hive概念、常用shell
理论基础
1 什么是Hive
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序

1)Hive处理的数据存储在HDFS
2)Hive分析数据底层的实现是MapReduce
3)执行程序运行在Yarn上
2 Hive的优缺点
优点
1) 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
2) 避免了去写MapReduce,减少开发人员的学习成本。
3) Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
4) Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
5) Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
1.Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2.Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
3 Hive架构原理
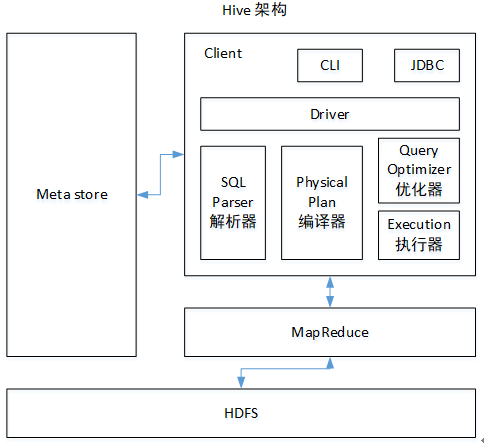
图6-1 Hive架构原理
1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3.Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
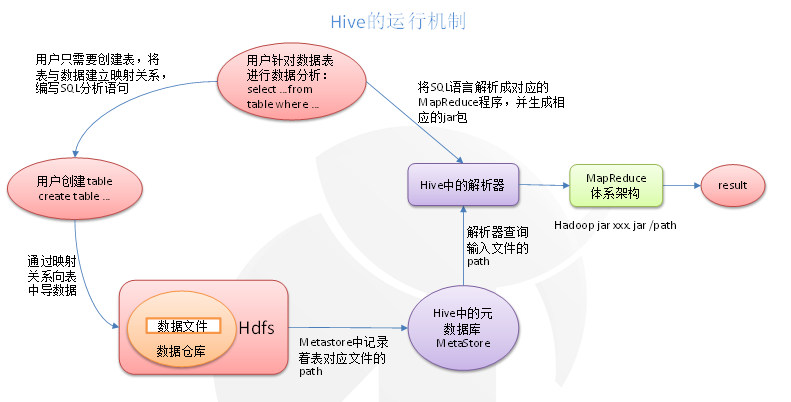
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
6.2 hive的常用shell操作
1 创建数据库、表
hive表分类:内部表、外部表、分区表、桶表。
创建数据库:
hive>create database if not exists hive;
创建表usr(id,name,age):
1:内部表:
hive>use hive
hive>create table if not exists usr(id bigint,name string,age int);
创建的表存储路径为/usr/local/hive/warehouse/hive/usr
hive>create table if not exists usr(id bigint,name string,age int) location ‘/usr/local/hive/warehouse/hive/usr’;
2:外部表:
hive>create external table if not exists usr(id bigint,name string,age int)
>row format delimited fields terminated by ‘’ location ‘/usr/local/data’
注意:
内部表数据存储在hive.metastore.warehouse.dir【默认:/user/hive/warehouse】,外部表数据存储位置由用户自己决定。
删除内部表会直接删除元数据【metadata】及存储数据,删除外部表仅仅删除元数据,HDFS上的文件不会被删除。
3:分区表
hive>create table if not exists usr(id bigint,name string,age int)
>partition by(sex boolean);
2 查看数据库、表
1:查看hive中所有数据库。
hive>show databases;
2:查看表:
hive>use hive;
hive>show tables;
3 向表中装入数据
1、把master的数据装入usr
hive>load data local inpath ‘/usr/local/data’ overwrite into table usr;
2、把hdfs上的数据装入usr
hive>load data inpath ‘hdfs://master_server/usr/local/data’ overwrite into table usr;
4 查询表的数据
和sql语句完全相同。
例如:向表usr1中插入usr的数据并覆盖原有的数据:
hive>insert overwrite table usr1 select * from usr where age=10;
5 删除数据库和表
1:删除数据库
hive>drop database if exists hive;
2:删除表
hive>drop table if exists usr;
注意:
如果是内部表,元数据和实际数据都会被删除;
如果是外部表,只删除元数据,不删除实际数据。
数据类型:参照https://www.cnblogs.com/hemomo/p/12271614.html
复合类型案例:
创建一个员工表(名称:employees)
第一个字段类型为字符串,字段名称:name(描述:员工名字)
第二个字段类型为浮点型,字段名称:salary(描述:员工薪水)
第三个字段类型为数组,其中每个数组元素都是字符串,字段名称:subordinates(描述:下属员工)
第四个字段类型是一个由键一值对构成的map,其中键是字符串、值是浮点型,字段名称:deductions(描述:其中键表示税种,值表示相应税种的金额,这些税将会在发薪水的时候从员工工资中扣除掉)
第五个字段类型是struct,字段名称:address(描述:存储每名雇员的家庭住址)(address的详细结构,其中前三个元素类型都是字符串,名称分别为street、city、state,分别表示街道、城市、省份,最后一个元素类型是整型,名称是zip,表示邮编)
1:创建表
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING,FLOAT>,
address STRUCT<street:STRING,city:STRING,state:STRING,zip:INT>);
2:加载数据:
hive> load data local inpath '/home/zkpk/experiment/demo.txt' overwrite into table employees;
3:将hive employees表中数据下载到本地:
hive> insert overwrite local directory '/home/zkpk/employees' select * from employees;
4:查询的数据存入新表
CREATE TABLE employees11(
name STRING,
salary FLOAT);
insert into employees11 select name,salary from employees;
项目1:hive实现词频统计
1:上传数据
完整的路径:/home/wordcount.txt
2:hql实现wordcount算法
hive>create table docs(line string);
hive>load data inpath ‘inputh’overwrite into table docs;
hive>create table word_count as select word,count(1) as count from
>(select explode(split(line,’ ’)) as word from docs) w
>group by word order by word;
查看结果
hive>select * from word_count;
说明:
explode(split(line,’ ’) //把拆分后的数组,每一个元素变成一行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号