机器学习实战笔记(Python实现)-08-线性回归
---------------------------------------------------------------------------------------
本系列文章为《机器学习实战》学习笔记,内容整理自书本,网络以及自己的理解,如有错误欢迎指正。
源码在Python3.5上测试均通过,代码及数据 --> https://github.com/Wellat/MLaction
---------------------------------------------------------------------------------------
1、线性回归
现有一数据集,其分布如下图所示,
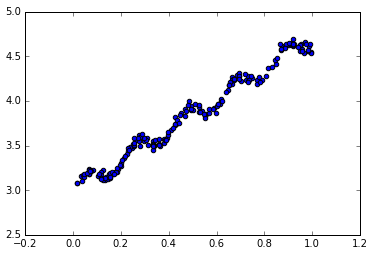
通过观察发现可以通过一个线性方程去拟合这些数据点。可设直线方程为 y=wx. 其中w称为回归系数。那么现在的问题是,如何从一堆x和对应的y中确定w?一个常用的方法就是找出使误差最小的w。这里的误差是指预测y值和真实y值之间的差值,我们采用平方误差,写作:

用矩阵还可以写作: ,如果对w求导,得到
,如果对w求导,得到 ,令其等于零,解出w为:
,令其等于零,解出w为:
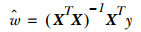
注意此处公式包含对矩阵求逆,所以求解时需要先对矩阵是否可逆做出判断。以上求解w的过程也称为“普通最小二乘法”。
Python实现代码如下:
1 from numpy import * 2 3 def loadDataSet(fileName): 4 '''导入数据''' 5 numFeat = len(open(fileName).readline().split('\t')) - 1 6 dataMat = []; labelMat = [] 7 fr = open(fileName) 8 for line in fr.readlines(): 9 lineArr =[] 10 curLine = line.strip().split('\t') 11 for i in range(numFeat): 12 lineArr.append(float(curLine[i])) 13 dataMat.append(lineArr) 14 labelMat.append(float(curLine[-1])) 15 return dataMat,labelMat 16 17 def standRegres(xArr,yArr): 18 '''求回归系数''' 19 xMat = mat(xArr); yMat = mat(yArr).T 20 xTx = xMat.T*xMat 21 if linalg.det(xTx) == 0.0:#判断行列式是否为0 22 print("This matrix is singular, cannot do inverse") 23 return 24 ws = xTx.I * (xMat.T*yMat)#也可以用NumPy库的函数求解:ws=linalg.solve(xTx,xMat.T*yMatT) 25 return ws 26 27 if __name__ == "__main__": 28 '''线性回归''' 29 xArr,yArr=loadDataSet('ex0.txt') 30 ws=standRegres(xArr,yArr) 31 xMat=mat(xArr) 32 yMat=mat(yArr) 33 #预测值 34 yHat=xMat*ws 35 36 #计算预测值和真实值得相关性 37 corrcoef(yHat.T,yMat)#0.986 38 39 #绘制数据集散点图和最佳拟合直线图 40 #创建图像并绘出原始的数据 41 import matplotlib.pyplot as plt 42 fig=plt.figure() 43 ax=fig.add_subplot(111) 44 ax.scatter(xMat[:,1].flatten().A[0],yMat.T[:,0].flatten().A[0]) 45 #绘最佳拟合直线,需先要将点按照升序排列 46 xCopy=xMat.copy() 47 xCopy.sort(0) 48 yHat = xCopy*ws 49 ax.plot(xCopy[:,1],yHat) 50 plt.show()
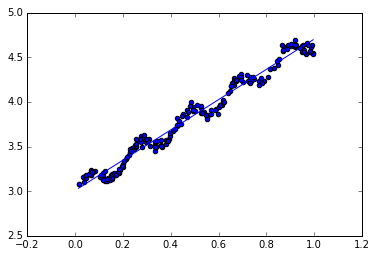
几乎任一数据集都可以用上述方法建立模型,只是需要判断模型的好坏,计算预测值yHat和实际值yMat这两个序列的相关系数,可以查看它们的匹配程度。
2、局部加权线性回归
局部加权线性回归给待预测点附近的每个点赋予一定的权重,用于解决线性回归可能出现的欠拟合现象。与kNN法类似,这种算法每次预测均需要事先选取出对应的数据子集,然后在这个子集上基于最小均分差来进行普通的回归。该算法解出回归系数的形式如下:

其中w是一个权重矩阵,通常采用核函数来对附近的点赋予权重,最常用的核函数是高斯核,如下:
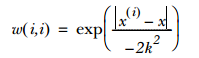
这样就构建了一个只含对角元素的权重矩阵W并且点x与x(i)越近,w(i,i)将会越大,k值控制衰减速度,且k值越小被选用于训练回归模型的数据集越小。
Python实现代码:
1 def lwlr(testPoint,xArr,yArr,k=1.0): 2 '''局部加权线性回归函数''' 3 xMat = mat(xArr); yMat = mat(yArr).T 4 m = shape(xMat)[0] 5 weights = mat(eye((m)))#创建对角矩阵 6 for j in range(m): 7 diffMat = testPoint - xMat[j,:] 8 #高斯核计算权重 9 weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2)) 10 xTx = xMat.T * (weights * xMat) 11 if linalg.det(xTx) == 0.0: 12 print("This matrix is singular, cannot do inverse") 13 return 14 ws = xTx.I * (xMat.T * (weights * yMat)) 15 return testPoint * ws 16 17 def lwlrTest(testArr,xArr,yArr,k=1.0): 18 '''为数据集中每个点调用lwlr()''' 19 m = shape(testArr)[0] 20 yHat = zeros(m) 21 for i in range(m): 22 yHat[i] = lwlr(testArr[i],xArr,yArr,k) 23 return yHat 24 25 if __name__ == "__main__": 26 '''局部加权线性回归''' 27 xArr,yArr=loadDataSet('ex0.txt') 28 #拟合 29 yHat=lwlrTest(xArr,xArr,yArr,0.01) 30 #绘图 31 xMat=mat(xArr) 32 yMat=mat(yArr) 33 srtInd = xMat[:,1].argsort(0) 34 xSort=xMat[srtInd][:,0,:] 35 import matplotlib.pyplot as plt 36 fig=plt.figure() 37 ax=fig.add_subplot(111) 38 ax.plot(xSort[:,1],yHat[srtInd]) 39 ax.scatter(xMat[:,1].flatten().A[0],yMat.T[:,0].flatten().A[0],s=2,c='red') 40 plt.show()
k取0.01的结果

实际上,对k取不同值时有如下结果:

3、岭回归
如果数据的特征比样本点多(n>m),也就是说输入数据的矩阵x不是满秩矩阵。而非满秩矩阵在求逆时会出错,所以此时不能使用之前的线性回归方法。为解决这个问题,统计学家引入了岭回归的概念。
简单来说,岭回归就是在矩阵xTx上加一个λI从而使得矩阵非奇异,进而能对 xTx+λI 求逆,其中I是一个mxm的单位矩阵。在这种情况下,回归系数的计算公式将变成:

这里通过引入λ来限制了所有w之和,通过引入该惩罚项,能减少不重要的参数,这个技术在统计学中也叫缩减。
Python实现代码:
1 def ridgeRegres(xMat,yMat,lam=0.2): 2 '''计算岭回归系数''' 3 xTx = xMat.T*xMat 4 denom = xTx + eye(shape(xMat)[1])*lam 5 if linalg.det(denom) == 0.0: 6 print("This matrix is singular, cannot do inverse") 7 return 8 ws = denom.I * (xMat.T*yMat) 9 return ws 10 11 def ridgeTest(xArr,yArr): 12 '''用于在一组lambda上测试结果''' 13 xMat = mat(xArr); yMat=mat(yArr).T 14 yMean = mean(yMat,0) 15 yMat = yMat - yMean #数据标准化 16 xMeans = mean(xMat,0) 17 xVar = var(xMat,0) 18 xMat = (xMat - xMeans)/xVar #所有特征减去各自的均值并除以方差 19 numTestPts = 30 #取30个不同的lambda调用函数 20 wMat = zeros((numTestPts,shape(xMat)[1])) 21 for i in range(numTestPts): 22 ws = ridgeRegres(xMat,yMat,exp(i-10)) 23 wMat[i,:]=ws.T 24 return wMat 25 26 if __name__ == "__main__": 27 '''岭回归''' 28 abX,abY=loadDataSet('abalone.txt') 29 ridgeWeights = ridgeTest(abX,abY)#得到30组回归系数 30 #缩减效果图 31 import matplotlib.pyplot as plt 32 fig=plt.figure() 33 ax=fig.add_subplot(111) 34 ax.plot(ridgeWeights) 35 plt.show()
