09. 素数筛&质因数分解
09. 素数筛&质因数分解
素数筛法
素数筛其实就是 判断 1~N 中有哪些是素数。
素数就是指大于 1的数中,因子只有 1和它本身的数。
换句话说就是素数 N 在区间 [2, N-1] 一定不存在因子。
那么傻瓜式判断,时间复杂度 O(n):
bool isprime(int n){
if(n<2) return 0;
for(int i=2; i<n; i++){
if(n%i==0) return 0; // i是 n的因子
}
return 1;
}
其实对于这个我们可以适当优化,思路如下:
令 :\(a <= b, a*b = n;\)
则 :\(a*a <= a*b = n;\)
即 :\(a <= sqrt(n);\)
这样就将因数的范围由 [2, n-1] 缩减到了 [2, sqrt(n)], 时间复杂度 O(sqrt(n)):
bool isprime(int n){// 写法1
if(n<2) return 0;
for(int i=2; i<=sqrt(n); i++)
if(n%i==0) return 0;
return 1;
}
bool isprime(int n){// 写法2
if(n<2) return 0;
for(int i=2; i*i<=n; i++)
if(n%i==0) return 0;
return 1;
}
在上述求素数的方法中我们所使用的方法是对每一个数进行素数判断,
如果这个数没有除1和它本身外的其它因数,那么该数就是因数。
但是这样的算法时间复杂度是线性的,能不能优化一下呢?
肯定是可以的,首先我们发现如下规律:
2是素数,那么2*2=4不是素数,2*3=6不是素数,2*4=8不是素数...
3是素数,那么3*2=6不是素数,3*3=9不是素数,3*4=12不是素数...
于是想到素数的倍数(素数本身不计算在内)是合数,那么就没必要判断了呀,可以直接筛掉 - 埃式筛法
比如我想求 [1, 10] 的素数,有:
1 2 3 4 5 6 7 8 9 10 // 原数据
2 3 4 5 6 7 8 9 10 // 1不是素数,也不是合数,筛除 1
2 3 4 5 6 7 8 9 10 // 2是素数,筛除 2的倍数
2 3 5 7 9 // 3是素数,筛除 3的倍数
2 3 5 7 // 4是合数,continue
2 3 5 7 // 5是素数,筛除 5的倍数
2 3 5 7 // 6是合数,continue
2 3 5 7 // 7是素数,筛除 7的倍数
2 3 5 7 // 8是合数,continue
2 3 5 7 // 9是合数,continue
2 3 5 7 // 10是合数,continue
埃式筛法 - 埃拉托斯特尼筛法
原理:筛除倍数,素数的倍数一定不是素数,时间复杂度 O(nlogn)
bool isprime[N]; //判断是否素数, 1是素数,0不是素数
void Eratosthenes(int maxn){
//将isprime全部初始化为 1,相当于设置全部的 i都为质数
memset(isprime, 1, sizeof(isprime));
isprime[0]=isprime[1]=0; //0,1不是质数
for(int i=2; i<=maxn; i++){
if(isprime[i]==0) continue; //退出当前循环,继续下次循环
for(int j=2; i*j<=maxn; j++){
isprime[i*j]=0; // i*j不是质数
}
}
}
对于埃式筛法,发现会对同一个数多次筛除,这没必要啊,于是就有了 - 线性筛法
线性筛法 - 欧拉筛法,时间复杂度 O(n)
原理:素数的倍数是合数,且合数具有唯一最小素因子。
比如我想利用 欧拉筛法 求 [1,10] 的素数,有:
0 1 2 3 4 5 6 7 8 9 10 // 原数据, 0,1手动筛除
2 : 0 0 1 1 0 1 1 1 1 1 1 primes:2 // 2是素数,2*2=4,筛除4;2%2=0,break
3 : 0 0 1 1 0 1 0 1 1 0 1 primes:2 3 // 3是素数,3*2=6,3*3=9,筛除6,9;3%3=0,break
4 : 0 0 1 1 0 1 0 1 0 0 1 primes:2 3 // 4是合数,4*2=8,筛除 8;4%2=0,break
5 : 0 0 1 1 0 1 0 1 0 0 0 primes:2 3 5 // 5是素数,5*2=10,筛除 10;5*3=15>10 break
6 : 0 0 1 1 0 1 0 1 0 0 0 primes:2 3 5 // 6是合数,6*2=12>10 break
7 : 0 0 1 1 0 1 0 1 0 0 0 primes:2 3 5 7 // 7是素数,7*2=14>10,break
