带头结点与不带头节点的区别
●节点结构
typedef struct LNode{ ElemType data; struct LNode *next; }LNode, *LinkList;
●不带头节点:此时头指针指向第一个节点
h->a1->a2->a3->…… // 头指针存放的是第一个节点的地址,即h,也就是说(*h)表示的是第一个节点
带头结点:此时头指针指向头结点
h->headnode->a1->a2->a3->…… // 头指针存放的是头结点的地址,也就是说(*h)表示的是头结点
● 空表的比较
//不带头节点 h = NULL; // h 表示的是第一个节点的地址,h = NULL 表示第一个节点的地址为空,也就是空表 // 带头结点 h->next = NULL; // h 表示的是头结点的地址,h->next 就是头结点的下一个节点,即首元节点为空,也就是空表
● 添加第一个节点的区别
带头结点
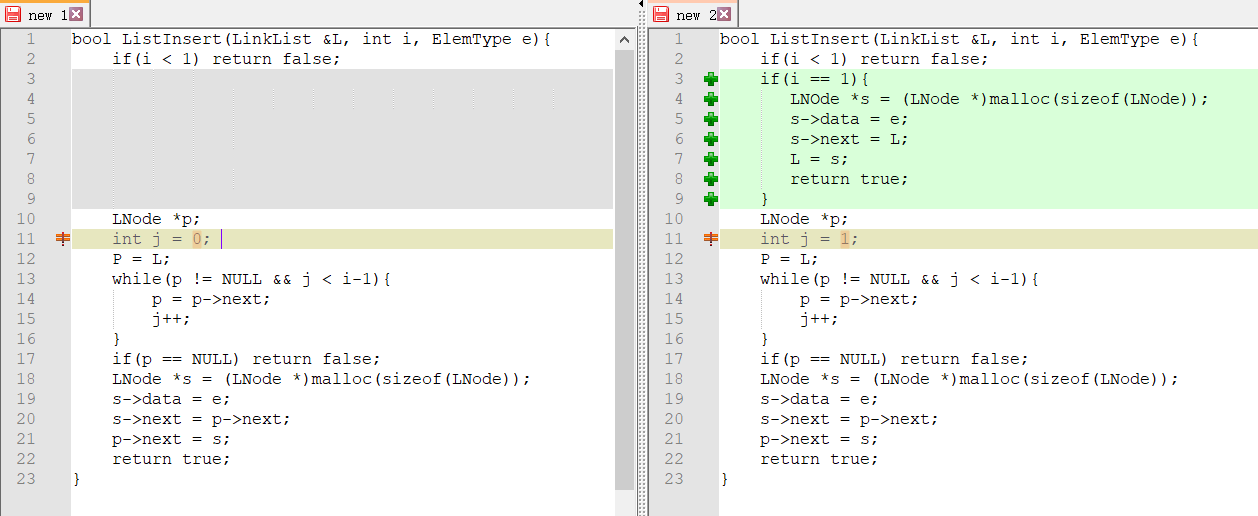
bool ListInsert(LinkList &L, int i, ElemType e){ if(i < 1) return false; LNode *p; int j = 0; // 当前节点是第几个节点 P = L; while(p != NULL && j < i-1){ p = p->next; j++; } if(p == NULL) return false; LNode *s = (LNode *)malloc(sizeof(LNode)); s->data = e; s->next = p->next; p->next = s; return true; }
不带头结点
bool ListInsert(LinkList &L, int i, ElemType e){ if(i < 1) return false; if(i == 1){ LNOde *s = (LNode *)malloc(sizeof(LNode)); s->data = e; s->next = L; L = s; return true; } LNode *p; int j = 1; // 当前p指向第几个节点 P = L; while(p != NULL && j < i-1){ p = p->next; j++; } if(p == NULL) return false; LNode *s = (LNode *)malloc(sizeof(LNode)); s->data = e; s->next = p->next; p->next = s; return true; }
为了方便找到差距,用对比软件看一下哪里不同
总结:
总的来说,就是带头结点时不管是否为空表,头指针的值都不会变化,都指向头结点。而不带头结点则需要根据不同情况来修改头指针的值。
不带头节点写代码不方便,修改链表时,比如添加、删除、修改节点,需要专门写一段代码来解决第一个节点。
所以操作不统一,有所不便,绝大数时候修改链表使用带头结点的方式较为方便,在链表只读的情况可以使用不带头结点的写法。
作者:
贺墨于
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号