
C++ 哈希表的总结与例题
文章目录
C++STL
c++的STL为我们提供了哈希集合和哈希映射。
哈希集合
- set
set基于红黑树实现,红黑树具有自动排序的功能,因此set内部所有的数据,在任何时候,都是有序的。
- unordered_set
unordered_set基于哈希表,数据插入和查找的时间复杂度很低,几乎是常数时间,而代价是消耗比较多的内存,无自动排序功能。底层实现上,使用一个下标范围比较大的数组来存储元素,形成很多的桶,利用hash函数对key进行映射到不同区域进行保存。
哈希映射
- map
1、优点:
(1)有序性,这是map结构最大的有点,其元素的有序性在很多应用中都会简化很多的操作。
(2)红黑树,内部实现一个红黑树使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高。
2、缺点:空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间。
3、适用处:对于那些有顺序要求的问题,用map会更高效一些。
2.unordered_map
1、优点:因为内部实现了哈希表,因此其查找速度非常的快。
2、缺点:哈希表的建立比较耗费时间
3、适用处:对于查找问题,unordered_map 会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
本文主要使用unordered_set与unordered_map。
哈希表
unordered_set的使用:
//1. 创建哈希集合
unordered_set<int> s;
//2. 插入元素
s.insert(1);
s.insert(5);
s.insert(4);
s.insert(9); //注意: unordered_set无自动排序功能!!!
//3. 统计元素个数
s.count(4);
//4. 查询元素
auto it = s.find(4);//注意:返回此元素位置的迭代器
//5. 删除元素
s.erase(9);
unordered_map的基本操作:
//1. 创建哈希集合
unordered_map<int,int> s;
//2. 插入元素 使用这两种方式
s.insert(make_pair(1, 2));
s.insert(make_pair(2, 5));
s[4] = 9;
s[6] = 10;
//3. 统计元素个数
s.count(4);
//4. 查询元素
auto it = s.find(4);
//5. 删除元素
s.erase(9);
//6. unordered_map存储的是一个pair类型;
//pair的first指向键,second指向值,pair的first和second构成了哈希映射的《键值对》
for (auto& x : s)
{
//访问每一个元素
cout << x.first << " " << x.second << endl;
}
//可以直接访问键值对
cout << s[7] << s[6] << endl;
设计哈希集合
不使用任何内建的哈希表库设计一个哈希集合(HashSet):
实现 MyHashSet 类:
void add(key) 向哈希集合中插入值 key 。
bool contains(key) 返回哈希集合中是否存在这个值 key 。
void remove(key) 将给定值 key 从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
#define MAX_NUM 100000
class MyHashSet {
private:
vector<int> arr[MAX_NUM];
public:
MyHashSet() {
}
void add(int key) {
int index = getindex(key); //获取集合索引
int pos = getpos(key, index); //获取桶位置
if (pos < 0)
{
arr[index].emplace_back(key);
}
}
void remove(int key) {
int index = getindex(key);
int pos = getpos(key, index);
if (pos >= 0)
{
//存在此元素,则删除
arr[index].erase(arr[index].begin() + pos);
}
}
bool contains(int key) {
int index = getindex(key);
int pos = getpos(key, index);
if (pos >= 0)
{
return true;
}
return false;
}
private:
int getindex(int key)
{
return key % MAX_NUM;
}
int getpos(int key, int index)
{
int n = arr[index].size();
for (int i = 0; i < n; i++)
{
if (arr[index][i] == key)
{
return i;
}
}
return -1;
}
};
设计哈希映射
不使用任何内建的哈希表库设计一个哈希映射(HashMap)。
实现 MyHashMap 类:
MyHashMap() 用空映射初始化对象
void put(int key, int value) 向 HashMap 插入一个键值对 (key, value) 。如果 key 已经存在于映射中,则更新其对应的值 value 。
int get(int key) 返回特定的 key 所映射的 value ;如果映射中不包含 key 的映射,返回 -1 。
void remove(key) 如果映射中存在 key 的映射,则移除 key 和它所对应的 value 。
class M_MyHashMap {
private:
pair<int, int> elem;
vector<pair<int, int>> map[MAX_NUM];
public:
M_MyHashMap() {
}
void put(int key, int value) {
int index = getindex(key);
int pos = getpos(key, index);
if (pos < 0)
{
map[index].emplace_back(make_pair(key, value));
}
else
{
map[index][pos].second = value;
}
}
int get(int key) {
int index = getindex(key);
int pos = getpos(key, index);
if (pos < 0)
{
return -1;
}
else
{
return map[index][pos].second;
}
}
void remove(int key) {
int index = getindex(key);
