Spark Job-Stage-Task实例理解
Spark Job-Stage-Task实例理解
基于一个word count的简单例子理解Job、Stage、Task的关系,以及各自产生的方式和对并行、分区等的联系;
相关概念
- Job:Job是由Action触发的,因此一个Job包含一个Action和N个Transform操作;
- Stage:Stage是由于shuffle操作而进行划分的Task集合,Stage的划分是根据其宽窄依赖关系;
- Task:最小执行单元,因为每个Task只是负责一个分区的数据
处理,因此一般有多少个分区就有多少个Task,这一类的Task其实是在不同的分区上执行一样的动作;
例子代码
'''
DAG: Job vs Stage vs Task
'''
# 初始化spark环境
from pyspark import SparkContext,SparkConf
conf = SparkConf()
conf.setMaster('local').setAppName('Job vs Stage vs Task')
sc = SparkContext(conf=conf)
alpha_rdd1 = sc.parallelize(['a c','a b','b c','b d','c d'],10)
word_count1 = alpha_rdd1.flatMap(lambda a:a.split(' ')).map(lambda a:(a,1)).reduceByKey(lambda x,y:x+y)
alpha_rdd2 = sc.parallelize(['a c','a b','b c','b d','c d'],10)
word_count2 = alpha_rdd2.flatMap(lambda a:a.split(' ')).map(lambda a:(a,1)).reduceByKey(lambda x,y:x+y)
word_count1.join(word_count2).collect()
print('END')
input() # input是方便脚本运行不会终止导致web ui不能正常浏览
可以看到,主要的数据处理逻辑分为三部分,分别是两个word count,以及最后对两个结果的join,事实上这也对应了3个stage,下面是代码与stage的对应图,注意图中的并行关系:
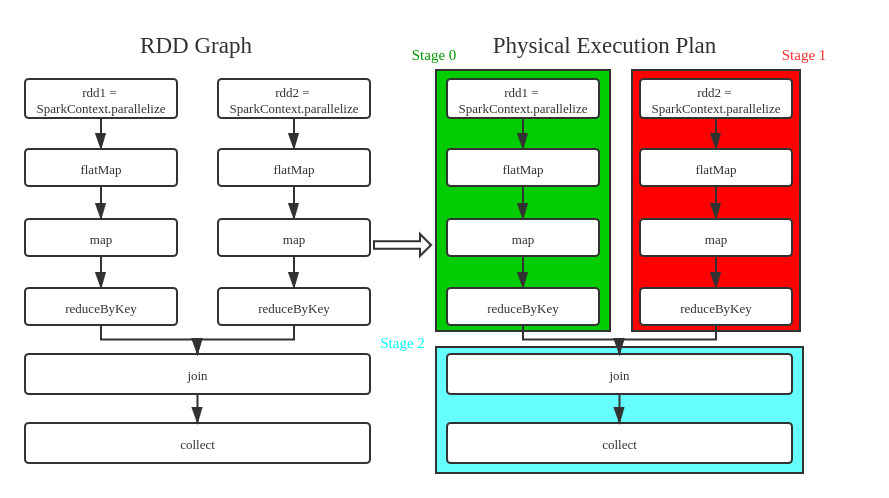
从图中可以看出,原代码只有一个action(collect),因此只有一个Job,这个Job被换分为3个Stage,划分原因是有shuffle出现(reductByKey),而明显看出的是Stage 0和Stage 1互相没有依赖关系,因此可以并行,而Stage 2则是依赖于0和1的,因此会最后一个执行;
Spark Web UI
下面通过Web UI来进一步查看Job、Stage、Task的关系;

从上图看到,只有一个已完成的Job,该Job包含3个Stage,30个Task(注意之前的代码里parallelize设置的分区数为10,3*10=30);

上图表示该Job的运行时间线图,可以明显的看到Stage0和Stage1在时间上有大部分重叠,也就是并行进行,而Stage2是在Stage1结束后才开始,因为Stage0结束的更早,这里对于依赖关系的展示还是很明显的;
另外,对于stage0和stage1,虽然处理的数据量很小,但是依然可以看出二者的运行时间比较接近,也就是没有明显的数据偏斜的情况出现,当然,这里因为只是测试数据,而真实场景下很容易出现个别stage执行时间远远超过其他的stage,导致整体的时间被拖长;

上图是该Job对应的DAG可视化图,它是直接的对Stage以及Stage间的依赖关系进行展示,也验证了我们之前的分析,这里每个Stage还可以继续点进去;

上图中可以更清晰的看到,每个Stage中都包含10个Task,其实就是对应10个partition,对于Stage0和Stage1,他们都是在shuffle前的Stage,因此他们都有Shuffle Write的动作,大小都是514,而Stage2则是join这两部分数据,因此有Shuffle Read动作,大小而前二者之和,也就是1028;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号