运行之后得到下图,横轴表示第i组数据,纵轴表示该组数据对应的回归系数值。从程序中可以看出lambda的取值为 exp(i-10) 其中i=0~29。所以结果图的最左边,即λ最小时,可以得到所有系数的原始值(与线性回归一致);而在右边,系数全部缩减为0;在中间部分的某些值可以取得最好的预测效果。
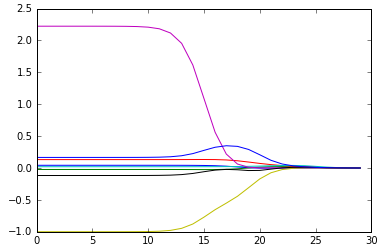
4、前向逐步回归
前向逐步回归算法属于一种贪心算法,即每一步尽可能减少误差。一开始,所有的权重都设为1,然后每一步所做的决策是对某个权重增加或减少一个很小的值。
该算法伪代码如下所示:

Python实现代码:
1 def regularize(xMat): 2 '''数据标准化函数''' 3 inMat = xMat.copy() 4 inMeans = mean(inMat,0) 5 inVar = var(inMat,0) 6 inMat = (inMat - inMeans)/inVar 7 return inMat 8 9 def rssError(yArr,yHatArr): 10 '''计算均方误差大小''' 11 return ((yArr-yHatArr)**2).sum() 12 13 def stageWise(xArr,yArr,eps=0.01,numIt=100): 14 ''' 15 逐步线性回归算法 16 eps:表示每次迭代需要调整的步长 17 ''' 18 xMat = mat(xArr); yMat=mat(yArr).T 19 yMean = mean(yMat,0) 20 yMat = yMat - yMean 21 xMat = regularize(xMat) 22 m,n=shape(xMat) 23 returnMat = zeros((numIt,n)) #testing code remove 24 #为了实现贪心算法建立ws的两份副本 25 ws = zeros((n,1)); wsTest = ws.copy(); wsMax = ws.copy() 26 for i in range(numIt): 27 print(ws.T) 28 lowestError = inf; 29 for j in range(n):#对每个特征 30 for sign in [-1,1]:#分别计算增加或减少该特征对误差的影响 31 wsTest = ws.copy() 32 wsTest[j] += eps*sign 33 yTest = xMat*wsTest 34 rssE = rssError(yMat.A,yTest.A) 35 #取最小误差 36 if rssE < lowestError: 37 lowestError = rssE 38 wsMax = wsTest 39 ws = wsMax.copy() 40 returnMat[i,:]=ws.T 41 return returnMat 42 43 if __name__ == "__main__": 44 '''前向逐步线性回归''' 45 abX,abY=loadDataSet('abalone.txt') 46 stageWise(abX,abY,0.01,200)
运行结果如下:

上述结果中值得注意的是w1和w6都是0,这表明它们不对目标值造成任何影响,也就是说这些特征很可能是不需要的。另外,第一个权重在0.04和0.05之间来回震荡,这是因为步长eps太大的缘故,一段时间后系数就已经饱和并在特定值之间来回震荡。
5、实例:预测乐高玩具套装的价格
5.1 收集数据
原书介绍了从Google上在线获取数据的方式,但是经测试该网址已经不可用,此处采用从离线网页中爬取的方式收集数据。实现代码如下:
1 def setDataCollect(retX, retY): 2 '''数据获取方式一(不可用)''' 3 # searchForSet(retX, retY, 8288, 2006, 800, 49.99) 4 # searchForSet(retX, retY, 10030, 2002, 3096, 269.99) 5 # searchForSet(retX, retY, 10179, 2007, 5195, 499.99) 6 # searchForSet(retX, retY, 10181, 2007, 3428, 199.99) 7 # searchForSet(retX, retY, 10189, 2008, 5922, 299.99) 8 # searchForSet(retX, retY, 10196, 2009, 3263, 249.99) 9 '''数据获取方式二''' 10 scrapePage("setHtml/lego8288.html","data/lego8288.txt",2006, 800, 49.99) 11 scrapePage("setHtml/lego10030.html","data/lego10030.txt", 2002, 3096, 269.99) 12 scrapePage("setHtml/lego10179.html","data/lego10179.txt", 2007, 5195, 499.99) 13 scrapePage("setHtml/lego10181.html","data/lego10181.txt", 2007, 3428, 199.99) 14 scrapePage("setHtml/lego10189.html","data/lego10189.txt", 2008, 5922, 299.99) 15 scrapePage("setHtml/lego10196.html","data/lego10196.txt", 2009, 3263, 249.99) 16 17 def scrapePage(inFile,outFile,yr,numPce,origPrc): 18 from bs4 import BeautifulSoup 19 fr = open(inFile,'r',encoding= 'utf8'); fw=open(outFile,'a') #a is append mode writing 20 soup = BeautifulSoup(fr.read()) 21 i=1 22 currentRow = soup.findAll('table', r="%d" % i) 23 while(len(currentRow)!=0): 24 title = currentRow[0].findAll('a')[1].text 25 lwrTitle = title.lower() 26 if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1): 27 newFlag = 1.0 28 else: 29 newFlag = 0.0 30 soldUnicde = currentRow[0].findAll('td')[3].findAll('span') 31 if len(soldUnicde)==0: 32 print("item #%d did not sell" % i) 33 else: 34 soldPrice = currentRow[0].findAll('td')[4] 35 priceStr = soldPrice.text 36 priceStr = priceStr.replace('$','') #strips out $ 37 priceStr = priceStr.replace(',','') #strips out , 38 if len(soldPrice)>1: 39 priceStr = priceStr.replace('Free shipping', '') #strips out Free Shipping 40 print("%s\t%d\t%s" % (priceStr,newFlag,title)) 41 fw.write("%d\t%d\t%d\t%f\t%s\n" % (yr,numPce,newFlag,origPrc,priceStr)) 42 i += 1 43 currentRow = soup.findAll('table', r="%d" % i) 44 fw.close() 45 46 if __name__ == "__main__": 47 '''乐高玩具价格预测'''
48 #爬取数据
49 setDataCollect() 50 #读取数据,这里已将以上方式获取到的数据文本整合成为一个文件即legoAllData.txt 51 xmat,ymat = loadDataSet("data/legoAllData.txt")
5.2 训练算法
首先我们用普通的线性回归模型拟合数据看效果,拟合之前需要先添加对应常数项的特征X0
