
C++ 泛型算法详解(上)
泛型算法
文章目录
1. 概述:
泛型算法:实现了一些经典算法的公共接口,可以用于不同类型的元素和容器类型。
include < algorithm > 头文件
find 算法:用来查找第一个符合条件的元素,用两个迭代器作为范围。
find不仅可以查找容器,也可以适用于内置数组
只要有一个迭代器可用来访问元素,find就完全不依赖于容器类型(或数组)。
- 利用find查找某个元素
int ia[]{ 1,2,3,4,5,6 };
int val = 5;
int* p = find(begin(ia), end(ia), val);
cout << *p << endl;
- 利用count计算某个元素出现的次数
vector<string> a;
string temp;
while (cin >> temp && temp != "quit")
{
a.push_back(temp);
}
auto num = count(begin(a), end(a), "woaini");
cout << num << endl;
关键概念:算法永远不会执行容器的操作!!!
算法只会运行于迭代器之上,永远不能做插入删除容器元素的相关操作,当想要完成这样的操作时,应该使用特殊的迭代器进行(后面会讲到,叫做插入器)。
2. 初识泛型算法
只读算法
只读取,不改变范围的元素:find count accumulate(求和算法)
-
accumulate求和算法
accumulate 计算在一个迭代器范围的元素之和,第三个参数为求和的初始值,同时指定和的类型
示例:读取字符串,并且字符串相加+连接起来,注意此处创建一个string空串,不能直接用 " ",因为" "是字符串字面值,const char*类型而不是string类型,它没有 + 运算符。利用cbegin和cend表示只读。auto num = accumulate(cbegin(a), cend(a), string(""));计算容器内每个元素的和,注意:如果类型不匹配,可能会出现截断现象(double -> int)
vector<int> a{ 1,2,3,4,5,6 }; cout << accumulate(cbegin(a), cend(a), 0) << endl; //指定初始值为0,自动推断int;如果为1.5,则是和是double类型,并且初始值1.5在求和 -
equal操作两个序列的迭代器
equal:比较两个序列是否保存相同的值,接受三个迭代器:前两个为第一个迭代器的范围,后一个为第二个序列的首迭代器。
示例:比较不同容器的元素是否相等,注意:第二个序列长度至少要等于第一个序列的长度,如果少于第一个序列,则会报错。当然也可以是string和const char的比较,甚至两个const char ,因为它是一个范围。
vector<int> a{ 1,2,3,4,5,6 }; list<int> b{ 1,2,3,4,5,6}; //可以是不用类型的容器 auto fg = equal(cbegin(a), cend(a), cbegin(b)); cout << fg << endl;
可写算法
算法利用迭代器来实现对容器的写操作,而自身不可能改变容器。
-
fill 写算法
fill 接受迭代器范围与一个准备赋予的值。
vector<int> a(10); fill(begin(a), end(a), 1); //容器初识化值为 1 -
算法中接受两个序列的操作都可以是两个不同类型的容器元素,如果第二个序列只为一个首迭代器,则必须保证长度至少要与第一个序列一样长。也可以接受两个迭代器的范围。
-
fill_n 向目标位置写入数据
fill_n 接受一个单迭代器(指向的元素起始位置),一个计数值,一个赋予的值。
示例:包含5个元素的vector,使用fill_n指定把5个元素的值设置为0.
vector<int> a(5); fill_n(begin(a), 5, 0);要注意赋予的元素个数不要超过容器的大小,否则会崩溃,可以使用容器的size成员函数来获取容器的元素个数
vector<int> a(99); fill_n(begin(a), a.size(), 55); //99个元素全部设置为55算法不会检查写操作!!
