编译原理——词法分析器实现
参考:https://www.cnblogs.com/zyrblog/p/6885922.html
|
单词符号 |
类别码 |
助记符 |
说明 |
|
BEGIN |
1 |
BEGIN |
保留字 |
|
DO |
2 |
DO |
保留字 |
|
ELSE |
3 |
ELSE |
保留字 |
|
END |
4 |
END |
保留字 |
|
IF |
5 |
IF |
保留字 |
|
INTEGER |
6 |
INTEGER |
保留字 |
|
PROGRAM |
7 |
PROGRAM |
保留字 |
|
THEN |
8 |
THEN |
保留字 |
|
VAR |
9 |
VAR |
保留字 |
|
WHILE |
10 |
WHILE |
保留字 |
|
整数 |
11 |
INT |
整数不大于65535 |
|
标识符 |
12 |
ID |
字母打头的字母数字串,标识符长度不大于8 |
|
+ |
13 |
ADD |
|
|
- |
14 |
SUB |
|
|
* |
15 |
MUL |
|
|
/ |
16 |
DIV |
|
|
: |
17 |
COLON |
|
|
:= |
18 |
COL_EQ |
赋值符号 |
|
< |
19 |
LT |
|
|
<> |
20 |
NE |
不等于符号 |
|
<= |
21 |
LE |
|
|
> |
22 |
GT |
|
|
>= |
23 |
GE |
|
|
= |
24 |
EQ |
|
|
; |
25 |
SEMI |
|
|
( |
26 |
LP |
|
|
) |
27 |
RP |
|
|
, |
28 |
COMMA |

1 #include<bits/stdc++.h> 2 using namespace std; 3 const int N=1e6; 4 int index;//记录符号流的长度 5 map<string,int> typeCode;//保留字类别码表 6 struct erYuanNode//单词二元组 7 { 8 string text;//单词内容 9 int type,x,y;//type为类别,x,y为首字母坐标 10 }erYuanZu[N]; 11 struct fuhaoliunode//符号流 12 { 13 char text;//字符内容 14 int x,y;//x为横坐标,y为纵坐标(都从1开始) 15 }fuhaoliu[N]; 16 fstream file("E:\\PrincipleOfCompiler\\input.txt"); 17 void initTypeCode()//初始化保留字类别表 18 { 19 typeCode["BEGIN"]=1; 20 typeCode["DO"]=2; 21 typeCode["ELSE"]=3; 22 typeCode["END"]=4; 23 typeCode["IF"]=5; 24 typeCode["INTEGER"]=6; 25 typeCode["PROGRAM"]=7; 26 typeCode["THEN"]=8; 27 typeCode["VAR"]=9; 28 typeCode["WHILE"]=10; 29 typeCode["+"]=13; 30 typeCode["-"]=14; 31 typeCode["*"]=15; 32 typeCode["/"]=16; 33 typeCode[":"]=17; 34 typeCode[":="]=18; 35 typeCode["<"]=19; 36 typeCode["<>"]=20; 37 typeCode["<="]=21; 38 typeCode[">"]=22; 39 typeCode[">="]=23; 40 typeCode["="]=24; 41 typeCode[";"]=25; 42 typeCode["("]=26; 43 typeCode[")"]=27; 44 typeCode[","]=28; 45 } 46 void testTypeCode()//查看保留字类别表 47 { 48 map<string,int>::iterator iter; 49 for (iter=typeCode.begin();iter!=typeCode.end();iter++) 50 { 51 cout<<iter->first<<" "<<iter->second<<endl; 52 } 53 } 54 void preprocess()//预处理 55 { 56 /*删除注释*/ 57 fuhaoliu[0].text='#';//#为单词间的分隔符 58 fuhaoliu[0].x=fuhaoliu[0].y=0; 59 int isNotea=0,x=0;//isNotea标记是否为注释模式,index为字符数组下标 60 index=1; 61 string s;//存储临时读入的串 62 while (getline(file,s))//整行读入 63 { 64 x++; 65 if (fuhaoliu[index-1].text!