Redis缓存面临的3大问题
1 缓存穿透
1-1 缓存空对象
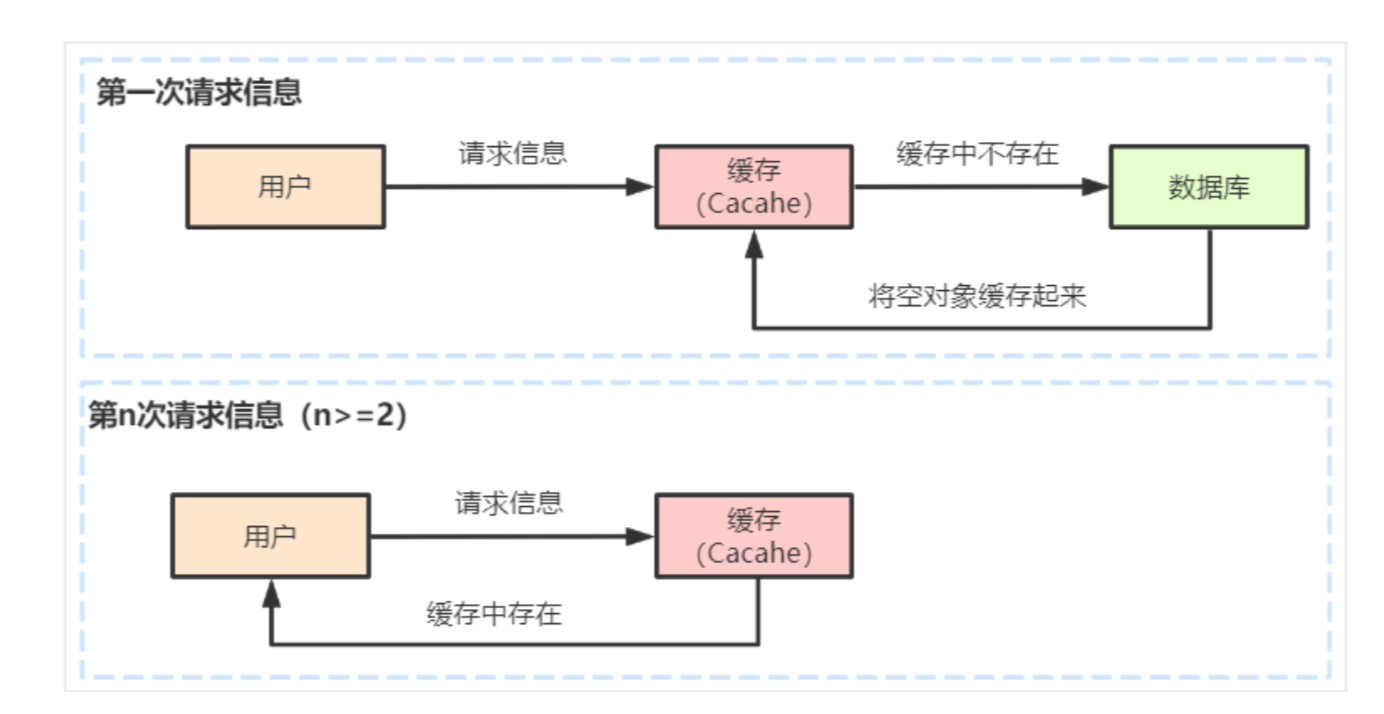
缓存空对象它就是指一个请求发送过来,
如果此时缓存中和数据库都不存在这个请求所要查询的相 关信息,
那么数据库就会返回一个空对象,并将这个空对象和请求关联起来存到缓存中,
当下次还是这个请求过来的时候,这时缓 存就会命中,就直接从缓存中返回这个空对象,
这样可以减少访问数据库的压力,提高当前数据库的访问性能。
面临的问题
如果大量不存在的请求过来,那么这时候缓存岂不是会缓存许多空对象了吗
如果时间一长这样会导致缓存中存在大量空对象,这样不仅会占用许多的内存 空间,
还会浪费许多资源呀!
设置key的同时,设置过期时间
setex key seconds valule:设置键值对的同时指定过期时间(s)
1-2 布隆过滤器
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
布隆过滤器的特点
- 一个非常大的二进制位数组(数组中只存在0和1)
- 拥有若干个哈希函数(HashFunction)
- 在空间效率和查询效率都非常高
- 布隆过滤器不会提供删除方法,在代码维护上比较困难。
每个布隆过滤器对应到 Redis 的数据结构里面就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的
hash 值算得比较均匀。
向布隆过滤器添加元素
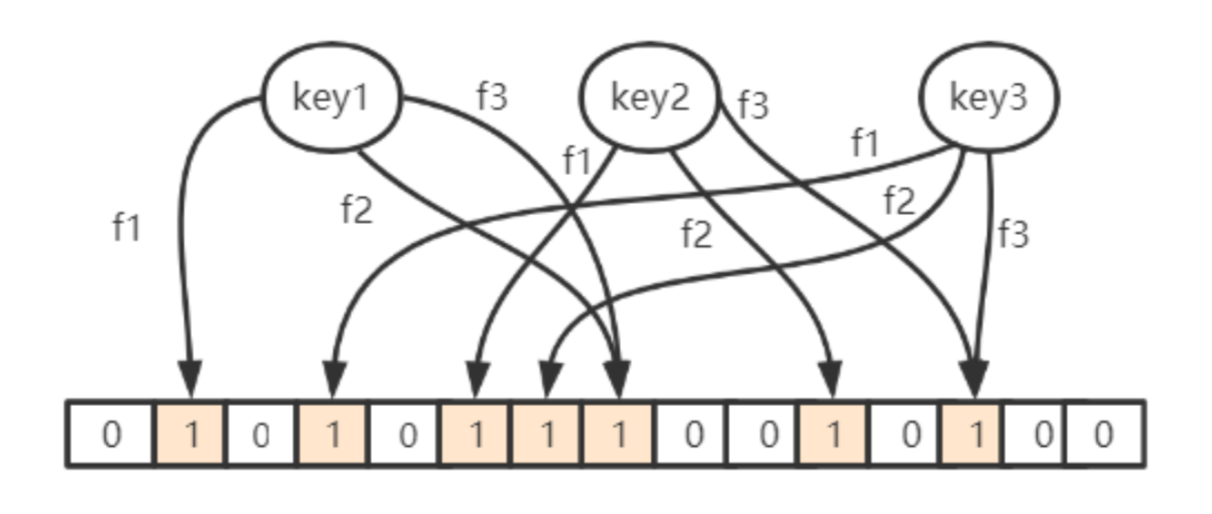
向布隆过滤器中添加 key 时,
会分别使用多个 hash 函数对 key 进行 hash 算得一个整数索引值
然后对位数组长度进行取模运算得到一 个位置,
每个 hash 函数都会算得一个不同的位置。
再把位数组的这几个位置都置为 1
就完成了 add 操作。
( 每一个 key 都通过 若干的hash函数映射到一个巨大位数组上,映射成功后,会在把位数组上对应的位置改为1。)
布隆过滤器的误判
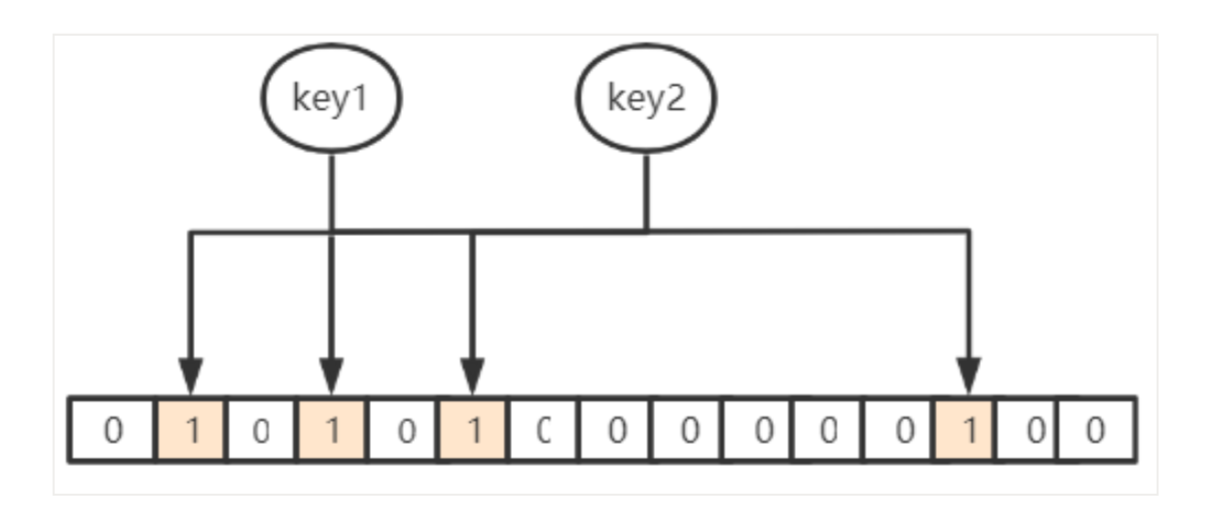
当 key1 和 key2 映射到位数组上的位置为 1 时,
假设这时候来了个 key3,要查询是不是在里面,
恰好 key3 对应位置也映射到了 这之间,
