
字符串匹配算法
原博地址:https://blog.csdn.net/ls291187101/article/details/51891974(字符串匹配算法综述:BF、RK、KMP、BM、Sunday)。写的很好,特意粘贴过来,转载。非常感谢原作者创作。
字符串匹配算法,是在实际工程中经常遇到的问题,也是各大公司笔试面试的常考题目。此算法通常输入为原字符串(string)和子串(pattern),要求返回子串在原字符串中首次出现的位置。比如原字符串为“ABCDEFG”,子串为“DEF”,则算法返回3。常见的算法包括:BF(Brute Force,暴力检索)、RK(Robin-Karp,哈希检索)、KMP(教科书上最常见算法)、BM(Boyer Moore)、Sunday等,下面详细介绍。
1 BF算法:
暴力检索法是最好想到的算法,也最好实现,在情况简单的情况下可以直接使用:

首先将原字符串和子串左端对齐,逐一比较;如果第一个字符不能匹配,则子串向后移动一位继续比较;如果第一个字符匹配,则继续比较后续字符,直至全部匹配。
时间复杂度:O(MN)
2 RK算法:
RK算法是对BF算法的一个改进:在BF算法中,每一个字符都需要进行比较,并且当我们发现首字符匹配时仍然需要比较剩余的所有字符。而在RK算法中,就尝试只进行一次比较来判定两者是否相等。
RK算法也可以进行多模式匹配,在论文查重等实际应用中一般都是使用此算法。
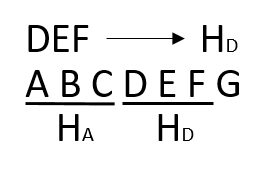
首先计算子串的HASH值,之后分别取原字符串中子串长度的字符串计算HASH值,比较两者是否相等:如果HASH值不同,则两者必定不匹配,如果相同,由于哈希冲突存在,也需要按照BF算法再次判定。
按照此例子,首先计算子串“DEF”HASH值为Hd,之后从原字符串中依次取长度为3的字符串“ABC”、“BCD”、“CDE”、“DEF”计算HASH值,分别为Ha、Hb、Hc、Hd,当Hd相等时,仍然要比较一次子串“DEF”和原字符串“DEF”是否一致。
时间复杂度:O(MN)(实际应用中往往较快,期望时间为O(M+N))
3 KMP算法:
字符串匹配最经典算法之一,各大教科书上的看家绝学,曾被投票选为当今世界最伟大的十大算法之一;但是晦涩难懂,并且十分难以实现,希望我下面的讲解能让你理解这个算法。
KMP算法在开始的时候,也是将原字符串和子串左端对齐,逐一比较,但是当出现不匹配的字符时,KMP算法不是向BF算法那样向后移动一位,而是按照事先计算好的“部分匹配表”中记载的位数来移动,节省了大量时间。这里我借用一下阮一峰大神的例子来讲解:

首先,原字符串和子串左端对齐,比较第一个字符,发现不相等,子串向后移动,直到子串的第一个字符能和原字符串匹配。

当A匹配上之后,接着匹配后续的字符,直至原字符串和子串出现不相等的字符为止。

此时如果按照BF算法计算,是将子串整体向后移动一位接着从头比较;按照KMP算法的思想,既然已经比较过了“ABCDAB”,就要利用这个信息;所以针对子串,计算出了“部分匹配表”如下(具体如何计算后面会说,这个先介绍整个流程):
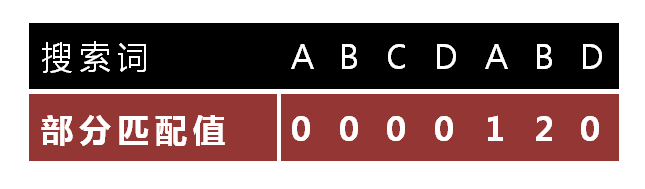
刚才已经匹配的位数为6,最后一个匹配的字符为“B”,查表得知“B”对应的部分匹配值为2,那么移动的位数按照如下公式计算:
移动位数 = 已匹配的位数 - 最后一个匹配字符的部分匹配值
那么6 - 2 = 4,子串向后移动4位,到下面这张图:

因为空格和“C”不匹配,已匹配位数为2,“B”对应部分匹配值为0,所以子串向后移动2-0=2位。

空格和“A”不匹配,已匹配位数为0,子串向后移动一位。

逐个比较,直到发现“C”与“D”不匹配,已匹配位数为6,“B”对应部分匹配值为2,6-2=4,子串向后移动4位。

逐个比较,直到全部匹配,返回结果。
下面说明一下“部分匹配表”如何计算,“部分匹配值”是指字符串前缀和后缀所共有元素的长度。前缀是指除最后一个字符外,一个字符串全部头部组合;后缀是指除第一个字符外,一个字符串全部尾部组合。以”ABCDABD”为例:
“AB”的前缀为[A],后缀为[B],共有元素的长度为0;
“ABC”的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
“ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
“ABCDA”的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为”A”,长度为1;
“ABCDAB”的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为”AB”,长度为2;
“ABCDABD”的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
在计算“部分匹配表”时,一般使用DP(动态规划)算法来计算(表示为next数组)://这里我没看懂,理论上不用DP直接搜也行啊
int* next = new int[needle.length()];
next[0] = 0;
int k = 0;
for (int i = 1; i < needle.length(); i++)
{
while (k > 0 && needle[i] != needle[k])
{
k = next[k - 1];
}
if (needle[i] == needle[k])
{
k++;
}
next[i] = k;
}
时间复杂度:O(N)
4 BM算法:
在本科的时候,我一直认为KMP算法是最好的字符串匹配算法,直到后来我遇到了BM算法。BM算法的执行效率要比KMP算法快3-5倍左右,并且十分容易理解。各种记事本的“查找”功能(CTRL + F)一般都是采用的此算法。
网上所有讲述这个算法的帖子都是以传统的“好字符规则”和“坏字符规则”来讲述的,但是个人感觉其实这样不容易理解,我总结了另外一套简单的算法规则:
我们拿这个算法的发明人Moore教授的例子来讲解:

首先,原字符串和子串左端对齐,但是从尾部开始比较,就是首先比较“S”和“E”,这是一个十分巧妙的做法,如果字符串不匹配的话,只需要这一次比较就可以确定。
在BM算法中,当每次发现当前字符不匹配的时候,我们就需要寻找一下子串中是否有这个字符;比如当前“S”和“E”不匹配,那我们需要寻找一下子串当中是否存在“S”。发现子串当中并不存在,那我们将子串整体向后移动到原字符串中“S”的下一个位置(但是如果子串中存在原字符串当前字符肿么办呢,我们后面再说):

我们接着从尾部开始比较,发现“P”和“E”不匹配,那我们查找一下子串当中是否存在“P”,发现存在,那我们就把子串移动到两个“P”对齐的位置:
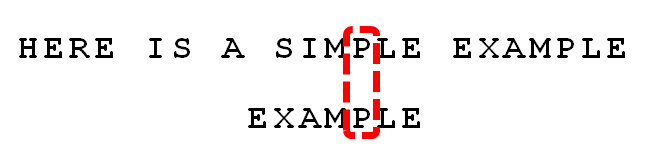
已然从尾部开始比较,“E”匹配,“L”匹配,“P”匹配,“M”匹配,“I”和“A”不匹配!那我们就接着寻找一下子串当前是否出现了原字符串中的字符,我们发现子串中第一个“E”和原字符串中的字符可以对应,那直接将子串移动到两个“E”对应的位置:
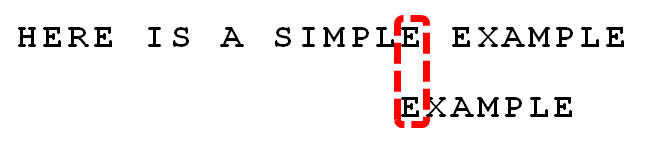
接着从尾部比较,发现“P”和“E”不匹配,那么检查一下子串当中是否出现了“P”,发现存在,那么移动子串到两个“P”对应:

从尾部开始,逐个匹配,发现全部能匹配上,匹配成功~
时间复杂度:最差情况O(MN),最好情况O(N)
5 Sunday算法:
后来,我又发现了一种比BM算法还要快,而且更容易理解的算法,就是这个Sunday算法:
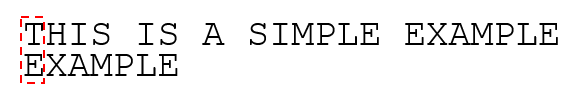
首先原字符串和子串左端对齐,发现“T”与“E”不匹配之后,检测原字符串中下一个字符(在这个例子中是“IS”后面的那个空格)是否在子串中出现,如果出现移动子串将两者对齐,如果没有出现则直接将子串移动到下一个位置。这里空格没有在子串中出现,移动子串到空格的下一个位置“A”:

发现“A”与“E”不匹配,但是原字符串中下一个字符“E”在子串中出现了,第一个字符和最后一个字符都有出现,那么首先移动子串靠后的字符与原字符串对齐:

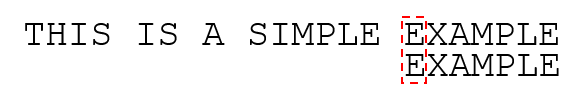
发现空格和“E”不匹配,原字符串中下一个字符“空格”也没有在子串中出现,所以直接移动子串到空格的下一个字符“E”:
这样从头开始逐个匹配,匹配成功!
时间复杂度:最差情况O(MN),最好情况O(N)
//实际我写好像可以是o(M+N)啊。。
代码粘一下:
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
char a[10005],b[10005];//long a>long b
int c[30];//表示b串中存在的字母;不存在则为1,存在为最靠后的此字符距离尾部加一(要跳的地方)
int la,lb;//字符串a,b的长度
int head;//当前搜索到的头字符
int main()
{
scanf("%s",a);
scanf("%s",b);//read in
la=strlen(a);
lb=strlen(b);
for(int i=0;i<=lb-1;i++)
c[b[i]-'a'+1]=lb-i;//初始化c数组
for(int i=0;head<=la-1;)//i表示当前匹配长度 ,head指针跳到a尾时结束
{
if(a[head+i]==b[i])
{
i++;//匹配则更新i值
if(i==lb) //匹配到的长度等于b串长度 则成功
{
printf("Yes");return 0;
}
}
else
{
if(c[a[head+lb]-'a'+1]!=0) head=head+c[a[head+lb]-'a'+1];//判断是否出现
else head=head+lb+2; //未出现,跳到下一个长度
i=0;//匹配值更新为0
}
}
printf("No");
return 0;
}
其他参考资料
[1] KMP算法最浅显理解——一看就明白 https://blog.csdn.net/starstar1992/article/details/54913261
[2] 结合kmp算法的匹配动画浅析其基本思想 https://segmentfault.com/a/1190000013386857

 浙公网安备 33010602011771号
浙公网安备 33010602011771号