1 if __name__ == "__main__": 2 '''乐高玩具价格预测''' 3 #爬取数据 4 # setDataCollect() 5 #读取数据,这里已将以上方式获取到的数据文本整合成为一个文件即legoAllData.txt 6 # xMat,yMat = loadDataSet("data/legoAllData.txt") 7 #添加对应常数项的特征X0(X0=1) 8 lgX=mat(ones((76,5))) 9 lgX[:,1:5]=mat(xmat) 10 lgY=mat(ymat).T 11 12 #用标准回归方程拟合 13 ws1=standRegres(lgX,mat(ymat)) #求标准回归系数 14 yHat = lgX*ws1 #预测值 15 err1 = rssError(lgY.A,yHat.A) #计算平方误差 16 cor1 = corrcoef(yHat.T,lgY.T) #计算预测值和真实值得相关性
测试结果为相关性cor1:0.7922,平方误差和err1:3552526,显然拟合效果还可以进一步提升。
接下来我们用交叉验证测试岭回归:
1 def crossValidation(xArr,yArr,numVal=10): 2 ''' 3 交叉验证测试岭回归 4 numVal:交叉验证次数 5 ''' 6 m = len(yArr) 7 indexList = list(range(m)) 8 errorMat = zeros((numVal,30)) 9 for i in range(numVal): 10 trainX=[]; trainY=[] 11 testX = []; testY = [] 12 random.shuffle(indexList)#打乱顺序 13 for j in range(m):#构建训练和测试数据,10%用于测试 14 if j < m*0.9: 15 trainX.append(xArr[indexList[j]]) 16 trainY.append(yArr[indexList[j]]) 17 else: 18 testX.append(xArr[indexList[j]]) 19 testY.append(yArr[indexList[j]]) 20 wMat = ridgeTest(trainX,trainY) #30组不同参数下的回归系数集 21 for k in range(30):#遍历30个回归系数集 22 matTestX = mat(testX); matTrainX=mat(trainX) 23 meanTrain = mean(matTrainX,0) 24 varTrain = var(matTrainX,0) 25 matTestX = (matTestX-meanTrain)/varTrain #用训练参数标准化测试数据 26 yEst = matTestX * mat(wMat[k,:]).T + mean(trainY)#预测值 27 errorMat[i,k]=rssError(yEst.T.A,array(testY))#计算预测平方误差 28 # print(errorMat[i,k]) 29 #在完成所有交叉验证后,errorMat保存了ridgeTest()每个lambda对应的多个误差值 30 meanErrors = mean(errorMat,0)#计算每组平均误差 31 minMean = float(min(meanErrors)) 32 bestWeights = wMat[nonzero(meanErrors==minMean)]#平均误差最小的组的回归系数即为所求最佳 33 #岭回归使用了数据标准化,而strandRegres()则没有,因此为了将上述比较可视化还需将数据还原 34 xMat = mat(xArr); yMat=mat(yArr).T 35 meanX = mean(xMat,0); varX = var(xMat,0) 36 unReg = bestWeights/varX #还原后的回归系数 37 constant = -1*sum(multiply(meanX,unReg)) + mean(yMat) #常数项 38 print("the best model from Ridge Regression is:\n",unReg) 39 print("with constant term: ",constant) 40 return unReg,constant 41 42 43 if __name__ == "__main__": 44 '''乐高玩具价格预测''' 45 #用交叉验证测试岭回归 46 ws2,constant = crossValidation(xmat,ymat,10) 47 yHat2 = mat(xmat)*ws2.T + constant 48 err2 = rssError(lgY.A,yHat2.A) 49 cor2 = corrcoef(yHat2.T,lgY.T)
测试结果为相关性cor2:0.7874,平方误差和err2:3827083,与最小二乘法比较好并没有太大差异。其实这种分析方法使得我们可以挖掘大量数据的内在规律。在仅有4个特征时,该方法的效果也许并不明显;但如果有100个以上的特征,该方法就会变得十分有效:它可以指出哪些特征是关键的,而哪些特征是不重要的。
THE END.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号