手撸机器学习算法 - 非线性问题
系列文章目录:
算法介绍
前面两篇分别介绍了分类与回归问题中各自最简单的算法,有一点相同的是它们都是线性的,而实际工作中遇到的基本都是非线性问题,而能够处理非线性问题是机器学习有实用价值的基础;
首先,非线性问题在分类与回归中的表现是不同的,在回归问题中,通常指的是无法通过线性模型很好的拟合,而在分类问题中,非线性问题指的是无法通过超平面进行正确的分类;
对于非线性问题的处理方法:
- 从数据出发:由于非线性是基于当前的特征空间,因此一般可以通过特征转换、升维等方式使得问题在新的特征空间中转为线性(可以推导只要维度足够多,数据总是线性的);
- 从模型出发:使用能处理非线性的模型来处理问题,比如决策树、神经网络等;
本篇主要从数据或者说特征的角度来看如何处理分类和回归的非线性问题,这一类处理手段与具体的算法无关,因此有更大的普适性,在机器学习中也被广泛的使用;
PS:注意代码中用到的线性回归、感知机等模型都是自己实现的哈,不是sklearn的,所以可能参数、用法、结果并不完全一致;
非线性回归问题
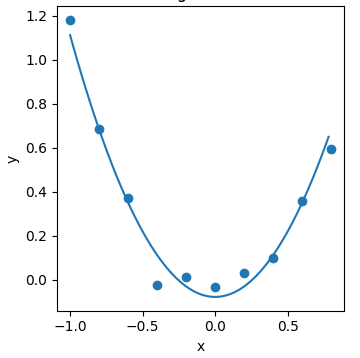
典型的非线性回归问题数据分布情况如下图,注意x为输入特征,y为输出目标:
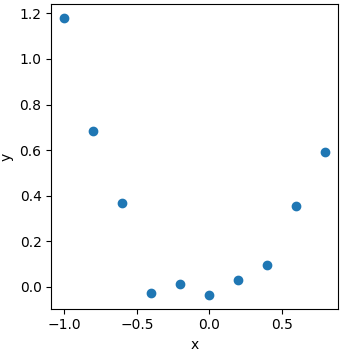
可以看到,该数据集无法用一条直线来较好的拟合,而应该使用一条曲线,那么问题就变成了如何使得只能拟合直线的线性回归能够拟合出一条合适的曲线;
解决思路
由于线性回归只能拟合直线,而当前数据集可视化后明显不是直线,因此解决思路只能从数据上入手,即通过修改坐标系(或者叫特征转换)来改变数据的分布排列情况,使得其更接近于线性;
针对此处的数据集,通过观察其分布情况,考虑将\(x\)转换为\(x^2\),当然,实际工作中不仅需要进行数据探索,同时也需要大量的尝试才能找到最合适的特征转换方法;
代码实现
构建非线性数据集
X = np.array([-1+(1-(-1))*(i/10) for i in range(10)]).reshape(-1,1)
y = (X**2)+rnd.normal(scale=.1,size=X.shape)
直接跑线性回归模型
model = LR(X=X,y=y)
w,b = model.train()
print(w,b)
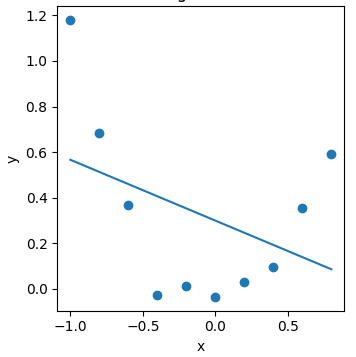
通过特征转换来改变数据分布情况
X2 = X**2
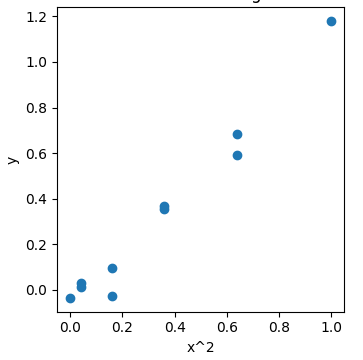
在转换后的数据集上运行线性回归
model = LR(X=X2,y=y)
w,b = model.train()
print(w,b)
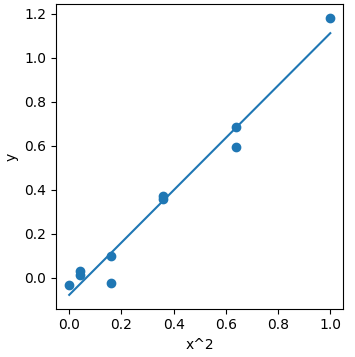
在原始坐标系下绘制线性回归的拟合线
x_min,x_max = min(X[:,0]),max(X[:,0])
line_x = [x_min+(x_max-x_min)*(i/100) for i in range(100)]
line_y = [model.predict(np.array([x**2])) for x in line_x]
完整代码
import numpy as np
import matplotlib.pyplot as plt
from 线性回归最小二乘法矩阵实现 import LinearRegression as LR
plt.figure(figsize=(18,4))
def pain(pos=141,xlabel='x',ylabel='y',title='',x=[],y=[],line_x=[],line_y=[]):
plt.subplot(pos)
