JAVA网络爬虫
一、前置背景
1、URL定义
统一资源标识符(Uniform Resource Identifier ,URL)是采用一种特定语法标识一个资源的字符串。所标识的资源可能是服务器上的一个文件。Java的URL网络类可以让你通过URL去练级网络服务器并获取资源。
URL的格式如下:protocol://host:port/path?query#fragment
例如:https://www.baidu.com/
protocol(协议)可以是HTTP,HTTPS,FTP和File,port为端口号,path为文件路径及文件名。
URL类
Java的URL类可以让访问网络资源就像是访问你本地的文件夹一样方便快捷。我们通过使用Java的URL类 就可以经由URL完成读取和修改数据的操作。通过一个URL连接,我们就可以确定资源的位置,比如网络文件、网络页面以及网络应用程序等。其中包含了许多的语法元素。
构造函数

方法
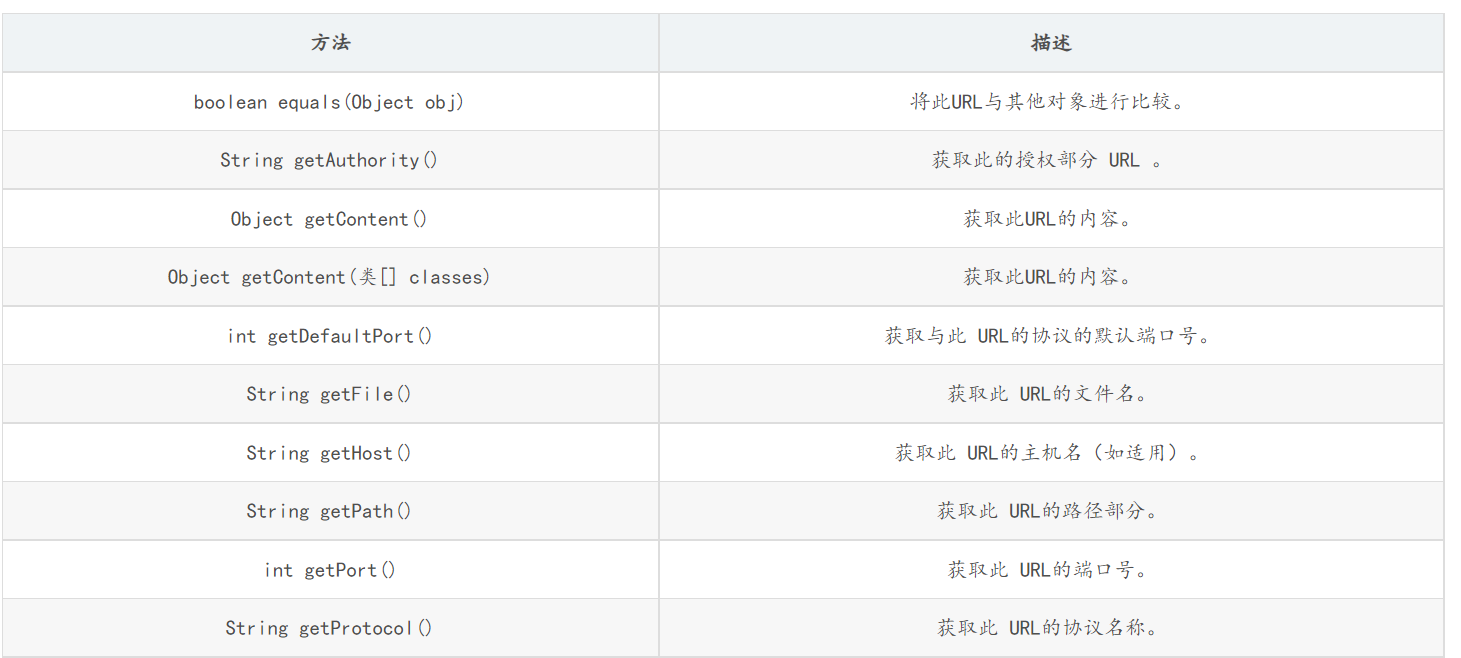
使用案例
public class URLTest { @Test public void test01() { URL u; try { u = new URL("https://www.baidu.com/"); //返回一个URLConnection实例,表示与URL引用的远程对象的URL 。 URLConnection uc = u.openConnection(); InputStream in = uc.getInputStream(); byte[] b = new byte[1024]; int len; while ((len = in.read(b)) != -1) { System.out.println(new String(b, 0, len)); } in.close(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } @Test //获取URL网页数据 public void getFromURL2() { URL u = null; BufferedReader in = null; try { u = new URL("https://www.baidu.com/"); //openStream方法:打开此 URL ,并返回一个 InputStream ,以便从该连接读取。 in = new BufferedReader(new InputStreamReader(u.openStream(), "UTF-8")); String str; while ((str = in.readLine()) != null) { System.out.println(str); } in.close(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } finally { if (in != null) { try { in.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } } }
2、正则表达式
字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在。比如判断一个字符串是否是合法的Email地址,虽然可以编程提取@前后的子串,再分别判断是否是单词和域名,但这样做不但麻烦,而且代码难以复用。正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
在正则表达式中,如果直接给出字符,就是精确匹配。用\d可以匹配一个数字,\w可以匹配一个字母或数字,所以:
-
'00\d'可以匹配'007',但无法匹配'00A'; -
'\d\d\d'可以匹配'010'; -
'\w\w\d'可以匹配'py3';
.可以匹配任意字符,所以:
'py.'可以匹配'pyc'、'pyo'、'py!'等等。
要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符:
来看一个复杂的例子:\d{3}\s+\d{3,8}。
我们来从左到右解读一下:
-
\d{3}表示匹配3个数字,例如'010'; -
\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等; -
\d{3,8}表示3-8个数字,例如'1234567'。
综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。
如果要匹配'010-12345'这样的号码呢?由于'-'是特殊字符,在正则表达式中,要用'\'转义,所以,上面的正则是\d{3}\-\d{3,8}。
但是,仍然无法匹配'010 - 12345',因为带有空格。所以我们需要更复杂的匹配方式。
进阶
要做更精确地匹配,可以用[]表示范围,比如:
-
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线; -
[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等; -
[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量; -
[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。
^表示行的开头,^\d表示必须以数字开头。
$表示行的结束,\d$表示必须以数字结束。
你可能注意到了,py也可以匹配'python',但是加上^py$就变成了整行匹配,就只能匹配'py'了。
常见的正则表达式:史上最全常用正则表达式大全
3、Pattern和Matcher
Pattern和Matcher是用于解决String功能有限不足以解决问题的强大的正则表达式对象。
使用步骤:
1. 将String类型的正则表达式传入Pattern.compile()中,生成Pattern对象,Pattern对象表示编译后的正则表达式