int pos = getpos(key,index);
if (pos >= 0)
{
map[index].erase(map[index].begin() + pos);
}
}
private:
int getindex(int key)
{
return key % MAX_NUM;
}
int getpos(int key, int index)
{
int n = map[index].size();
for (int i = 0; i < n; i++)
{
if (map[index][i].first == key)
{
return i;
}
}
return -1;
}
};
哈希集合
例题一:只出现一次的数字
一个数组会出现重复的元素,找出那个只出现了一次的元素
int singleNumber(vector<int>& nums) {
unordered_set<int> s;
for (auto& x:nums)
{
if (s.count(x))
{
//已经存在,则出现两次,则删除此元素
s.erase(x);
}
else
{
//没有进入上面的循环,说明只出现了一次
s.insert(x);
}
}
//最后剩下的一定是只出现一次的,因为出现多次的都被删除了
return *s.begin();
}
例题二:快乐数
一个数字各位的数字平方后相加,等于1则是快乐数,如果进入无限循环则不是快乐数
int getnum(int num)
{
int sum=0;
while (num)
{
sum+=((num%10)*(num%10));
num/=10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> s;
//当 n 不等于 1 或者集合里没有出现此元素时,循环继续
while (n!=1 && !s.count(n))
{
//集合每次都存储n的当前值,判断是否有重复元素
s.insert(n);
n=getnum(n);
}
//循环结束,说明1. n=1 -> true 2.有重复元素 -> false
return n==1;
}
哈希映射
例题一:两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> m;
int n=nums.size();
for (int i=0;i<n;i++)
{
//如果 目标元素减当前元素的结果存在,则哈希映射中存在此元素
if (m.count(target-nums[i]))
{
//返回当前下标 i 和对应相减结果的map中的下标
return {i,m[target-nums[i]]};
}
//映射进map
m[nums[i]]=i;
}
return {};
}
例题二:两个列表的最小索引总和
假设 Andy 和 Doris 想在晚餐时选择一家餐厅,并且他们都有一个表示最喜爱餐厅的列表,每个餐厅的名字用字符串表示。
你需要帮助他们用最少的索引和找出他们共同喜爱的餐厅。 如果答案不止一个,则输出所有答案并且不考虑顺序。 你可以假设答案总是存在。
vector<string> findRestaurant(vector<string>& list1, vector<string>& list2) {
unordered_map<string,int> m;
int n1=list1.size();
for (int i=0;i<n1;i++)
{
m[list1[i]]=i;
}
int n2=list2.size();
vector<string> res;
int minIdx=INT_MAX;
for (int i=0;i<n2;i++)
{
if (m.count(list2[i]))
{
string str=list2[i];
//计算当前下标
int idx=i+m[str];
if (idx<minIdx)
{
//当前下标小于最小下标,则更新res中字符串的值和minIdx
res.clear();
res.push_back(str);
minIdx=idx;
}
else if (idx==minIdx)
{
//两个下标相等,则也是他们两个都喜欢的
res.push_back(str);
}
}
}
return res;
}
例题三:字符串中的第一个唯一字符
返回字符串中第一个只出现一次的字符的位置
abcdcbd : 返回 0
int firstUniqChar(string s) {
unordered_map<char,int> m;
for (auto& x:s)
{
//存储字符及其出现次数
m[x]++;
}
int n=s.size();
for (int i=0;i<n;i++)
{
if (m[s[i]]==1)
{
return i;
}
}
return -1;
}
设置键
例题一:字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string,vector<string>> m;
for (auto& x:strs)
{
string s=x;
sort(s.begin(),s.end());
m[s].push_back(x);
}
vector<vector<string>> res;
for (auto& x:m)
{
res.push_back(x.second);
}
return res;
}
例题二:寻找重复的子树
给你一棵二叉树的根节点 root ,返回所有 重复的子树 。
对于同一类的重复子树,你只需要返回其中任意 一棵 的根结点即可。
如果两棵树具有 相同的结构 和 相同的结点值 ,则认为二者是 重复 的。
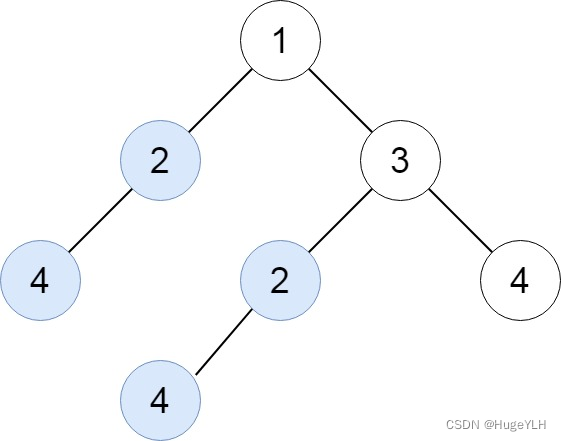
class Solution {
private:
unordered_map<string,TreeNode*> m;
unordered_set<TreeNode*> s;
public:
vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {
func(root);
return {s.begin(),s.end()};
}
string func(TreeNode* root)
{
if (root==nullptr)
{
return "";
}
else
{
string str=to_string(root->val)+"("+
func(root->left)+")("+func(root->right)+")";
auto it=m.find(str);
if (it!=m.end())
{
//不存在于m中,s添加
s.insert(it->second);
}
else
{
m[str]=root;
}
return str;
}
}
};
本文来自博客园,作者:hugeYlh,转载请注明原文链接:https://www.cnblogs.com/helloylh/p/17209662.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号