-
back_inserter 插入迭代器
头文件 iterator。
back_inserter接受一个指向容器的引用,返回与该容器绑定的插入迭代器
示例:利用插入迭代器为容器赋值,也可以与fill_n一起使用。
vector<int> a; auto it = back_inserter(a); *it = 55; //为插入迭代器赋值就是为容器赋值 vector<int> a; //利用插入迭代器为容器添加元素并赋值 fill_n(back_inserter(a), 100, 10); //先创建100个元素对象,在赋值为10 -
copy 拷贝算法
copy接受三个参数,一个拷贝的起始迭代器序列,一个目标迭代器位置。
示例:a的范围元素拷贝到b容器,注意:b的范围至少要与a一样大,否则崩溃。
vector<double> a{ 1.5,2,3,4,5,6,7,8,9,10,11,66,99,555 }; list<int> b(a.size()); //获取a的大小与b一样大 //可以是不同类型的容器 auto x = copy(cbegin(a), cend(a), begin(b)); //返回的x为指向b拷贝后的超尾迭代器 -
replace与replace_copy算法
replace接受一个范围,一个搜索值,一个新值:将目标序列中的所有搜索值修改为指定的值。
replace_copy可以接受一个即将保存的位置。
示例:将a的所有5修改为666,并且使用插入迭代器来直接修改b容器。
vector<double> a{ 1.5,2,3,4,5,6,7,8,5,10,11,5,5,5 }; list<int> b; //可以是不同类型的容器 replace_copy(cbegin(a), cend(a), back_inserter(b), 5, 666);
重排容器元素的算法
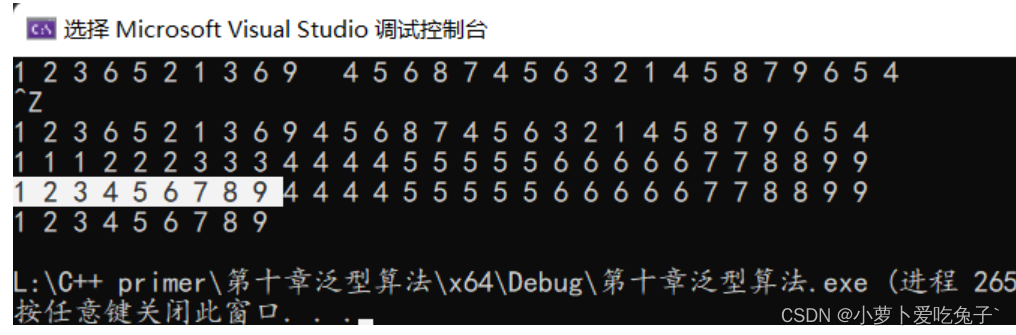
消除重复的单词
使用vector读取一系列string的单词,如何消除vector容器中重复的string单词?
sort函数:给指定范围的元素排序。
unique函数: "消除"重复的单词,注意必须要是相邻的,但是并未完全消除,可以理解为把相邻的元素只留下一个,剩下的都放在了尾部,然后unique返回一个指向没有重复元素的下一个位置的迭代器。
erase函数: 彻底删除元素,接受一个范围,删除元素。
示例:sort ---->> unique ---->>erase
vector<string> a;
string temp;
while (cin >> temp)
{
a.push_back(temp);
}
//先排序
sort(begin(a), end(a));
//再消除
auto it=unique(begin(a), end(a));
//最后删除
a.erase(it, a.end());
程序在无重复的情况下也是正常的
一个图例: 分别是sort unique erase的情况
简单总结
本节函数:find()搜索,accmulate()求和,equal()相等判断,fill()、fill_n()赋值,back_insert()插入操作,copy()拷贝,sort()排序,unique()重排并消重复
3. 定制操作
3.1 向算法传递函数
谓词的概念:谓词是一个可调用的表达式,返回结果是一个能用做条件的值。
一元谓词:接受单一参数
二元谓词:接受两个参数
示例:我们使用单词的长度来排序sort函数,而不是字母的顺序(sort接受二元谓词)
sort(begin(a), end(a), isShorter); //排序函数
bool isShorter(const string& s1, const string& s2)
{
return s1.size() < s2.size();
}
- stable_sort函数:维持相等元素顺序的情况下,按长度排序
如果不调用stable_sort:则sort unique erase只负责删除重复并且按字母顺序排序,再次调用stable_sort是的可以保持字母顺序并且按照单词的长度排序。
原三个函数的调用结果:

vector<string> a{ "two","ab","yu","pp","gh","dawbiesfnos","so","danidnwfiafdawadadadaw" };
//先排序
sort(begin(a), end(a));
//再消除
auto it = unique(begin(a), end(a));
//最后删除
a.erase(it, a.end());
//维持顺序
stable_sort(begin(a), end(a), isShorter);
调用了stable_sort之后:

-
partition函数:接受一个谓词,对容器内容进行划分,谓词为true 的排在前面,谓词为false的排在后面,返回一个指向最后一个谓词为true的下一个位置
示例: 返回字符串中长度大于等于5的字符串
vector<string> words{ "abcde","oiodwa","cenjd","66","yt","hhg","envisenvesv","uiytr" }; auto it=partition(words.begin(), words.end(), isfive); for (auto iter = words.cbegin(); iter != it; ++iter) { cout << *iter << '\t'; } bool isfive(const string& s1) { return s1.size() >= 5; }
注意:一元谓词和二元谓词的区别
3.2 lambda表达式
引入: 编一函数:查找并计算有多少个字符串大于某个长度,但是这个长度由我们自己输入
void Biggest(vector& words, vector::size_type sz)
{
//删除重复元素,按照字典序排序
elimDups(words);
//按长度再排序
stable_sort(words.begin(), words.end(), isShorter);
//接下来该怎么做???
