
排序算法的总结
我们通常所说的排序算法往往指的是内部排序算法,即数据记录在内存中进行排序。
排序算法大体可分为两种:
一种是比较排序,时间复杂度O(nlogn) ~ O(n^2),主要有:冒泡排序,选择排序,插入排序,归并排序,堆排序,快速排序等。
另一种是非比较排序,时间复杂度可以达到O(n),主要有:计数排序,基数排序,桶排序等。
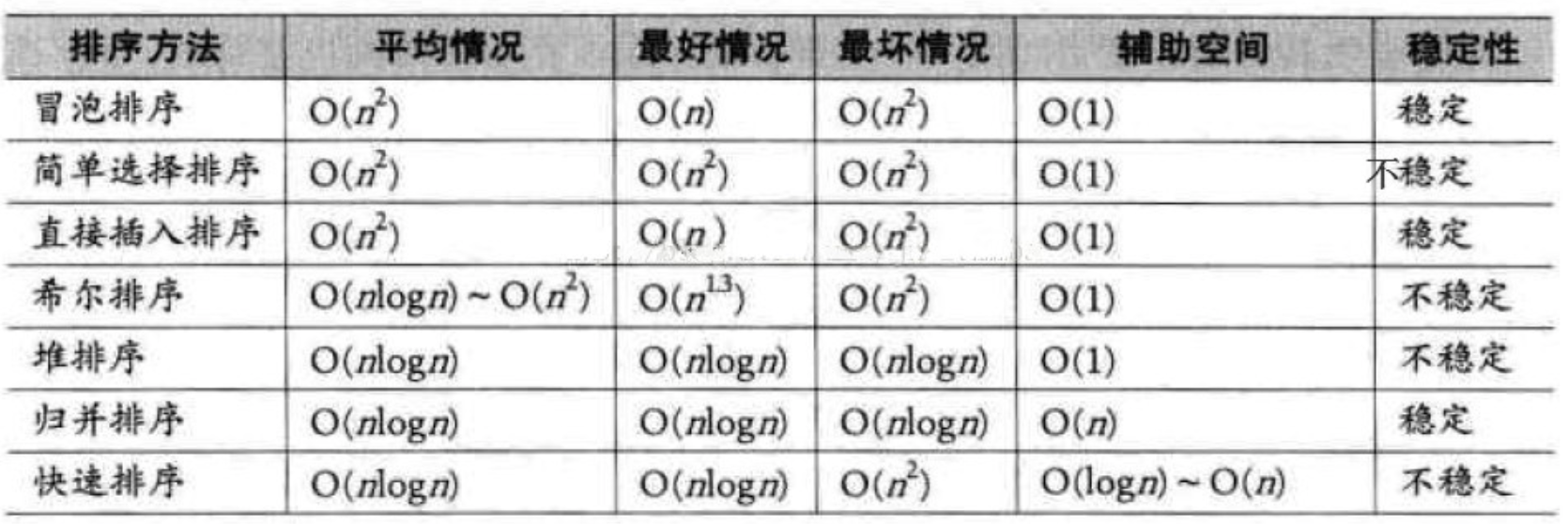
排序算法稳定性的简单形式化定义为:如果Ai = Aj,排序前Ai在Aj之前,排序后Ai还在Aj之前,则称这种排序算法是稳定的。通俗地讲就是保证排序前后两个相等的数的相对顺序不变。
对于不稳定的排序算法,只要举出一个实例,即可说明它的不稳定性;而对于稳定的排序算法,必须对算法进行分析从而得到稳定的特性。需要注意的是,排序算法是否为稳定的是由具体算法决定的,不稳定的算法在某种条件下可以变为稳定的算法,而稳定的算法在某种条件下也可以变为不稳定的算法。
例如,对于冒泡排序,原本是稳定的排序算法,如果将记录交换的条件改成A[i] >= A[i + 1],则两个相等的记录就会交换位置,从而变成不稳定的排序算法。
其次,说一下排序算法稳定性的好处。排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,前一个键排序的结果可以为后一个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位排序后元素的顺序在高位也相同时是不会改变的。
冒泡排序(Bubble Sort)
冒泡排序是一种极其简单的排序算法,也是我所学的第一个排序算法。它重复地走访过要排序的元素,依次比较相邻两个元素,如果他们的顺序错误就把他们调换过来,直到没有元素再需要交换,排序完成。这个算法的名字由来是因为越小(或越大)的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序算法的运作如下:
- 比较相邻的元素,如果前一个比后一个大,就把它们两个调换位置。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
1 def BubbleSort(s): 2 n = len(s) 3 if n <= 1: 4 return s 5 for i in range(n): 6 for j in range(n-i-1): 7 if s[j] > s[j+1]: 8 s[j], s[j+1] = s[j+1], s[j] 9 return s
选择排序(Selection Sort)
选择排序也是一种简单直观的排序算法。它的工作原理很容易理解:初始时在序列中找到最小(大)元素,放到序列的起始位置作为已排序序列;然后,再从剩余未排序元素中继续寻找最小(大)元素,放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
注意选择排序与冒泡排序的区别:冒泡排序通过依次交换相邻两个顺序不合法的元素位置,从而将当前最小(大)元素放到合适的位置;而选择排序每遍历一次都记住了当前最小(大)元素的位置,最后仅需一次交换操作即可将其放到合适的位置。
选择排序的代码如下:
1 def select_sort(s): 2 for i in range(len(s)): 3 min = i 4 for j in range(i+1, len(s)): 5 if s[j] < s[min]: 6 min = j 7 s[i], s[min] = s[min], s[i] 8 return s
插入排序(Insertion Sort)
插入排序是一种简单直观的排序算法。它的工作原理非常类似于我们抓扑克牌
对于未排序数据(右手抓到的牌),在已排序序列(左手已经排好序的手牌)中从后向前扫描,找到相应位置并插入。
插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
插入排序的代码如下:
def insertion_sort(s): for i in range(1, len(s)): save = s[i] j = i while j > 0 and s[j-1] > save: s[j] = s[j-1] j -= 1 s[j] = save
归并排序(Merge Sort)
归并排序是创建在归并操作上的一种有效的排序算法,效率为O(nlogn),1945年由冯·诺伊曼首次提出。
归并排序的实现分为递归实现与非递归(迭代)实现。递归实现的归并排序是算法设计中分治策略的典型应用,我们将一个大问题分割成小问题分别解决,然后用所有小问题的答案来解决整个大问题。非递归(迭代)实现的归并排序首先进行是两两归并,然后四四归并,然后是八八归并,一直下去直到归并了整个数组。
归并排序算法主要依赖归并(Merge)操作。归并操作指的是将两个已经排序的序列合并成一个序列的操作,归并操作步骤如下:
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针到达序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
归并排序的代码如下:
1 def merge_sort(array): 2 def merge_arr(arr_l, arr_r): 3 array = [] 4 while len(arr_l) and len(arr_r): 5 if arr_l[0] <= arr_r[0]: 6 array.append(arr_l.pop(0)) 7 elif arr_l[0] > arr_r[0]: 8 array.append(arr_r.pop(0)) 9 if len(arr_l) != 0: 10 array += arr_l 11 elif len(arr_r) != 0: 12 array += arr_r 13 return array 14 def recursive(array): 15 if len(array) <= 1: 16 return array 17 mid = len(array) // 2 18 arr_l = recursive(array[:mid]) 19 arr_r = recursive(array[mid:]) 20 return merge_arr(arr_l, arr_r) 21 return recursive(array)
堆排序(Heap Sort)
堆排序是指利用堆这种数据结构所设计的一种选择排序算法。堆是一种近似完全二叉树的结构(通常堆是通过一维数组来实现的),并满足性质:以最大堆(也叫大根堆、大顶堆)为例,其中父结点的值总是大于它的孩子节点。
我们可以很容易的定义堆排序的过程:
- 由输入的无序数组构造一个最大堆,作为初始的无序区
- 把堆顶元素(最大值)和堆尾元素互换
- 把堆(无序区)的尺寸缩小1,并调用heapify(A, 0)从新的堆顶元素开始进行堆调整
- 重复步骤2,直到堆的尺寸为1
1 import copy 2 3 def heap_sort(hlist): 4 def heap_adjust(parent): 5 child = 2 * parent + 1 # left child 6 while child < len(heap): 7 if child + 1 < len(heap): 8 if heap[child + 1] > heap[child]: 9 child += 1 # right child 10 if heap[parent] >= heap[child]: 11 break 12 heap[parent], heap[child] = heap[child], heap[parent] 13 parent, child = child, 2 * child + 1 14 15 heap, hlist = copy.copy(hlist), [] 16 for i in range(len(heap) // 2, -1, -1): 17 heap_adjust(i) 18 while len(heap) != 0: 19 heap[0], heap[-1] = heap[-1], heap[0] 20 hlist.insert(0, heap.pop()) 21 heap_adjust(0) 22 return hlist
快速排序(Quick Sort)
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序n个元素要O(nlogn)次比较。在最坏状况下则需要O(n^2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他O(nlogn)算法更快,因为它的内部循环可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治策略(Divide and Conquer)来把一个序列分为两个子序列。步骤为:
- 从序列中挑出一个元素,作为"基准"(pivot).
- 把所有比基准值小的元素放在基准前面,所有比基准值大的元素放在基准的后面(相同的数可以到任一边),这个称为分区(partition)操作。
- 对每个分区递归地进行步骤1~2,递归的结束条件是序列的大小是0或1,这时整体已经被排好序了。
快速排序的代码如下:
def quick_sort(s): if s == []: return [] else: sfirst = s[0] sless = quick_sort([l for l in s[1:] if l < sfirst]) smore = quick_sort([m for m in s[1:] if m >= sfirst]) return sless + sfirst + smore

 浙公网安备 33010602011771号
浙公网安备 33010602011771号