='#') 66 { 67 fuhaoliu[index].text='#';//与上一串字符分隔开 68 fuhaoliu[index].x=fuhaoliu[index].y=0;//规定‘#’字符的坐标为(0,0) 69 index++;//继续读取下一个字符 70 } 71 for (int i=0;i<s.size();i++) 72 { 73 if (s[i]==' '||s[i]=='\t')//该字符为空格或制表符 74 { 75 if (fuhaoliu[index-1].text=='#')//如果已和上一字符串分隔,则往后读取 76 { 77 continue; 78 } 79 else//该处设为分隔符 80 { 81 fuhaoliu[index].text='#'; 82 fuhaoliu[index].x=fuhaoliu[index].y=0; 83 index++; 84 continue; 85 } 86 } 87 if (i+1<s.size()&&s[i]=='/'&&s[i+1]=='*')//发现注释开始符 88 { 89 isNotea=1; 90 i++; 91 continue; 92 } 93 if (isNotea==1&&i+1<s.size()&&s[i]=='*'&&s[i+1]=='/')//发现注释结束符 94 { 95 isNotea=0; 96 i++; 97 continue; 98 } 99 if (i+1<s.size()&&s[i]=='/'&&s[i+1]=='/')//发现第二种注释直接退出读取下一行 100 { 101 break; 102 } 103 if (isNotea)//不存储注释内容 104 { 105 continue; 106 } 107 fuhaoliu[index].text=s[i];//存储内容到字符流数组 108 fuhaoliu[index].x=x; 109 fuhaoliu[index++].y=i+1; 110 } 111 } 112 if(isNotea)//未找到注释结束符 113 { 114 printf("ERROR:annotator not match!\n"); 115 } 116 fuhaoliu[index++].text='#';//在字符流数组末尾加上分隔符 117 } 118 void test()//查看输出 119 { 120 for (int i=0;i<160;i++) 121 { 122 printf("ind%d FuHaoLiu[%c] x%d y%d erYuanZu:x%d y%d type%d ",i,fuhaoliu[i].text,fuhaoliu[i].x,fuhaoliu[i].y,erYuanZu[i].x,erYuanZu[i].y,erYuanZu[i].type); 123 cout<<"eryuantext:["<<erYuanZu[i].text<<"]"<<endl; 124 } 125 printf("index%d\n",index); 126 } 127 void Error(string temp,int x,int y,int type)//报错函数 128 { 129 if(temp!="#") 130 { 131 if (type==1) 132 { 133 printf("ERROR(the length of identifier is bigger than 8): x%d y%d \n",x,y); 134 } 135 else if(type==2) 136 { 137 printf("ERROR(the number is bigger than 65535): x%d y%d\n",x,y); 138 } 139 else if(type==3) 140 { 141 printf("ERROR(the input is illegal) x%d y%d\n",x,y); 142 } 143 cout<<"["<<temp<<"]"<<endl;//输出错误串 144 } 145 } 146 void out(string temp,int x,int y,int indexa)//检查单词并存入二元组 147 { 148 if (typeCode[temp]!=NULL)//保留字 149 { 150 erYuanZu[indexa].text=temp; 151 erYuanZu[indexa].x=x; 152 erYuanZu[indexa].y=y; 153 erYuanZu[indexa].type=typeCode[temp]; 154 } 155 else if(temp[0]>='A'&&temp[0]<='Z')//标识符 156 { 157 if (temp.size()>8) 158 { 159 Error(temp,x,y,1); 160 } 161 else 162 { 163 erYuanZu[indexa].text=temp; 164 erYuanZu[indexa].x=x; 165 erYuanZu[indexa].y=y; 166 erYuanZu[indexa].type=12; 167 } 168 } 169 else if(temp[0]>='0'&&temp[0]<='9')//数字 170 { 171 int tem=0; 172 for (int i=temp.size()-1,j=1;i>=0;i--,j++)//转化为数值 173 { 174 tem+=((temp[i]-'0')*j); 175 j*=10; 176 } 177 if (tem>65535) 178 { 179 Error(temp,x,y,2); 180 } 181 else 182 { 183 erYuanZu[indexa].text=temp; 184 erYuanZu[indexa].x=x; 