}我们可以使用find_if函数:接受一个范围和一个一元谓词,但是,当我们传递给一个谓词字符串和长度时,它是二元谓词,我们无法编写传递两个参数的谓词给find_if函数。
lamdba的结构
-
我们可以向一个算法传递一个任意类别的可调用对象。
-
lamdba表达式:表示一个可调用的代码单元,可以理解为一个未命名的内联函数。
-
lamdba表达式具有返回类型,参数列表,函数体;但与函数不同,lamdba可以定义在函数内部。
lamdba结构: [局部变量](参数列表)->返回类型 {函数体}
-
可以忽略参数列表和返回类型,但是一定要包含捕获列表(通常为空)和函数体。
-
定义:f 为一个可调用对象,返回42,但是他不接受任何参数。
auto f = [] {return 42; }; -
调用:
cout << f() << endl; //返回42 -
如果lamdba未指定返回类型,则返回void
向lamdba传递参数
注意事项:
- 调用lamdba的实参和形参必须匹配
- lamdba不能有默认参数
- 一个lamdba的实参和形参数目永远相等
//与isShorter函数相同任务的lamdba表达式
[](const string& a, const string& b) {return a.size() > b.size(); }
空捕获,表示未使用任何局部变量
使用lamdba来调用stable_sort函数:
//按长度排序,长度相同按字母顺序
stable_sort(a.begin(), a.end(), [](const string& a, const string& b) {return a.size() > b.size(); });
使用捕获列表
传递给find_if一个可调用表达式: sz为某一个指定的长度,判断字符串长度是否大于sz。
[sz](const string& s){return s.size()>sz;};
捕获列表[sz],指明了lamdba即将会使用这些变量,只有捕获才可以在函数体使用!
调用find_if 查找
获取一个 迭代器,指向第一个满足长度大于指定长度的字符串的位置:
auto it=find_if(words.begin(),words.end(),[sz](const string& s){return s.size()>sz;});
返回了下一个位置的迭代器,然后再计算从现在在末尾有多少个元素(已经排序完毕!).
auto count=words.end()-it; //返回个数
for_each 打印算法
捕获列表为空,调用cout打印,it此时指向符合条件的第一个元素,打印到末尾的元素。
for_each(it,words.end(),[](const string& s){cout<<s<<" "};);
捕获列表只用与具备非static,lamdba可以直接使用static变量,和在函数外声明的名字。
简单总结:
输入字符串到vector容器中,指定一个长度sz,计算所有长度大于sz的字符串元素数量之和
void Biggest(vector<string>& words, vector<string>::size_type sz)
{
//删除重复元素,按照字典序排序
elimDups(words);
//按长度再排序
stable_sort(words.begin(), words.end(), isShorter);
//找到符合条件的第一个元素
auto it = find_if(words.begin(), words.end(), [sz](const string& s) {return s.size() >= sz; });
//获取元素个数
auto count = words.end() - it;
//打印
for_each(it, words.end(), [](const string& s) {cout << s; });
}
使用stable_partition替代find_if:为true在前,false在后,保持原有顺序。
void Biggest(vector<string>& words, vector<string>::size_type sz)
{
//删除重复元素,按照字典序排序
elimDups(words);
//按长度再排序
stable_sort(words.begin(), words.end(), [](const string& a, const string& b) {return a.size() < b.size(); });
for_each(words.begin(), words.end(), [](const string& s) {cout << s << " "; });
//符合条件在前面,不复合条件在后面
auto itNotfir=stable_partition(words.begin(), words.end(), [sz](const string& s) {return s.size() >=sz; });
//返回第一个不符合条件的位置
//获取元素个数
auto count = itNotfir - words.begin();
cout << "有" << count << "个元素大于等于" << sz << endl;
//打印
for_each(words.begin(),itNotfir, [](const string& s) {cout << s<<" "; });
}
3.3 lamdba的捕获与返回
当向一个函数传递一个lamdba时,同时定义了一个新类型和该类型的一个对象,传递的参数就是编译器生成的一个该类型的未命名对象。
值捕获
前提:变量可以拷贝。
被捕获的变量在lamdba创建时就拷贝,而不是调用时拷贝。
size_t a = 50;
auto f = [a] {return a; }; //创建时捕获
a = 10; //更改不会改变已经捕获完的lamdba
cout << f() << endl; //50
引用捕获
捕获时,采用的是与对象所绑定的引用。必须要保证在lamdba存在时,变量也要一直存在。
size_t a = 50;
auto f = [&a] {return a; };
a = 10;
cout << f() << endl; // 10
应当尽量避免捕获引用 指针 或迭代器
隐式捕获
让编译器自动推断捕获的类型:[&] :引用捕获, [=]:值捕获。
示例:
void func2(vector<string>& words, vector<string>::size_type sz, ostream& os = cout, char c = ' ')
{
// os隐式捕获:引用捕获方式 c显式捕获:值捕获方式
for_each(words.begin(), words.end(), [&, c](const string& s) {os << s << c; });
// os显式捕获:引用捕获方式 c隐式捕获:值捕获方式
for_each(words.begin(), words.end(), [=,&os](const string& s) {os << s << c; });
}
注意:采用混合的方式时,[]中第一个元素一定是& 或者 =,指明了默认捕获方式为值还是引用。
[&,c]:隐式捕获方式是**&,则显式捕获一定是值方式**。
[=,&]:隐式捕获方式是**=,则显式捕获一定是引用方式**。
可变lamdba
对于值捕获,默认情况下,对于被值拷贝的变量,lamdba不会改变其值,如果我们希望改变一个被捕获的变量的值,可以加上mutable关键字
auto v1 = 50;
auto f = [v1]()mutable {return ++v1; };
v1 = 0;
cout << f() << endl; // 51
对于引用捕获,能否改变其值依赖于引用指向的是一个const类型还是非const类型
size_t v1 = 50; //非const变量 可以修改
//const size_t a=50; //无法修改
auto f = [&v1]()mutable {return ++v1; }; //引用拷贝
v1 = 0;
cout << f() << endl; // 51
指定lamdba返回类型
如果一个lamdba包含return语句之外的任何语句,都假定此lamdba返回void。
示例:利用transform算法和lamdba表达式来将每个负数转换为其绝对值:
transform:接受一个迭代器范围,一个目标位置(可以是其本身的位置),一个可调用对象。
int ar[] = { -1,-2,-3,-4,-5,-6,9,8,7,4,-5 };
transform(begin(ar), end(ar), begin(ar), [](int& i) {return (i < 0) ? -i : i; });
for_each(cbegin(ar), cend(ar), [](const int& a) {cout<<a<<" "; });
无需指定返回类型,可以根据条件运算符的类型 推断出来。
此题不能使用if else的形式,因为其包含了return之外的其他语句,假定为void,但是其为int类型。
-
显式指定返回类型:使用 -> 尾置返回类型 来显式指出。
transform(begin(ar), end(ar), begin(ar), [](int i)->int {if (i < 0)return -i; else return i; });
简单总结:
本小节的相关泛型算法:
stable_sort()排序时相等长度元素维持原有顺序;
partition()对容器进行划分,返回最后一个使谓词为真的元素的后一个位置的迭代器;
stable_partition()同partition,但是保持原有顺序,和stable_sort一样。
find_if()查找第一个特定的元素
transform()改变容器的元素属性
3.4 参数绑定
bool check_size(const string& str,string::size_type sz)
{
return str.size()>sz;
}
find_if 必须接受一个一元谓词来使用,所以我们不能像上述代码一样传递给find_if,而可以使用lamdba生成一个可调用对象,通过参数捕获长度,来比较每个string字符串。有没有别的方法,不使用lamdba表达式呢?
bind函数
bind:接受一个可调用对象,生成一个新的可调用对象来适应原对象的参数列表
形式: auto newCallable=bind(callable,arg_list);
当我们调用newCallable时,会调用callable,并传递给他arg_list中的参数。
arg_list:包含_n的名字,n是个整数,表示占位符,用来指定它是newCallable的第几个参数。
绑定函数的参数
check_size:原调用对象。
_1:表示生成的新的调用对象接受的参数数量:只接受一个参数,类型是原调用对象的类型,即const string&
auto check6 = bind(check_size, placeholders::_1, 6);
生成的新的check6函数,只接受一个string类型的参数,并用此string和6来调用check_size函数
using namespace std::placeholder; //_1命名空间
string s{ "woaini" };
auto b1 = check6(s); //调用check_size(s,6)
find_if(words.begin(), words.end(), bind(check_size, _1, sz));
命名空间:using std::placeholders::_1。
bind的参数
auto g=bind(func,a,b,_2,c,_1);
生成了一个新的的可调用对象g,g包含两个参数,分别是第3和第5个;func原调用对象的第一,第二,第四个参数分别被绑定到a,b,c上。
bind调用会使:g( _1, _2)映射为(a,b,__2,c, __1);
绑定引用参数:
ostream& print(ostream & os, const string & s, char c)
{
return os << s << c;
}
//错误,不能拷贝os对象
for_each(words.begin(), words.end(), bind(print, os, _1, ' '));
//传递一个对象而不拷贝它:ref()
for_each(words.begin(), words.end(), bind(print, ref(os), _1, ' '));
说实话这个bind我没有看懂,等以后在总结吧。
本文来自博客园,作者:hugeYlh,转载请注明原文链接:https://www.cnblogs.com/helloylh/p/17209737.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号