Pattern pattern = Pattern.compile("abc+"); //jdk解释:将给定的正则表达式编译到 模式 中。正则表达式:
2. 利用Pattern对象的matcher()生成Matcher对象,利用Matcher对象来进行一系列操作
Matcher matcher = pattern.matcher("abcdefg");参数为用于匹配的字符串
3. Matcher的常用方法有:
group():匹配成功返回的组
find():尝试查找与该模式匹配的输入序列的的下一个子序列。
示例:
public static void main(String[] args) {
Pattern pattern = Pattern.compile("\\w+"); //https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/1700215
Matcher matcher = pattern.matcher("how old are you");
while (matcher.find()) {
System.out.println(matcher.group()+" ");}
}
二、爬虫实例
下面先实现一个单网页数据提取的功能。

package com.gqx;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashSet;
import java.util.Set;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class URLDemo {
//爬取过的url
private static Set<String> oldSet = new HashSet<>();
private static Set<String> resultSet = new HashSet<>();
public static void main(String[] args) {
String urlStr = "https://search.jd.com/Search?keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC&enc=utf-8&wq=%E7%AC%94%E8%AE%B0%E6%9C%AC&pvid=71d09ef7ac384d039840ce5d3c6e38ef";
//授予及号码的匹配
Pattern p = Pattern.compile("<a .*href=.+</a>");
getHrefSet(urlStr, p);
Set<String> newUrlSet = new HashSet<>();
for (String str : resultSet) {
newUrlSet.add(str);
}
for (String newUrlStr : newUrlSet) {
getHrefSet(newUrlStr, p);
}
for (String str : resultSet) {
System.out.println(str);
}
}
public static HashSet getHrefSet(String urlStr, Pattern pattern) {
HashSet<String> result = new HashSet<>();
try {
//建立url爬取核心对象
URL url = new URL(urlStr);
//通过url建立与网页的连接
URLConnection conn = url.openConnection();
//通过链接取得网页返回的数据
InputStream is = conn.getInputStream();
//一般按行读取网页数据,并进行内容分析
//因此用BufferedReader和InputStreamReader把字节流转化为字符流的缓冲流
//进行转换时,需要处理编码格式问题
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
//按行读取并打印
String line = null;
while ((line = br.readLine()) != null) {
Matcher m = pattern.matcher(line);
// 通过Matcher类的group方法和find方法来进行查找和匹配
while (m.find()) {
String href = m.group();
//有无引号
href = href.substring(href.indexOf("href="));
if (href.charAt(5) == '\"') {
href = href.substring(6);
} else {
href = href.substring(5);
}
//截取到引号或者空格或者到">"结束
try {
href = href.substring(0, href.indexOf("\""));
} catch (Exception e) {
try {
href = href.substring(0, href.indexOf(" "));
} catch (Exception e1) {
href = href.substring(0, href.indexOf(">"));
}
}
if ((href.startsWith("http:") || href.startsWith("https:")) && !result.contains(href) ) {
resultSet.add(href);
}
}
}
br.close();
} catch (Exception e) {
System.out.println(e.getMessage());
}
return result;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号