股票走势预测
想折腾一下股票了,整个预测的神经网络玩玩(仅参考,股票这东西说不准)
一、思路
RNN神经网络的特点在于:输出受到一个阶段的输入的影响,
x(t) -> RNN(t) -> y(t)
x(t + 1) -> RNN(t) + RNN(t + 1) -> y(t + 1)
相当于RNN在循环使用。股票这类数据量很大的情况下,如果使用卷积之类的神经网络,则每次输入量和计算量就很夸张了;RNN则可以将数据分解成很多小段,每段数据对之后的数据做预测
二、工具
主要有:
编程语言:python
框架:Keras+LSTM、matplotlib、sklearn、pandas
三、过程
1.数据
原始数据可以从这里获得:股票数据
这里简化了数据格式:时间戳+最高价格


timestamp,height 1531724100,8.730 1531724400,8.740 1531791300,8.750 1531791600,8.740 1531791900,8.720 1531792200,8.700 1531792500,8.720 1531792800,8.710 1531793100,8.690 1531793400,8.690 1531793700,8.700 1531794000,8.700 1531794300,8.690 1531794600,8.700 1531794900,8.700 1531795200,8.690 1531795500,8.700 1531795800,8.720 1531796100,8.730 1531796400,8.730 1531796700,8.730 1531797000,8.720 1531797300,8.710 1531797600,8.720 1531797900,8.710 1531798200,8.710 1531803900,8.710 1531804200,8.710 1531804500,8.710 1531804800,8.700 1531805100,8.710 1531805400,8.710 1531805700,8.700 1531806000,8.700 1531806300,8.700 1531806600,8.700 1531806900,8.700 1531807200,8.710 1531807500,8.710 1531807800,8.680 1531808100,8.690 1531808400,8.700 1531808700,8.700 1531809000,8.700 1531809300,8.720 1531809600,8.720 1531809900,8.720 1531810200,8.720 1531810500,8.720 1531810800,8.720 1531877700,8.800 1531878000,8.830 1531878300,8.850 1531878600,8.840 1531878900,8.810 1531879200,8.800 1531879500,8.800 1531879800,8.800 1531880100,8.790 1531880400,8.790 1531880700,8.810 1531881000,8.820 1531881300,8.820 1531881600,8.810 1531881900,8.800 1531882200,8.820 1531882500,8.830 1531882800,8.830 1531883100,8.820 1531883400,8.810 1531883700,8.800 1531884000,8.800 1531884300,8.800 1531884600,8.810 1531890300,8.810 1531890600,8.810 1531890900,8.800 1531891200,8.810 1531891500,8.810 1531891800,8.810 1531892100,8.800 1531892400,8.790 1531892700,8.780 1531893000,8.770 1531893300,8.770 1531893600,8.760 1531893900,8.750 1531894200,8.740 1531894500,8.740 1531894800,8.730 1531895100,8.730 1531895400,8.730 1531895700,8.720 1531896000,8.730 1531896300,8.730 1531896600,8.720 1531896900,8.710 1531897200,8.700 1531964100,8.770 1531964400,8.770 1531964700,8.780 1531965000,8.810 1531965300,8.790 1531965600,8.780 1531965900,8.780 1531966200,8.770 1531966500,8.770 1531966800,8.760 1531967100,8.770 1531967400,8.760 1531967700,8.770 1531968000,8.780 1531968300,8.780 1531968600,8.780 1531968900,8.790 1531969200,8.810 1531969500,8.790 1531969800,8.790 1531970100,8.780 1531970400,8.760 1531970700,8.760 1531971000,8.760 1531976700,8.760 1531977000,8.760 1531977300,8.750 1531977600,8.750 1531977900,8.750 1531978200,8.750 