linux文本处理命令 一
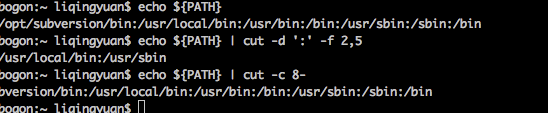
1,cut 主要的用途在于将同一行里面的数据进行分解
cut -d ‘分隔符’
-f ‘第几段’ 和-f同时使用
-c 字符区间 截取字符区间
2,grep cut 是在一行讯息当中,取出某部分我们想要的,而 grep 则是分析一行讯息
grep -[acinv] -color=auto 'string' filename
参数: a :二进制文件 c:计算次数 i:忽略大小写 n:输出行号 v:反向选择 --color=auto 颜色
-A n after的意思 ,该行之后n行也显示出来
-B n before 的意思 ,该行之前n行也显示出来
3,sort 文本行进行排序
sort -fbMnrtuk file/stdin
参数: f:忽略大小写 b忽略空白字符 M用月份名字排序 n纯数字排序 r反向排序 u过滤相同行 t分隔符 k利用分割开的哪段排序
4,uniq 统计过滤相同数据
uniq -ci file/stdin
参数: i忽略大小写 c统计出个数
5,wc 统计文件字符 行
wc -lwm file
参数: l行数 w字数 m字符数
6, tr 删除替换
tr -d 删除
-s 去重
‘string’ ‘ replacestring’ 替换
7,tee 数据流 standard out 之前数据形式
tee -a file 参数 a追加方式写入
8,split 大文件分区
split -bl file Prefix
参数 -b 大小分区 单位可以是bkm
-l 行数分区
prefix 分区文件前导文字
合并文件 cat file* >> fileback
9, sed -nefr

 浙公网安备 33010602011771号
浙公网安备 33010602011771号