体验Stream API的用法
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
什么是Stream
Stream被翻译为流,它的工作过程像将一瓶水导入有很多过滤阀的管道一样,水每经过一个过滤阀,便被操作一次,比如过滤,转换等,最后管道的另外一头有一个容器负责接收剩下的水。
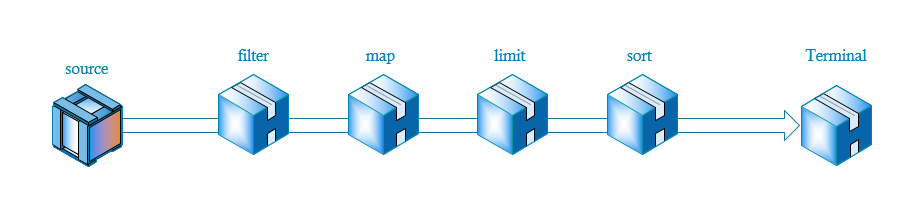
首先通过source产生流,然后依次通过一些中间操作,比如过滤,转换,限制等,最后结束对流的操作。
Stream也可以理解为一个更加高级的迭代器,主要的作用便是遍历其中每一个元素。
为什么需要Stream
Stream作为Java 8的一大亮点,它专门针对集合的各种操作提供各种非常便利,简单,高效的API,Stream API主要是通过Lambda表达式完成,极大的提高了程序的效率和可读性,同时Stram API中自带的并行流使得并发处理集合的门槛再次降低,使用Stream API编程无需多写一行多线程的大门就可以非常方便的写出高性能的并发程序。使用Stream API能够使你的代码更加优雅。
流的另一特点是可无限性,使用Stream,你的数据源可以是无限大的。
在没有Stream之前,我们想提取出所有年龄大于18的学生,我们需要这样做:
List<Student> result=new ArrayList<>();
for(Student student:students){
if(student.getAge()>18){
result.add(student);
}
}
return result;
使用Stream,我们可以参照上面的流程示意图来做,首先产生Stream,然后filter过滤,最后归并到容器中。
转换为代码如下
return students.stream().filter(s->s.getAge()>18).collect(Collectors.toList());
- 首先
stream()获得流 - 然后
filter(s->s.getAge()>18)过滤 - 最后
collect(Collectors.toList())归并到容器中
是不是很像在写sql?
如何使用Stream
我们可以发现,当我们使用一个流的时候,主要包括三个步骤:
- 获取/创建流
- 对流进行操作
- 结束对流的操作

(1)获取/流创建流
Collection体系集合:对于常见的容器(Collection)可以直接.stream()获取
例如:
Collection.stream()Collection.parallelStream()Arrays.stream(T array) or Stream.of()
Map体系集合:把Map转成Set集合,间接的生成流
//set
HashSet<String> set = new HashSet<>();
Stream<String> setStream = set.stream();
// map体系下集合间接生成流
Map<String, Integer> hashMap = new HashMap<>();
Stream<String> key = hashMap.keySet().stream();
Stream<Integer> valueStream = hashMap.values().stream();
Stream<Map.Entry<String, Integer>> setS = hashMap.entrySet().stream();
数组:通过Stream接口的静态方法of(T... values)生成
// 数组通过of方法生成流
String[] str ={"z","x","e"};
Stream<String> str1 = Stream.of(str);
// 直接的方式
Stream<Integer> integerStream = Stream.of(10, 20, 30);
Stream<String> z = Stream.of("z", "x", "e");
(2)中间操作
对于中间操作,所有的API的返回值基本都是Stream<T>,因此以后看见一个陌生的API也能通过返回值判断它的所属类型。
a. map/flatMap
map顾名思义,就是映射,map操作能够将流中的每一个元素映射为另外的元素。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
可以看到map接受的是一个Function,也就是接收参数,并返回一个值。
//提取 List<Student> 所有student 的名字
List<String> studentNames = students.stream().map(Student::getName)
.collect(Collectors.toList());
等同于:
List<String> studentNames=new ArrayList<>();
for(Student student:students){
studentNames.add(student.getName());
}
再比如:将List中所有字母转换为大写:
List<String> words=Arrays.asList("a","b","c");
List<String> upperWords=words.stream().map(String::toUpperCase)
.collect(Collectors.toList());
b. filter
filter顾名思义,就是过滤,通过测试的元素会被留下来并生成一个新的Stream
Stream<T> filter(Predicate<? super T> predicate);
filter接收的参数是Predicate,也就是推断型函数式接口,接收参数,并返回boolean值。
//获取所有大于18岁的学生 List<Student> studentNames = students.stream().filter(s->s.getAge()>18)
c. distinct
distinct是去重操作,它没有参数
Stream<T> distinct();
d. sorted
sorted排序操作,默认是从小到大排列. sorted方法包含一个重载,使用sorted方法,如果没有传递参数,那么流中的元素就需要实现Comparable<T>方法,也可以在使用sorted方法的时候传入一个Comparator<T>,值得一说的是这个Comparator在Java 8之后被打上了@FunctionalInterface,其他方法都提供了default实现,因此我们可以在sort中使用Lambda表达式
//以年龄排序
students.stream().sorted((s,o)->Integer.compare(s.getAge(),o.getAge()))
.forEach(System.out::println);
总结:
Stream的特点:
1. 不是数据结构,不会保存数据。
2. 不会修改原来的数据源,它会将操作后的数据保存到另外一个对象中。
3. 惰性求值,流在中间处理过程中,只是对操作进行了记录,并不会立即执行,需要等到执行终止操作的时候才会进行实际的计算。
参考:https://www.cnblogs.com/dengchengchao/p/11855723.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号