代码如下所示:
# -*- coding: utf-8 -*-
#导入需要的包
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from xgboost import XGBClassifier
from xgboost import plot_importance
### 加载数据集,这里直接使用datasets包里面的波士顿房价数据
boston=datasets.load_breast_cancer()
#输出数据集的形状,该数据集里面有569个样本,每个样本有30个特征(569, 30)
print(boston.data.shape)
#输出标签的个数为 569
print(boston.target.shape)
# 使用train_test_split()函数对训练集和测试集进行划分,第一个参数是数据集特征,第二个参数是标签,第三个为测试集占总样本的百分比
x_train,x_test,y_train,y_test = train_test_split(boston.data,
boston.target,
test_size = 0.3,
random_state = 33)
#使用XGBoost进行训练
model = XGBClassifier()
model.fit(x_train,y_train)
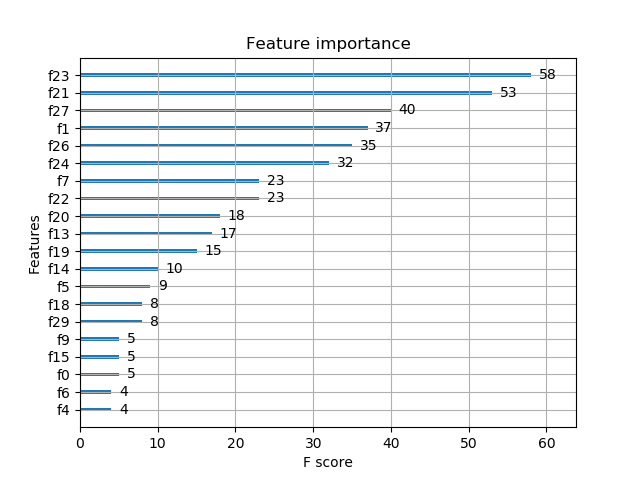
# 绘制重要性曲线,max_num_feature参数设置输出前20重要的特征()
plot_importance(model,max_num_features=20)
plt.show()
# 输入测试样本做预测
y_pred=model.predict_proba(x_test)[:,1]
# 输出AUROC的值
roc=roc_auc_score(y_test,y_pred)
print("The AUROC=%f",roc)
"""
0.9841
"""
运行结果:
![]()
其中,f2,f3,f4...这些是默认的按从0开始对特征的编号。但是这样的话,我们不知道这些f2,f3到底对应的是哪些特征。我觉得应该有函数什么的吧,要不然的话,怎么进行具体的分析呢。这个问题有待解决。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号