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.scatter(x,y)
plt.plot(line_x,line_y)
rnd = np.random.RandomState(3) # 为了演示,采用固定的随机
X = np.array([-1+(1-(-1))*(i/10) for i in range(10)]).reshape(-1,1)
y = (X**2)+rnd.normal(scale=.1,size=X.shape)
model = LR(X=X,y=y)
w,b = model.train()
print(w,b)
line_x = [min(X[:,0]),max(X[:,0])]
line_y = [model.predict(np.array([min(X[:,0])])),model.predict(np.array([max(X[:,0])]))]
pain(131,'x','y','degress=1',X[:,0],y[:,0],line_x,line_y)
X2 = X**2
model = LR(X=X2,y=y)
w,b = model.train()
print(w,b)
line_x = [min(X2[:,0]),max(X2[:,0])]
line_y = [model.predict(np.array([x**2])) for x in line_x]
pain(132,'x^2','y','translate coord & degress=2',X2[:,0],y[:,0],line_x,line_y)
x_min,x_max = min(X[:,0]),max(X[:,0])
line_x = [x_min+(x_max-x_min)*(i/100) for i in range(100)]
line_y = [model.predict(np.array([x**2])) for x in line_x]
pain(133,'x','y','degress=2',X[:,0],y[:,0],line_x,line_y)
plt.show()
非线性分类问题
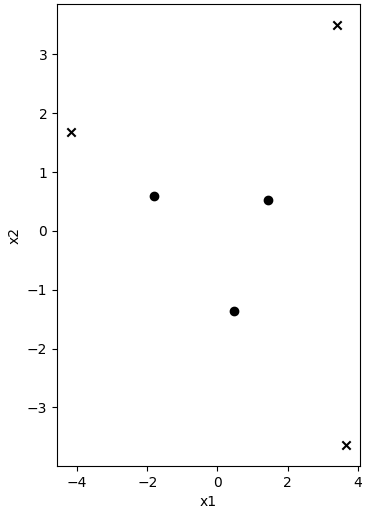
线性不可分的情况在分类问题中比比皆是,简单的不可分情况如下:
虽然问题类型不同,但是我们的解决思路是一致的,即通过特征转换将线性不可分问题转为线性可分;
针对上述数据分布,可以观察到不同类型的点距离中心点的距离差异很明显,圆点距离中心的距离很近,而叉叉距离中心的距离很远,如果能够构建一个表示该距离的特征,那么就可以基于该特征进行分类;
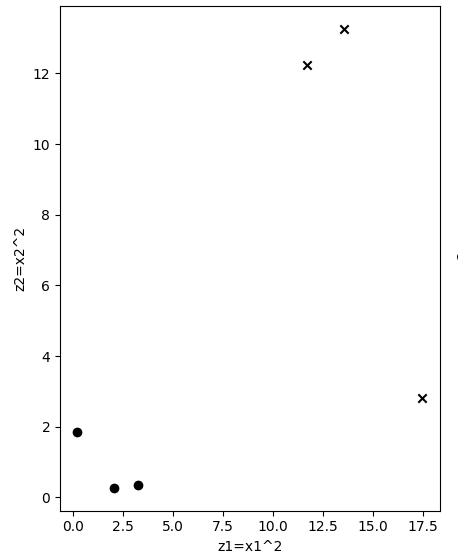
基于上述分析,通过欧氏距离公式计算点到原点的距离有:\(\sqrt{(x1-0)^2+(x2-0)^2}\),由于我们只是期望获得一个广义上的距离,并不严格要求是欧氏距离,因此将公式中的根号去掉也不影响对数据分布的改变,最后特征转换为将\(x_1\)转换为\(x_1^2\),同样的将\(x_2\)转换为\(x_2^2\),转换后的横纵坐标值之和就可以用于表示我们期望的距离;
代码实现
构建线性不可分数据集
X = np.array([[-1.8,0.6],[0.48,-1.36],[3.68,-3.64],[1.44,0.52],[3.42,3.5],[-4.18,1.68]])
y = np.array([1,1,-1,1,-1,-1])
直接运行感知机模型
model = Perceptron(X=X,y=y,epochs=100)
w,b = model.train()

特征转换及转换后的特征分布
Z = X**2 # z1=x1^2,z2=x2^2
在转换后的数据集上运行感知机
model = Perceptron(X=Z,y=y,epochs=100)
w,b = model.train()
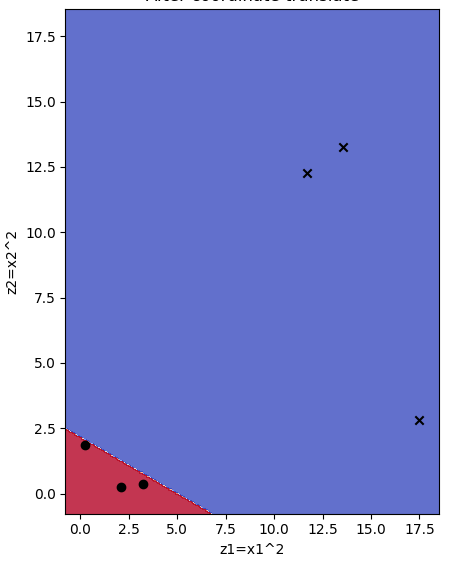
在原始坐标系下看感知机拟合的超平面
line_x = [(line_x[0]+(line_x[1]-line_x[0])*(i/100))**.5 for i in range(0,100)]
line_y = [((-b-w[0]*(x**2))/w[1])**.5 for x in line_x]

通过增加任意二阶以及小于二阶特征来拟合任意二次曲线
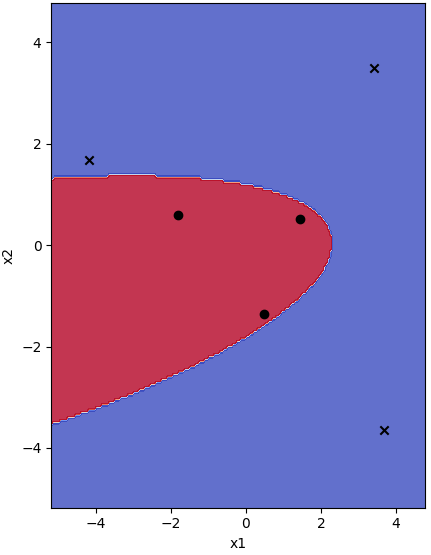
Z2 = np.array([[x[0]**2,x[1]**2,x[0]*x[1],x[0],x[1]] for x in X])
model = Perceptron(X=Z2,y=y,w=np.array([0,0,0,0,0]),epochs=100)
w,b = model.train()
完整代码
import numpy as np
import matplotlib.pyplot as plt
from 感知机口袋算法 import Perceptron
plt.figure(figsize=(18,6))
'''
通过坐标转换/特征转换将非线性问题转为线性问题,再使用线性模型解决;
'''
def trans_z(X):
return X**2
def trans_z2(X):
return np.array([[x[0]**2,x[1]**2,x[0]*x[1],x[0],x[1]] for x in X])
def pain(pos=121,title='',xlabel='',ylabel='',resolution=0.05,model=None,X=[],y=[],line_x=[],line_y=[],transform=None):
plt.subplot(pos)
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
xy_min = min(min([x[0] for x in X]),min([x[1] for x in X]))
xy_max = max(max([x[0] for x in X]),max([x[1] for x in X]))
xx1, xx2 = np.mgrid[xy_min-1:xy_max+1.1:resolution, xy_min-1:xy_max+1.1:resolution]
grid = np.c_[xx1.ravel(), xx2.ravel()]
if transform:
grid = transform(grid)
y_pred = np.array([model.predict(np.array(x)) for x in grid]).reshape(xx1.shape)
plt.contourf(xx1, xx2, y_pred, 25, cmap="coolwarm", vmin=0, vmax=1, alpha=0.8)
plt.scatter([xi[0] for xi,yi in zip(X,y) if yi==1],[xi[1] for xi,yi in zip(X,y) if yi==1],c='black',marker='o')
plt.scatter([xi[0] for xi,yi in zip(X,y) if yi==-1],[xi[1] for xi,yi in zip(X,y) if yi==-1],c='black',marker='x')
# plt.plot(line_x,line_y,color='black')
## 不可分
X = np.array([[-1.8,0.6],[0.48,-1.36],[3.68,-3.64],[1.44,0.52],[3.42,3.5],[-4.18,1.68]])
y = np.array([1,1,-1,1,-1,-1])
model = Perceptron(X=X,y=y,epochs=100)
w,b = model.train()
# 注意绘制分割直线公式为:wx+b=0,因此给定x[0],计算对应的x[1]即可画图
# w[0]*x[0]+w[1]*x[1]+b=0 => x[1]=(-b-w[0]*x[0])/w[1]
line_x = [min([x[0] for x in X])-3,max([x[0] for x in X])+3]
line_y = [(-b-w[0]*line_x[0])/w[1],(-b-w[0]*line_x[1])/w[1]]
pain(141,'Before coordinate translate','x1','x2',model=model,X=X,y=y)
## 转换坐标为可分
Z = X**2 # z1=x1^2,z2=x2^2,相当于对原数据空间做坐标系转换,也可以理解为特征转换
model = Perceptron(X=Z,y=y,epochs=100)
w,b = model.train()
line_x = [min([x[0] for x in Z])-3,max([x[0] for x in Z])+3]
line_y = [(-b-w[0]*line_x[0])/w[1],(-b-w[0]*line_x[1])/w[1]]
pain(142,'After coordinate translate','z1=x1^2','z2=x2^2',model=model,X=Z,y=y)
## 转换回原坐标绘制分割线,此时为曲线
line_x = [(line_x[0]+(line_x[1]-line_x[0])*(i/100))**.5 for i in range(0,100)]
line_y = [((-b-w[0]*(x**2))/w[1])**.5 for x in line_x]
pain(143,'Back to original coordinate','x1','x2',model=model,X=X,y=y,transform=trans_z)
## 使用任意二次曲线转换坐标:所有可能的二元二次方程
Z2 = np.array([[x[0]**2,x[1]**2,x[0]*x[1],x[0],x[1]] for x in X])
model = Perceptron(X=Z2,y=y,w=np.array([0,0,0,0,0]),epochs=100)
w,b = model.train()
# w0*x0^2+w1*x1^2+w2*x0*x1+w3*x0+w4*x1+b=0 => x1=-b-w3*x0-w0*x0^2
# line_x = [(line_x[0]+(line_x[1]-line_x[0])*(i/100))**.5 for i in range(0,100)]
# line_y = [((-b-w[0]*(x**2))/w[1])**.5 for x in line_x]
pain(144,'Back to original coordinate','x1','x2',model=model,X=X,y=y,transform=trans_z2)
plt.show()
最后
对于特征转换,可以应用的方法很多,本篇主要是以最简单的二次多项式进行转换,实际上对于更复杂的数据,需要进行更高阶的转换,当然也可以基于业务进行特征转换等等,通常这也是ML中非常消耗时间成本的一个步骤,也是对于最终结果影响最大的一步;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号