8 : 0 0 1 1 0 1 0 1 0 0 0 primes:2 3 5 7 // 8是合数,8*2=16>10 break
9 : 0 0 1 1 0 1 0 1 0 0 0 primes:2 3 5 7 // 9是合数,9*2=18>10 break
10 : 0 0 1 1 0 1 0 1 0 0 0 primes:2 3 5 7 //10是合数,10*2=20>10 break
bool isprime[N]; //判断是否素数, 1是素数,0不是素数
int primes[N],pn=0; //primes[i]为第 i个素数, pn 为素数个数
void FastSieve(int maxn){
// 初始化isprime全部为1,即初始化所有i为质数
memset(isprime, 1, sizeof(isprime));//0,1不是质数
isprime[0] = isprime[1] = pn = 0;
for(int i=2; i<=maxn; i++){
if(isprime[i]) primes[++pn] = i; //将质数 i存入primes
for(int j=1; j<=pn; j++){
if(i*primes[j] > maxn) break;
isprime[i*primes[j]] = 0; //质数的倍数都是合数
if(i%primes[j]==0) break; //利用最小素因子筛素数关键
}
}
}
- 完整程序
#include<iostream>
#include<cstring>
using namespace std;
const int N=1e6+1;
bool isprime[N]; //判断是否素数, 1是素数,0不是素数
int primes[N] pn=0; //primes[i]为第 i个素数, pn 为素数个数
//朴素方法(时间复杂度 O(sqrt(n))
bool isPrime(int n){
if(n<2) return false;
for(int i=2; i*i<=n; i++)
if(n%i==0) return false;
return true;
}
//埃式筛法 - 埃拉托斯特尼筛法
//原理:筛除倍数,一个素数的倍数一定不是素数,时间复杂度 O(nlogn)
void Eratosthenes(int maxn){
//将isprime全部初始化为 1,相当于设置全部的 i都为质数
memset(isprime, 1, sizeof(isprime));
isprime[0]=isprime[1]=pn=0; //0,1不是质数
for(int i=2; i<=maxn; i++){
if(isprime[i]==0) continue; //退出当前循环,继续下次循环
primes[++pn] = i; //将素数 i存入数组 primes
for(int j=2; i*j<=maxn; j++){
isprime[i*j]=0; // i*j不是质数
}
}
}
//线性筛法 - 欧拉筛法,时间复杂度 O(n)
//原理:素数的倍数是合数,且合数具有唯一最小素因子
void FastSieve(int maxn){
// 初始化isprime全部为1,即初始化所有i为质数
memset(isprime, 1, sizeof(isprime)); //0,1不是质数
isprime[0] = isprime[1] = pn = 0;
for(int i=2; i<=maxn; i++){
if(isprime[i]) primes[++pn] = i; //将质数 i存入primes
for(int j=1; j<=pn; j++){
if(i*primes[j] > maxn) break;
isprime[i*primes[j]] = 0; //质数的倍数都是合数
if(i%primes[j]==0) break; //利用最小素因子筛素数关键
}
}
}
int main() {
int n; cin>>n;
Eratosthenes(n);
// FastSieve(n);
for(int i=1; i<=pn; i++) cout<<primes[i]<<" "; cout<<endl;
return 0;
}
质因数分解
算术基本定理,又称为正整数的唯一分解定理
- 每个大于1的自然数均可写为质数的积,而且这些素因子按大小排列之后,写法仅有一种方式
【题目描述】对于正整数N的质因数分解,指的是将其写成:\(N=p1*p2*…*pm\);
其中,p1,p2,…,pm 为不下降的质数。给定N,输出其质因数分解的形式。
输入格式:1个正整数N。
输出格式:N的质因数分解的形式 \(N=p1*p2*…*pm\),其中p1,p2,…,pm都是质数而且p1<=p2<=…<=pm。
输入样例:60
输出样例:60=2*2*3*5
#include<iostream>
#include<cstdio>
using namespace std;
bool isprime(int m) {
if(m<2) return 0;
for(int i=2; i*i<=m; i++) if(m%i==0)return 0;
return 1;
}
int main() {
int n=60; scanf("%d",&n);
printf("%d=",n);
for(int i=2; i<=n; i++) {
if(!isprime(i)) continue;
while(n%i==0) {
if(n==i) printf("%d\n", i);
else printf("%d*",i);
n /= i;
}
}
return 0;
}
这个算法跑的非常慢,无法满足N较大时的需求。
我们发现对于所有数字我们都判断过i是否是一个质数,而事实上我们并不需要。
因为加入 n%i==0,那么 i 必然是一个质数!证明如下:
假设 i 不是质数,i 必存在一个质数因子 j,那么 j<i,但之前已经枚举过了j ,
n 已经把质数 j 全部分解出去了,当前的 n 已经没有了 j 因子 n%j!=0,与 n%i==0 矛盾!
所以当 n%i==0 时,i 必然为一个质数。
int main() {
int n=60; scanf("%d",&n);
printf("%d=",n);
for(int i=2; i<=n; i++) {
// if(!isprime(i)) continue; // 巧妙优化
while(n%i==0) {
if(n==i) printf("%d\n", i);
else printf("%d*",i);
n /= i;
}
}
return 0;
}
P1075 [NOIP2012 普及组] 质因数分解
【题目描述】已知正整数n是两个不同的质数的乘积,试求出两者中较大的那个质数。
输入格式:一个正整数n。
输出格式:一个正整数p,即较大的那个质数。
输入样例:21
输出样例:7
数据范围:n≤2×10^9
题解:
#include<iostream>
using namespace std;
bool isprime(int n){//判断n是不是素数
if(n<2) return false;
for(int i=2; i*i<=n; i++) if(n%i==0) return false;
return true;
}
int main_60(){
int n;cin>>n;
for(int i=n-1; i>=2; i--){
if(isprime(i) && isprime(n/i) && n%i==0){
cout<<i; break;//return 0;
}
}
return 0;
}
int main_100() {
int n; cin>>n;
// 唯一分解定理:一个数能且只能分解为一组质数的乘积 N=p1*p2*...pm
// 也就是说如果输入数据满足要求,则 N 只能分解成两个质数的乘积。
for(int i=2; i<=n; i++) {
if(n%i==0 && isprime(i)) { //最小的质因数
cout<<n/i<<endl //输出最大的质因数
break;
}
}
return 0;
}
int main_ac() {
int n; cin>>n;
for(int i=2; i<=n; i++) {
if(n%i==0) {
cout<<n/i<<endl; break;
}
}
return 0;
}
P3383 【模板】线性筛素数
【题目描述】给定一个范围 n,有 q 个询问,每次输出第 k 小的素数。
提示:如果你使用 cin 来读入,建议使用 std::ios::sync_with_stdio(0) 来加速。
输入格式:
第一行包含两个正整数 n,q,分别表示查询的范围和查询的个数。
接下来 q 行每行一个正整数 k,表示查询第 k 小的素数。
输出格式:输出 q 行,每行一个正整数表示答案。
输入样例:
100 5
1
2
3
4
5
输出样例:
2
3
5
7
11
数据范围:对于 100% 的数据,n = 10^8, 1≤q≤10^6,保证查询的素数不大于 n。
题解:
#include<bits/stdc++.h>
using namespace std;
const int N=1e8+1;
bool isprime[N];
int primes[N], pn=0,a[N];
bool isPrime(int num){
if(num<2) return 0;
for(int i=2; i*i<=num; i++) if(num%i==0) return 0;
return 1;
}
//埃式筛法 - 埃拉托斯特尼筛法
//筛除倍数,一个素数的倍数一定不是素数
void Eratosthenes(int maxn){
// 初始化isprime全部为1,即初始化所有i为质数
memset(isprime, 1, sizeof(isprime));
isprime[0]=isprime[1]=pn=0; //0,1不是质数
for(int i=2; i<=maxn; i++){
if(isprime[i]==0) continue;//退出当前循环,继续下次循环
primes[++pn] = i; //将质数 i存入primes
for(int j=2; i*j<=maxn; j++){
isprime[i*j] = 0; //质数的倍数都是合数
}
}
}
//线性筛法 - 欧拉筛法
void FastSieve(int maxn){
// 初始化isprime全部为1,即初始化所有i为质数
memset(isprime, 1, sizeof(isprime));//0,1不是质数
isprime[0] = isprime[1] = pn = 0;
for(int i=2; i<=maxn; i++){
if(isprime[i]) primes[++pn] = i;//将质数 i存入primes
for(int j=1; j<=pn; j++){
if(i*primes[j] > maxn) break;
isprime[i*primes[j]] = 0; //质数的倍数都是合数
if(i%primes[j]==0) break; //利用最小素因子筛素数关键
}
}
}
int main(){
int n=100, q=10; scanf("%d%d", &n, &q);
for(int i=1; i<=q; i++) scanf("%d", &a[i]);
// Eratosthenes(n);//埃氏筛法
FastSieve(n);//线性筛法
for(int i=1; i<=q; i++){
printf("%d\n",primes[a[i]]);
}
return 0;
}
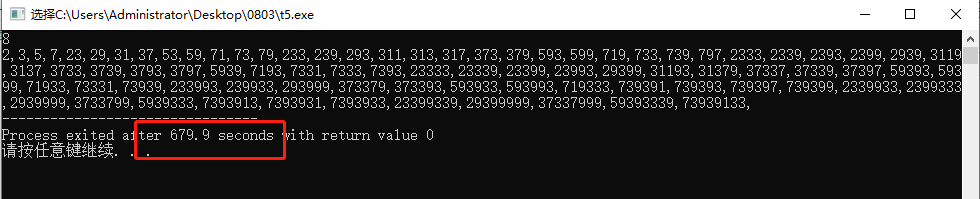
P1218 [USACO1.5]特殊的质数肋骨 Superprime Rib
【题目描述】农民约翰的母牛总是产生最好的肋骨。
你能通过农民约翰和美国农业部标记在每根肋骨上的数字认出它们。
农民约翰确定他卖给买方的是真正的质数肋骨,是因为从右边开始切下肋骨,
每次还剩下的肋骨上的数字都组成一个质数。
举例来说:7 3 3 1 全部肋骨上的数字 7331 是质数;
三根肋骨 733 是质数;二根肋骨 73 是质数;
当然,最后一根肋骨 7 也是质数。7331被叫做长度 4 的特殊质数。
写一个程序对给定的肋骨的数目 n,求出所有的特殊质数。1 不是质数。
输入格式:一行一个正整数 n。
输出格式:按顺序输出长度为 n 的特殊质数,每行一个。
输入样例:4
输出样例:
2333
2339
2393
2399
2939
3119
3137
3733
3739
3793
3797
5939
7193
7331
7333
7393
数据范围:对于 100% 的数据,1≤n≤8。
题解:
#include<bits/stdc++.h>
using namespace std;
const int N=1e8+1;
bool isprime[N];
int primes[N], pn=0,a[N];
bool isPrime(int num){
if(num<2) return 0;
for(int i=2; i*i<=num; i++) if(num%i==0) return 0;
return 1;
}
//埃式筛法 - 埃拉托斯特尼筛法
//筛除倍数,一个素数的倍数一定不是素数
void Eratosthenes(int maxn){
// 初始化isprime全部为1,即初始化所有i为质数
memset(isprime, 1, sizeof(isprime));
isprime[0] = isprime[1] = pn = 0;//0,1不是质数
for(int i=2; i<=maxn; i++){
if(isprime[i]==0) continue; //退出当前循环,继续下次循环
primes[++pn] = i; //将质数 i存入primes
for(int j=2; i*j<=maxn; j++){
isprime[i*j] = 0; //质数的倍数都是合数
}
}
}
//线性筛法 - 欧拉筛法
void FastSieve(int maxn){
// 初始化isprime全部为1,即初始化所有i为质数
