在ARM官方文档里查找到相关信息,DelayLoop()循环里只是3条指令,XIP下执行肯定是在Cache line里,这跟在TCM里执行并没有什么区别。让我们再去看看两个工程的map文件,找到DelayLoop()函数链接地址,这个函数在两个测试工程下链接地址对齐不一样,这意味着测试条件不完全相同,或许这是一个解决问题的线索。
XIP执行工程(flexspi_nor_debug),DelayLoop()函数地址8字节对齐:
*******************************************************************************
*** ENTRY LIST
***
Entry Address Size Type Object
----- ------- ---- ---- ------
DelayLoop 0x3000'3169 0xa Code Lc fsl_common.o [1]
TCM执行工程(debug工程),DelayLoop()函数地址4字节对齐:
*******************************************************************************
*** ENTRY LIST
***
Entry Address Size Type Object
----- ------- ---- ---- ------
DelayLoop 0x314d 0xa Code Lc fsl_common.o [1]
三、找到计时差异本质
前面找到DelayLoop()函数链接地址差异是一个线索,那我们就针对这个线索做测试,不再让链接器自动分配DelayLoop()函数地址,改为在链接文件里指定地址去链接,下面代码是IAR环境下的示例,我们使用debug工程(即在TCM执行)来做测试。
C源文件中在DelayLoop()函数定义前加#pragma location = ".myFunc",即将该函数定义为.myFunc的段,然后在链接文件icf中用place at语句指定.myFunc段到固定地址m_text_func_start处开始链接:
#if defined(__ICCARM__)
#pragma location = ".myFunc"
static void DelayLoop(uint32_t count)
{
// ...
}
#endif
define symbol m_text_func_start = 0x00004000;
place at address mem: m_text_func_start { readonly section .myFunc };
define symbol m_text_start = 0x00002400;
define symbol m_text_end = 0x0003FFFF;
place in TEXT_region { readonly };
根据链接起始地址m_text_func_start的不同,我们得到了不同的结果,如下表所示。至此真相大白,造成DelayMs()函数执行时间不同的根本原因不是XIP/TCM执行差异,而是链接地址对齐差异,8字节对齐的函数更容易触发CM7指令双发射,相比4字节对齐的函数在性能上能提升24.8% 。
| m_text_func_start值 | 链接地址对齐 | 函数调用语句 | 实际执行时间 |
|---|---|---|---|
| 0x00004000 | 8n字节 | DelayMs(100) | 100ms |
| 0x00004002 | 2字节,未能链接 | N/A | N/A |
| 0x00004004 | 4字节 | DelayMs(100) | 133ms |
| 0x00004008 | 8字节 | DelayMs(100) | 100ms |
现在我们得到了一个有趣的结论,Cortex-M7上将函数链接到8字节对齐的地址有利于指令双发射,这就是进一步提升代码执行性能的秘密。
至此,i.MXRT上进一步提升代码执行性能的经验痞子衡便介绍完毕了,掌声在哪里~~~
欢迎订阅
文章会同时发布到我的 博客园主页、CSDN主页、知乎主页、微信公众号 平台上。
微信搜索"痞子衡嵌入式"或者扫描下面二维码,就可以在手机上第一时间看了哦。

最后欢迎关注痞子衡个人微信公众号【痞子衡嵌入式】,一个专注嵌入式技术的公众号,跟着痞子衡一起玩转嵌入式。



衡杰(痞子衡),目前就职于恩智浦(NXP)半导体MCU系统应用部门,担任高级嵌入式系统应用工程师。
专栏内所有文章的转载请注明出处:http://www.cnblogs.com/henjay724/
与痞子衡进一步交流或咨询业务合作请发邮件至 hengjie1989@foxmail.com
可以关注痞子衡的Github主页 https://github.com/JayHeng,有很多好玩的嵌入式项目。
关于专栏文章有任何疑问请直接在博客下面留言,痞子衡会及时回复免费(划重点)答疑。
痞子衡邮箱已被私信挤爆,技术问题不推荐私信,坚持私信请先扫码付款(5元起步)再发。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号