185 erYuanZu[indexa].y=y; 186 erYuanZu[indexa].type=11; 187 } 188 } 189 else 190 { 191 Error(temp,x,y,3); 192 } 193 } 194 void distinguish()//分析单词(结合最小化DFA图) 195 { 196 int status=0,indexa=0,x,y;//status为状态,indexa为二元组下标,x,y为单词首字母坐标 197 char now;//当前读取的字符 198 string temp;//暂存单词 199 for (int i=0;i<index;i++) 200 { 201 now=fuhaoliu[i].text; 202 switch (status)//进行状态转移 203 { 204 case 0: 205 temp=""; 206 x=fuhaoliu[i].x; 207 y=fuhaoliu[i].y; 208 if (isalpha(now))//读入字母 209 { 210 status=1; 211 temp+=now; 212 } 213 else if(isdigit(now))//读入数字 214 { 215 status=3; 216 temp+=now; 217 } 218 else if(now=='+'||now=='-'|| 219 now=='*'||now=='/'||now=='='||now=='('|| 220 now==')'||now==','||now==';')//读入特殊符号 221 { 222 status=5; 223 temp+=now; 224 } 225 else if(now==':') 226 { 227 status=6; 228 temp+=now; 229 } 230 else if(now=='<') 231 { 232 status=8; 233 temp+=now; 234 } 235 else if(now=='>') 236 { 237 status=11; 238 temp+=now; 239 } 240 else//读入非法字符 241 { 242 status=0; 243 temp+=now; 244 Error(temp,x,y,3); 245 } 246 break; 247 case 1: 248 if (isalnum(now))//读入字母或数字 249 { 250 status=1; 251 temp+=now; 252 } 253 else 254 { 255 i--;//回退 256 status=2; 257 } 258 break; 259 case 3: 260 if (isdigit(now))//读入数字 261 { 262 status=3; 263 temp+=now; 264 } 265 else 266 { 267 status=4; 268 i--; 269 } 270 break; 271 case 6: 272 if (now=='=') 273 { 274 status=7; 275 temp+=now; 276 } 277 else 278 { 279 status=16; 280 i--; 281 } 282 break; 283 case 8: 284 if (now=='=') 285 { 286 status=9; 287 temp+=now;//加入字符到当前串 288 } 289 else if(now=='>') 290 { 291 status=10; 292 temp+=now; 293 } 294 else 295 { 296 status=15; 297 i--; 298 } 299 break; 300 case 11: 301 if (now=='=') 302 { 303 status=12; 304 temp+=now; 305 } 306 else 307 { 308 status=14; 309 i--; 310 } 311 break; 312 } 313 if (status==2||status==4||status==5|| 314 status==7||status==16||status==9||status==10|| 315 status==15||status==12||status==14)//输出的状态(终态) 316 { 317 out(temp,x,y,indexa++); 318 status=0; 319 } 320 } 321 } 322 int main() 323 { 324 initTypeCode();//初始化类别表 325 preprocess();//预处理 326 distinguish();//分析单词 327 test();//查看输出 328 329 return 0; 330 }
源程序示例:
PROGRAM TEST2: /*
find the sum of one to five, and do some operation about it
*/
VAR A,B,SUM:INTEGER;
A:=5;
B:=1;
C:=10;
SUM:=0;
BEGIN
WHILE A>0 DO
BEGIN
SUM:=SUM+B;
B:=B+1;
A:=A-1;
END;
SUM:=SUM*(2+2);
SUM:=SUM/2;
END
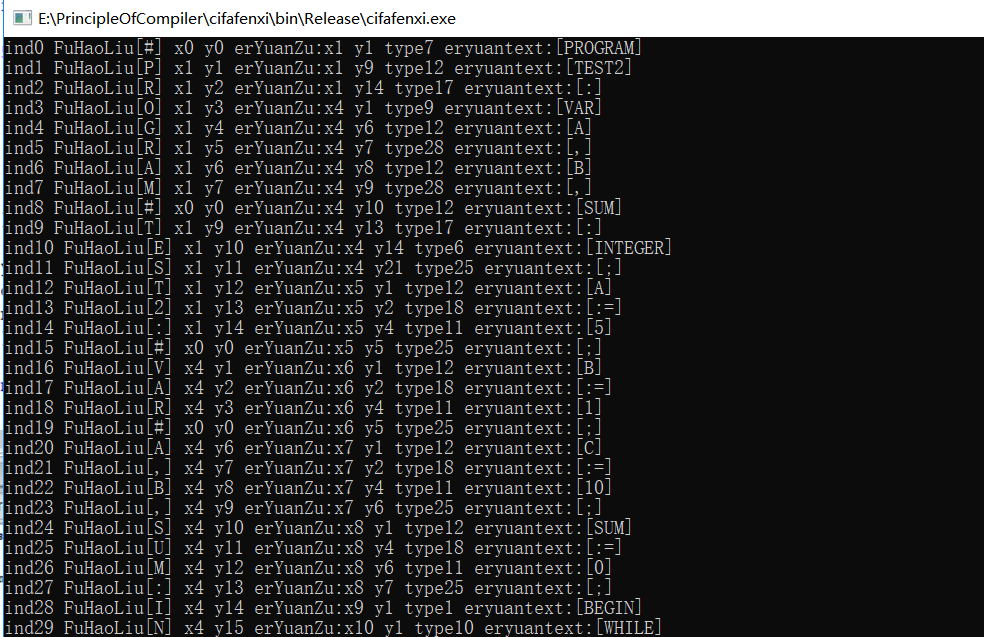
运行结果: