Hadoop集群环境搭建
(1)、在虚拟机中设置静态主机IP
①、获取当前IP地址的网段
②、子网掩码以及网关

③、在虚拟机外部将其Ping通

(2)、修改主机名
临时修改
hostname 主机名称
永久修改
sudo vi /etc/sysconfig/network 文件
修改hostname属性
(权限不够时可以通过su root -->sudo vi /etc/sudoers添加权限,如下)

(3)、关闭防火墙
查看防火墙运行状态 sudo service iptables status
临时关闭防火墙 sudo service iptables stop
关闭防火墙服务 sudo chkconfig iptables off/on
(4)、安装远程客户端
1.filezilla.exe
2.SecureCRT
3.notepad++ (NTP.dll插件放入Notepad++\plugins下)
(5)、由于使用的时CentOS6.5自带java版本较低需删除,重新配置jdk1.7
①、卸载已有JDK
1.查看java相关的安装文件
sudo rpm -qa|grep java
2.卸载已安装的java文件
sudo rpm -e --nodeps 文件名1 文件名2 ...
②、安装JDk
1.上传JDK的安装包 1.7 (使用filezilla来上传安装包)
2.在/opt目录下新建两个子目录
softwares 存放上传的软件
modules 存放执行的文件
3.进入softwares目录
cd softwares
4.移动上传的文件到该目录
sudo mv ~/jdkxxxxx .
sudo mv ~/hadoopxxxx .
5.将文件解压到modules目录
sudo tar -zxvf jdk-7u80-linux-x64.tar.gz -C ../modules/
6.配置Java的环境变量
sudo vi ~/.bash_profile(环境变量配置文件),配置内容如下
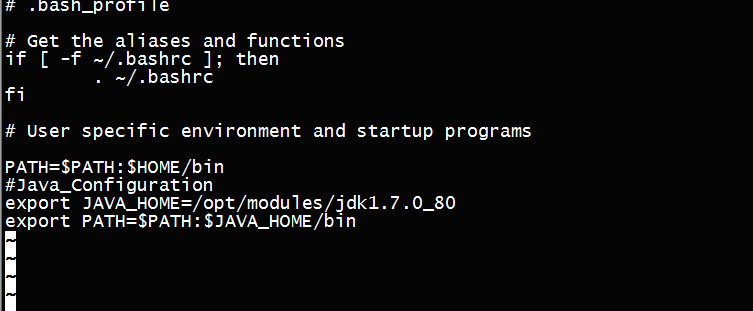
7.使新增内容生效
source ~/.bash_profile
8.查看是否配置成功
java -version 查看已安装的java版本
javac 查看是否可编译java文件
(6)、SSH免登陆
ssh远程访问协议,用于多台虚拟机直接的交互
1.开启ssh免登录
sudo vi /etc/ssh/sshd_config
2.生成ssh免登录的公钥与密钥
ssh-keygen -t rsa (过程中不停回车,设置密码均为空)
3.查看隐藏文件
ls -al (~目录下有.ssh文件)
4.保存公钥到authorized_keys文件中
cat id_rsa.pub >> authorized_keys
5.对.ssh目录和authorized_keys进行授权
sudo chmod 600 authorized_keys (.ssh)
sudo chmod 750 .ssh (~目录下)
同时将"/"下的opt改为对应的当前用户名所有(sudo chown -R hadoop:hadoop /opt [-R]表示循环改变)如下

设置主机名对应的ip
sudo vi /etc/hosts
ip地址 主机名

6.测试
ssh 主机名
ssh Master
(7)、在/opt/modules/hadoop-2.6.5/etc/hadoop下的文件修改
①、core-site.xm下添加
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.6.5/tmp</value>
</property>
</configuration>
②、在hadoop-env.sh、mappred-env.sh、yarn-env.sh下修改JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.7.0_80
③、在hdfs-site.xml下修改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
</configuration>
④、搭建集群时,主机要管理所有节点,修改slaves
Master Slave1 Slave2
⑤、修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
</configuration>
⑥、按同样的方式搭建好其余两台主机,主机名分别叫Slave1和Slave2,不同的是在slave文件中只有各自对应的Slave1和Slave2一个节点,同时修改修改yarn-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(8)、在三台主机都添加上主机名
sudo vi /etc/hosts
192.168.9.111 Master
192.168.9.112 Slave1
192.168.9.113 Slave2
(9)、设置多台主机可直接ssh免登入
ssh-copy-id -i ~/.ssh/id_rsa.pub
(10)、删除hadoop-2.6.5下的tmp和logs文件,格式化硬盘,启动hdfs文件系统以及查看开启的节点
rm -rf logs
rm -rf tmp(这两步三台主机都要进行)
bin/hdfs namenode -format 格式化硬盘
sbin/start-all.sh 启动HDFS文件关系系统
jps 查看开启节点数