1531978500,8.750 1531978800,8.750 1531979100,8.750 1531979400,8.750 1531979700,8.750 1531980000,8.750 1531980300,8.730 1531980600,8.730 1531980900,8.730 1531981200,8.720 1531981500,8.730 1531981800,8.730 1531982100,8.730 1531982400,8.710 1531982700,8.710 1531983000,8.710 1531983300,8.710 1531983600,8.730 1532050500,8.730 1532050800,8.700 1532051100,8.690 1532051400,8.680 1532051700,8.640 1532052000,8.650 1532052300,8.650 1532052600,8.660 1532052900,8.650 1532053200,8.690 1532053500,8.690 1532053800,8.680 1532054100,8.750 1532054400,8.760 1532054700,8.730 1532055000,8.730 1532055300,8.730 1532055600,8.740 1532055900,8.730 1532056200,8.700 1532056500,8.700 1532056800,8.690 1532057100,8.690 1532057400,8.690 1532063100,8.680 1532063400,8.710 1532063700,8.730 1532064000,8.780 1532064300,8.820 1532064600,8.920 1532064900,8.960 1532065200,9.050 1532065500,9.090 1532065800,9.060 1532066100,9.050 1532066400,9.170 1532066700,9.150 1532067000,9.160 1532067300,9.200 1532067600,9.180 1532067900,9.200 1532068200,9.180 1532068500,9.140 1532068800,9.140 1532069100,9.160 1532069400,9.130 1532069700,9.130 1532070000,9.110 1532309700,9.080 1532310000,9.100 1532310300,9.090 1532310600,9.060 1532310900,9.060 1532311200,9.100 1532311500,9.100 1532311800,9.090 1532312100,9.100 1532312400,9.160 1532312700,9.130 1532313000,9.140 1532313300,9.250 1532313600,9.240 1532313900,9.240 1532314200,9.230 1532314500,9.190 1532314800,9.190 1532315100,9.180 1532315400,9.170 1532315700,9.210 1532316000,9.230 1532316300,9.220 1532316600,9.230 1532322300,9.290 1532322600,9.350 1532322900,9.370 1532323200,9.370 1532323500,9.330 1532323800,9.350 1532324100,9.340 1532324400,9.320 1532324700,9.330 1532325000,9.400 1532325300,9.390 1532325600,9.380 1532325900,9.360 1532326200,9.370 1532326500,9.370 1532326800,9.400 1532327100,9.430 1532327400,9.410 1532327700,9.420 1532328000,9.390 1532328300,9.390 1532328600,9.390 1532328900,9.450 1532329200,9.450 1532396100,9.500 1532396400,9.550 1532396700,9.550 1532397000,9.550 1532397300,9.590 1532397600,9.580 1532397900,9.580 1532398200,9.560 1532398500,9.490 1532398800,9.480 1532399100,9.470 1532399400,9.470 1532399700,9.460 1532400000,9.460
