python中响应对象text属性出现乱码 ,和 decode()的erros参数的使用
在获得网页响应对象res后,使用res.text属性可以获得网页源代码,但可能出现乱码!因为requests库会使用自动猜测的解码方式将抓取的网页源码进行解码,然后存储到res对象的text属性中;
但有的网站的编码格式和requests库默认的解码格式()不一样(比如gbk gb2312是gbk的子集),这时候就要自己手动进行解码,先获得content属性,返回的是bytes类型的字符串,再进行解码decode(“网页的编码
格式”)
这时候可能出现新的问题
'gbk' codec can't decode byte 0xd0 in position 15264: illegal multibyte sequence
这是因为遇到了非法字符
比如网页中有这种字符
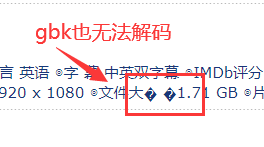
全角空格往往有多种不同的实现方式,比如\xa3\xa0,或者\xa4\x57,这些 字符,看起来都是全角空格,但它们并不是“合法”的全角空格(真正的全角空格是\xa1\xa1),因此在转码的过程中出现了异常。
只要字符串中出现了一个非法字符,整篇文章就都无法转码。
对于这种字符,根本不需要,不重要!
解决方法:在解码时候指定errors参数,
decode()的函数原型是 decode([encoding], [errors='strict']),可以用第二个参数控制错误处理的策略,默认的参数是strict,代表遇到非法字符时抛出异常;
- 如果设置为ignore,则会忽略非法字符;
- 如果设置为replace,则会用?取代非法字符;
- 如果设置为xmlcharrefreplace,则使用XML的字符引用
#requests库默认会使用自己猜测的解码方式将抓取下来的网页进行解码,然后存储到text属性上去;
#但在该网站中,编码方式和默认的解码方式不一样,就会产生乱码,所以要手动进行解码,先获得content再decode()解码
#右键查看网页源代码,发现是gb2312编码,gb2312就是gbk的子集,所以用decode("gbk")