(11)、登入http://192.168.9.111:50070查看详细信息,可以看到如下信息,说明三台主机可以正常工作了

利用web端实现对HDFS系统的管理
bin/hdfs dfs -mkdir /user 创建user文件夹
bin/hdfs dfs -mkdir /user/<username> 创建username文件夹,此处我的是hadoop
bin/hdfs dfs -put etc/hadoop input 将创建的input的复制到HDFS文件管理系统中
其中Dao的写法如下:
package com.gqx.dao;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.net.URLEncoder;
import java.util.List;
import javax.servlet.http.Part;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileDao {
public FileStatus[] getAllFile() throws IOException{
System.setProperty("HADOOP_USER_NAME","hadoop");
System.setProperty("hadoop.home.dir","D:\\hadoop-2.6.5");
Configuration conf = new Configuration();
FileSystem fs =FileSystem.get(conf);
FileStatus[] list =fs.listStatus(new Path("/user/hadoop/input"));
return list;
}
public boolean delete(String name) throws IOException{
System.setProperty("HADOOP_USER_NAME","hadoop");
System.setProperty("hadoop.home.dir","D:\\hadoop-2.6.5");
Configuration conf = new Configuration();
FileSystem fs =FileSystem.get(conf);
return fs.delete(new Path("/user/hadoop/input/"+name),true);
}
public boolean upload(Part part) throws IOException{
System.setProperty("HADOOP_USER_NAME","hadoop");
System.setProperty("hadoop.home.dir","D:\\hadoop-2.6.5");
//创建HDFS文件系统
Configuration conf = new Configuration();
FileSystem hadoopFS= FileSystem.get(conf);
InputStream in=part.getInputStream();
Path path = new Path("/user/hadoop/input");
FSDataOutputStream fsout=hadoopFS.create(new Path(path+"/"+part.getSubmittedFileName()));
byte[] buf=new byte[1024];
int readbytes=0;
while((readbytes=in.read(buf))>0){
fsout.write(buf,0,readbytes);
}
in.close();
fsout.close();
return true;
}
public FSDataInputStream download(String name) throws IOException{
System.setProperty("HADOOP_USER_NAME","hadoop");
System.setProperty("hadoop.home.dir","D:\\hadoop-2.6.5");
//创建HDFS文件系统
Configuration conf = new Configuration();
FileSystem hadoopFS= FileSystem.get(conf);
// 如果文件名是中文,需要进行url编码
FSDataInputStream fsin = hadoopFS.open(new Path("/user/hadoop/input/"+name));
return fsin;
}
}
文件下载的servlet如下:
package com.gqx.servlet;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.hadoop.fs.FSDataInputStream;
import com.gqx.dao.FileDao;
/**
* Servlet implementation class DownloadServlet
*/
@WebServlet("/DownloadServlet")
public class DownloadServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* @see HttpServlet#HttpServlet()
*/
public DownloadServlet() {
super();
// TODO Auto-generated constructor stub
}
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
String name=request.getParameter("name");
FileDao dao = new FileDao();
//name = URLEncoder.encode(name, "UTF-8");
FSDataInputStream fsin = dao.download(name);
System.out.println(name);
response.setHeader("content-disposition", "attachment;fileName=" +
new String(name.getBytes("GBK"),"ISO-8859-1"));
OutputStream out = response.getOutputStream();
byte[] b = new byte[1024];
int len=-1;
while((len=fsin.read(b)) != -1){
out.write(b,0,len);
}
out.close();
fsin.close();
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
doGet(request, response);
}
}
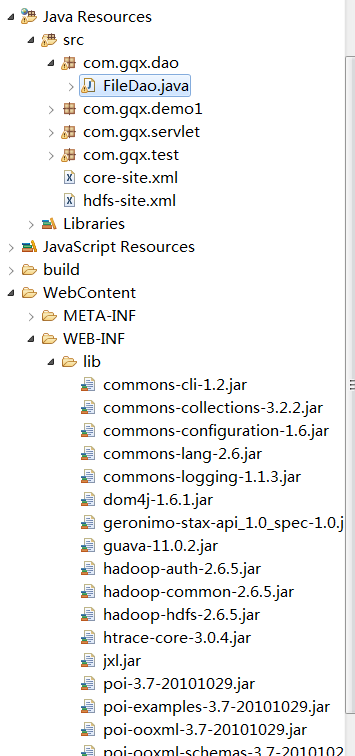
文件的目录和最终效果如下


 浙公网安备 33010602011771号
浙公网安备 33010602011771号