那么布隆过滤器会认为它是存在的,
这时候就会产生误判(因为明明 key3 是不在的)。
降低误判率
- 哈希函数的好坏
- 数组的大小
- 哈希函数的个数
对于一个布隆过滤器来说,如果其位数组越大的话,那么每个key通过hash函数映射的位置会变得稀疏许多,不会那么紧 凑,有利于提高布隆过滤器的准确率。
同时,对于一个布隆过滤器来说,如果key通过许多hash函数映射,那么在位数组上就会有 许多位置有标志,这样当用户查询的时候,在通过布隆过滤器来找的时候,误判率也会相应降低。
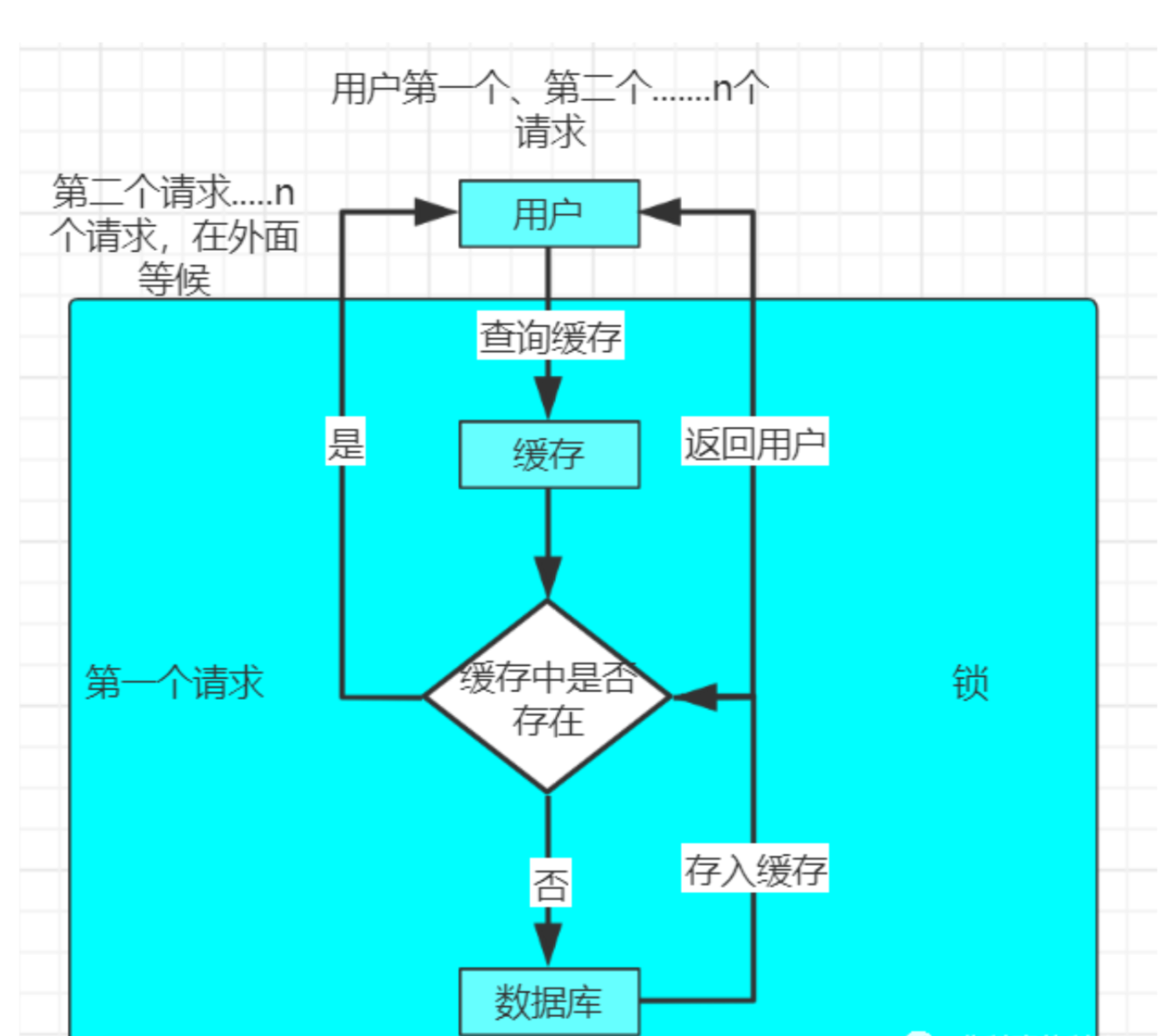
2 缓存的击穿
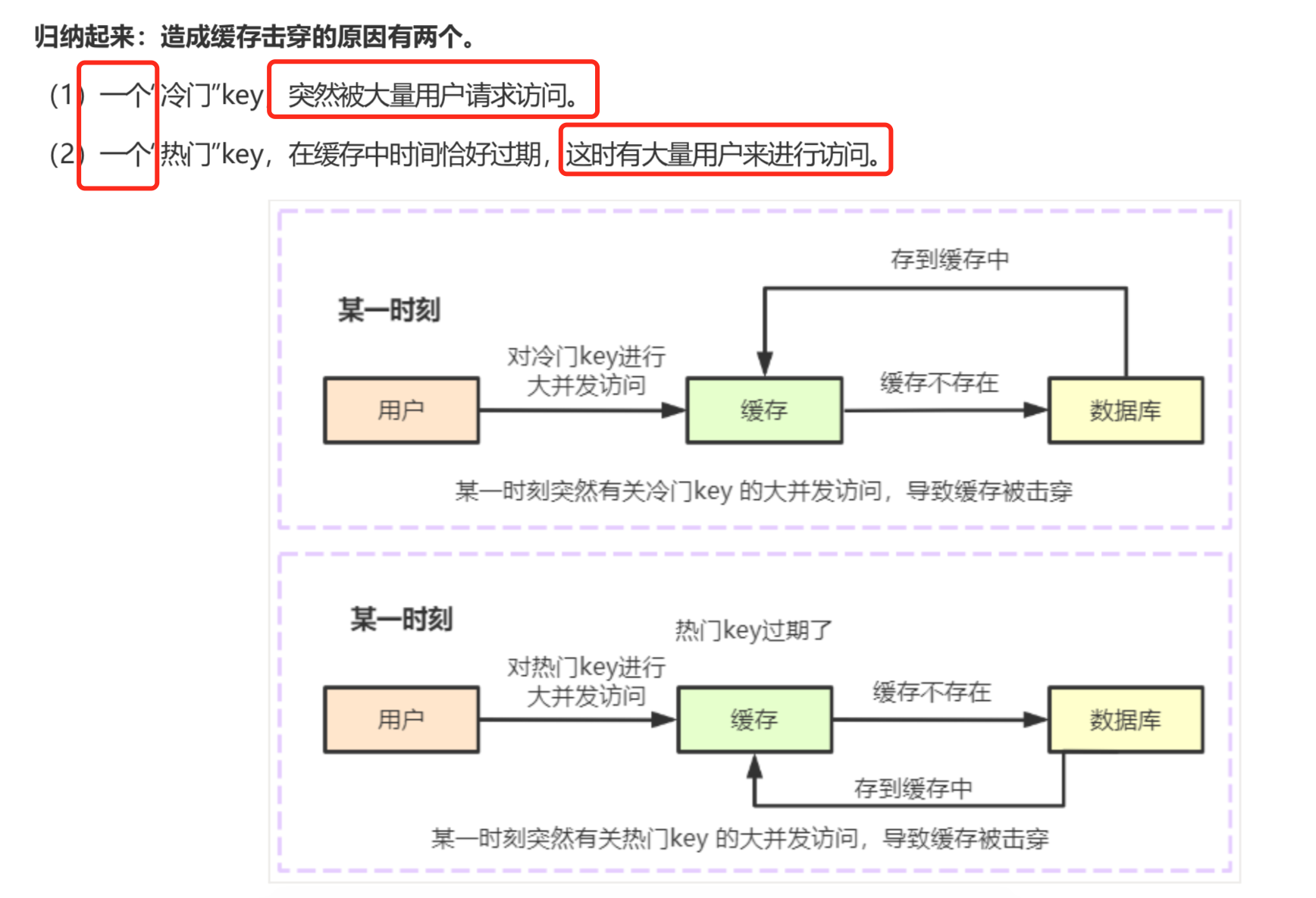
2-1 缓存击穿的原因
2-2 缓存击穿解决方案
加锁
对于key过期的时候,
当key要查询数据库的时候加上一把锁,
这时只能让第 一个请求进行查询数据库,然后把从数据库中查询到的值存储到缓存中,
对于剩下的相同的key,可以直接从缓存中获取即可。
如果我们是在单机环境下:直接使用常用的锁即可(如:Lock、Synchronized等),
在分布式环境下我们可以使用分布式锁,如:基于数据库、基于Redis或者zookeeper 的分布式锁。
加锁的代码演示( 单机版本)
/**
* todo 尝试着在代码中应用起来
* 高并发下,获取库存的数量
* 单机,加锁,解决缓存击穿问题
*
* 场景:
* 1. 该数据没有人查询过 ,第一次就大并发的访问。(冷门数据)
* 2. 添加到了缓存,reids有设置数据失效的时间 ,这条数据刚好失效,大并发访问(热点数据)
* @param key
* @return
*/
public String getProductNum(String key) {
try {
// 加锁
synchronized (this) {
// 从缓存中拿数据
int num = Integer.parseInt(stringRedisTemplate.opsForValue().get(key));
if (num > 0) {
// 每查一次库存 -1
stringRedisTemplate.opsForValue().set(key, (num - 1) + "");
System.out.println("剩余的库存num:" + (num - 1));
} else {
// todo 从数据库查出来,放到redis中。
System.out.println("剩余的库存num: 0 ");
}
}
} catch (NumberFormatException e) {
e.printStackTrace();
}finally {
}
return "ok";
}
分布式锁
/**
* 分布式锁解决缓存击穿的问题
* 高并发下,获取库存的数量
* 单机,加锁,解决缓存击穿问题
* @param key
* @return
*/
public String getProduceNum(String key) {
// 获取分布式锁
RLock lock = redissonClient.getLock(key);
try {
// 获取库存数
// 上锁
int num = Integer.parseInt(stringRedisTemplate.opsForValue().get(key));
lock.lock();
if (num > 0) {
//减少库存,并存入缓存中
redisTemplate.opsForValue().set(key, (num - 1) + "");
System.out.println("剩余库存为num:" + (num - 1));
} else {
// todo 从数据库中查询,放到redis
System.out.println("库存已经为0");
}
} catch (NumberFormatException e) {
e.printStackTrace();
} finally {
//解锁
lock.unlock();
}
return "OK";
}
3 缓存雪崩
3-1 雪崩的解决防范
redis高可用
redis搞个集群,哨兵,主从
限流
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量,对某个key只允许一个线程查询数据和写缓存,其他线程等
待。
数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即
将发生大并发访问前手动触发加载缓存不同的key。
设置不同过期时间
设置不同的过期时间,让缓存失效的时间点尽量均匀。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号