2.代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy import matplotlib.pyplot as plt import pandas import math from keras.models import Sequential from keras.models import load_model from keras.layers import Dense from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error # 分割数据集:每look_back分割一次,这段数据对其后的数据做预测 def create_dataset(dataset, look_back=1): dataX, dataY = [], [] for i in range(len(dataset) - look_back - 1): a = dataset[i:(i + look_back), 0] b = dataset[i + look_back, 0] dataX.append(a) dataY.append(b) return numpy.array(dataX), numpy.array(dataY) if __name__ == '__main__': numpy.random.seed(7) dataframe = pandas.read_csv('data.cvs', usecols=[1], engine='python') dataset = dataframe.values dataset = dataset.astype('float32') # 将数据压缩到0~1之间 scaler = MinMaxScaler(feature_range=(0, 1)) dataset = scaler.fit_transform(dataset) # 90%的数据作为训练,剩下的做为测试 train_size = int(len(dataset) * 0.9) test_size = len(dataset) - train_size train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :] # 每3个数据做一次分割,并对其后的数据做预测 look_back = 3 trainX, trainY = create_dataset(train, look_back) testX, testY = create_dataset(test, look_back) # 重新格式化训练和测试数据为(n,3,1)格式 trainX = numpy.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1)) testX = numpy.reshape(testX, (testX.shape[0], testX.shape[1], 1)) # 创建LSTM网络并训练 model = Sequential() # 创建LSTM模型,输入层包含一个神经元,隐藏层包含256个神经元 # input_shape为输入数据格式,模型第一层必须指定 model.add(LSTM(256, input_shape=(trainX.shape[1], trainX.shape[2]), return_sequences=True)) # 增加一个128个神经元的隐藏层 model.add(LSTM(128)) # 输出层一个神经元 model.add(Dense(1)) model.compile(loss='mean_squared_error', optimizer='adam') model.summary() # 训练网络 model.fit(trainX, trainY, nb_epoch=500, batch_size=1, verbose=2) model.save('lstm-predit.h5') # model = load_model('lstm-predit.h5') # 预测 trainPredict = model.predict(trainX) testPredict = model.predict(testX) # 预测值放大 trainPredict = scaler.inverse_transform(trainPredict) trainY = scaler.inverse_transform([trainY]) testPredict = scaler.inverse_transform(testPredict) testY = scaler.inverse_transform([testY]) # 评价预测 trainScore = math.sqrt(mean_squared_error(trainY[0],trainPredict[:,0])) print '训练 分数: %.2f RMSE' % (trainScore) testScore = math.sqrt(mean_squared_error(testY[0],testPredict[:,0])) print '测试 分数: %.2f RMSE' % (testScore) #绘制训练预测图 trainPredictPlot = numpy.empty_like(dataset) trainPredictPlot[:,:] = numpy.nan trainPredictPlot[look_back:len(trainPredict)+look_back,:] = trainPredict #绘制测试预测图 testPredictPlot = numpy.empty_like(dataset) testPredictPlot[:,:] = numpy.nan testPredictPlot[len(trainPredict)+look_back*2+1:len(dataset)-1,:] = testPredict plt.plot(scaler.inverse_transform(dataset)) plt.plot(trainPredictPlot) plt.plot(testPredictPlot) plt.show()
贴一个结果图
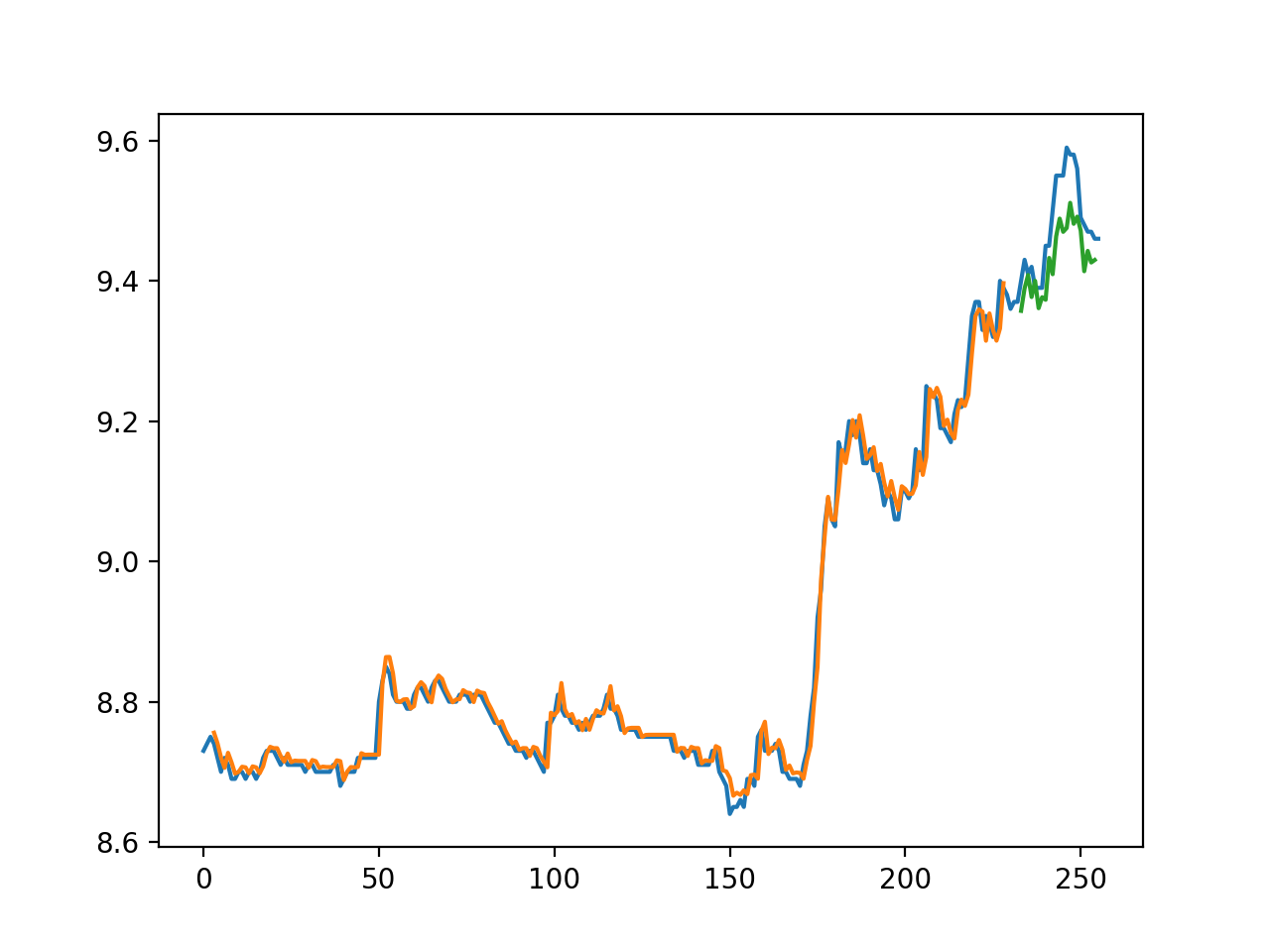
训练集的预测误差:0.02 RMSE
测试集的预测误差:0.06 RMSE
这里的数据量比较少,结果也就那么回事;具体问题具体分析吧~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号