memset(isprime, 1, sizeof(isprime));//0,1不是质数
isprime[0] = isprime[1] = pn = 0;
for(int i=2; i<=maxn; i++){
if(isprime[i]) primes[++pn] = i;//将质数 i存入primes
for(int j=1; j<=pn; j++){
if(i*primes[j] > maxn) break;
isprime[i*primes[j]] = 0; //质数的倍数都是合数
if(i%primes[j]==0) break; //利用最小素因子筛素数关键
}
}
}
int main(){
// freopen("test.out", "w", stdout);
int n=4; cin>>n;
if(n == 8) {//这一点确实有点难,只能使用打表或者二分思想来解决
cout<<"23399339"<<endl
<<"29399999"<<endl
<<"37337999"<<endl
<<"59393339"<<endl
<<"73939133"<<endl;return 0;
}
n = pow(10,n);
// Eratosthenes(n);//埃氏筛法
FastSieve(n);//线性筛法
for(int i=n/10; i<=n-1; i++){
int temp=i;
while(temp){
if(isprime[temp]==0) break;
temp /= 10;
}
if(temp==0) cout<<i<<endl;
}
/* for(int i=1; i<=n; i++){
if(primes[i] > n-1) break;
if(n/10 <= primes[i]){
int temp = primes[i];
while(temp){
if(isprimes[temp]==0) break;
temp /= 10;
}
if(temp==0) cout<<primes[i]<<endl;
}
}*/
return 0;
}
上面这个是用筛法程序做的,那么我们还是讲一讲取巧方法 - 打表
所谓打表,就是写一个最简单的程序,通过该程序得到部分中间数据,甚至是最终答案,从而达到能简化运算次数的目的。
#include<iostream>
#include<cmath>
using namespace std;
bool isPrime(int n){
if(n<2) return 0;
for(int i=2; i*i<=n; i++) if(n%i==0) return 0;
return 1;
}
void pd() {//按要求打表 - 用朴素算法
int n; cin>>n;
n=pow(10,n);
for(int i=2; i<=n; i++){
if(isPrime(i)){
int temp=i;
while(temp){
if(isPrime(temp)==0) break;
temp /= 10;
}
if(temp==0) cout<<i<<",";
}
}
}
const int N=10;
int primes[N][20]={//按要求对素数(1~8位)打表
{},
{2,3,5,7},
{23,29,31,37,53,59,71,73,79},
{233,239,293,311,313,317,373,379,593,599,719,733,739,797},
{2333,2339,2393,2399,2939,3119,3137,3733,3739,3793,3797,5939,7193,7331,7333,7393},
{23333,23339,23399,23993,29399,31193,31379,37337,37339,37397,59393,59399,71933,73331,73939},
{233993,239933,293999,373379,373393,593933,593993,719333,739391,739393,739397,739399},
{2339933,2399333,2939999,3733799,5939333,7393913,7393931,7393933},
{23399339,29399999,37337999,59393339,73939133}};
int main() {
int n; cin>>n;
for(int i=0; primes[n][i]!=0; i++){
cout<<primes[n][i]<<endl;
}return 0;
}//相对线性筛法而言,这道题我更推荐使用打表的方法来解决,不过也就10几分钟的事情

 浙公网安备 33010602011771号
浙公网安备 33010602011771号