
下载编译运行PaddleOCR版本4
为什么要编译 PaddleOCR 版本4
我原来使用的是https://github.com/PaddlePaddle/PaddleOCR这个项目里deploy/android_demo里面的模型,但是这个模型在识别一部分金额的时候会出现问题,比方说将 5,000.00 识别为 5000.0o 或 5000.om,导致我写安卓业务代码很难写。
deploy/android_demo里面的模型是版本2的,现在最新的模型是版本4,新模型比老模型大了很多,预测耗时会久点,效果也会好点。我是试验完写这篇博客的,版本4的模型已经可以很好识别出 5,000.00 这个金额字符串了。
因此我写本文,记录一下自己下载编译运行 PaddleOCR 版本4的过程,以便其他有需要的人也可以照着我的步骤轻松获取一个较好版本的 PaddleOCR 模型。
下载、编译、运行
下载代码
访问https://github.com/PaddlePaddle/PaddleOCR,搜索低代码全流程开发,然后跳转链接所在的网页,在 2.OCR相关能力支持那里,点击端侧部署(我是在安卓App上部署飞桨OCR的,所以选择端侧部署)

至此打开了PaddleX端侧部署 demo 使用指南,首先找到填写ocr(文字识别)问卷链接,点进去填写问卷获取最新的ocr代码

找台海外的服务器,拉取PaddleX-Lite-Deploy工程
# 切换代码目录
cd /root/code
# 克隆 Paddle-Lite-Demo 仓库的 feature/paddle-x 分支到 PaddleX-Lite-Deploy 目录
git clone -b feature/paddle-x https://github.com/PaddlePaddle/Paddle-Lite-Demo.git PaddleX-Lite-Deploy
# 切换到指定解压目录
cd PaddleX-Lite-Deploy/ocr/android/shell/ppocr_demo
# 获取OCR压缩包,并解压(解压密码见问卷调查后显示的内容)
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/lite/paddle_lite_demo_code/ocr.zip
unzip ocr.zip
下载 NDK
然后去https://github.com/android/ndk/wiki/Unsupported-Downloads查找linux r21版本的NDK下载地址,用海外服务器下载它
# 切换软件目录
cd /root/soft
# 下载 linux r21 NDK,用更新的版本会报链接错误
wget https://dl.google.com/android/repository/android-ndk-r21e-linux-x86_64.zip
# 解压压缩包
unzip android-ndk-r21e-linux-x86_64.zip
# 解压完毕之后 /root/soft/android-ndk-r21e 就是 NDK_ROOT 了,这个路径后面编译的时候需要修改
下载依赖
# 切换代码目录
cd /root/code
# 下载 Paddle Lite 预测库
cd PaddleX-Lite-Deploy/libs
sh download.sh
# 下载 paddle_lite_opt 工具优化后的模型、测试图片和标签文件等
cd ../ocr/assets
sh download.sh
编译代码
# 切换代码目录
cd /root/code
# 进入 ocr demo 目录
cd PaddleX-Lite-Deploy/ocr/android/shell/ppocr_demo
# 修改一下 build.sh,把 NDK_ROOT 写对,比如我这边是 /root/soft/android-ndk-r21e
# 再修改一下 src/CMakeLists.txt,把 CMAKE_SYSTEM_NAME 设置为 linux,好像默认就是,也不用改了
sh build.sh
# 注意,如果 NDK 版本不是 21 就会报链接错误
至此编译成功
运行 demo
# 进入代码目录
cd /root/code
# 拷贝运行 OCR 程序所需要的资源
cd PaddleX-Lite-Deploy/ocr/android/shell/ppocr_demo
cp -r ../../../assets/config.txt ./ppocr_demo
cp -r ../../../assets/labels ./ppocr_demo
cp -r ../../../assets/images ./ppocr_demo
cp -r ../../../assets/models ./ppocr_demo
# 压缩 ppocr_demo 目录,我习惯用 7z,各位可以用自己擅长的压缩软件压缩
7za a ppocr_demo.7z ppocr_demo/
# 将 ppocr_demo.7z 拷贝回本地
# 解压 ppocr_demo.7z
进入 ppocr_demo 目录,打开命令行
# 查看当前连接的手机
adb devices
# 运行 OCR
## 把解压后的文件夹拷贝到手机上
adb push ./ppocr_demo /data/local/tmp/
## 进入手机
adb shell
cd /data/local/tmp/ppocr_demo
chmod +x ./ppocr_demo
export LD_LIBRARY_PATH=/data/local/tmp/ppocr_demo:${LD_LIBRARY_PATH}
./ppocr_demo \
./models/PP-OCRv4_mobile_det.nb \
./models/PP-OCRv4_mobile_rec.nb \
./models/ch_ppocr_mobile_v2.0_cls_slim_opt.nb \
./images/test.jpg \
./test_img_result.jpg \
./labels/ppocr_keys_v1.txt \
./config.txt
最终运行结果如下
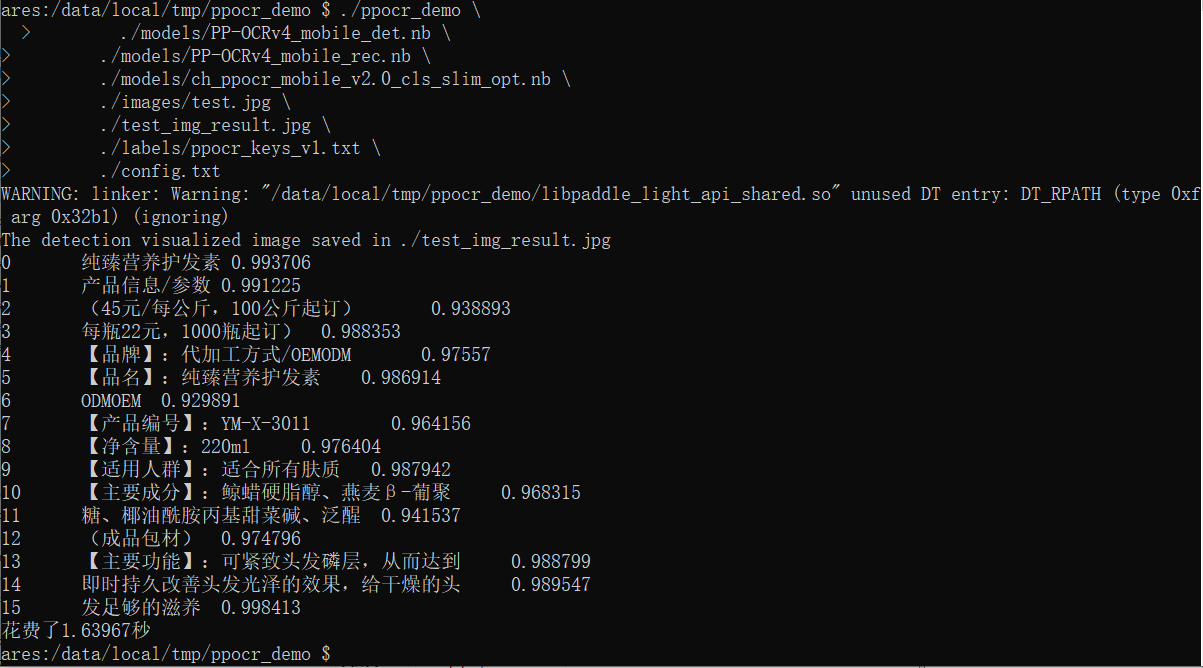
可以自己替换图片再运行,看看效果。我试过,版本2识别不出来的5000.00,版本4能正常识别,效果挺好。后续将它放到我的拍照记账app中来

 浙公网安备 33010602011771号
浙公网安备 33010602011771号