
GPU体系架构(一):数据的并行处理
最近在了解GPU架构这方面的内容,由于资料零零散散,所以准备写两篇博客整理一下。GPU的架构复杂无比,这两篇文章也是从宏观的层面去一窥GPU的工作原理罢了
GPU根据厂商的不同,显卡型号的不同,GPU的架构也有差别,但是大体的设计基本相同,原理的部分也是相通的。下面我们就以NVIDIA的Fermi架构为蓝本,从降低延迟的角度,来讲解一下GPU到底是如何利用数据的并行处理来提升性能的。有关GPU的架构细节和逻辑管线的实现细节,我们将在下一篇里再讲。
无论是CPU还是GPU,都在使用各种各样的策略来避免停滞(stall)。
CPU的优化路线有很多,包括使用pipeline,提高主频,在芯片上集成访问速度更快的缓存,减少内存访问的延迟等等。在减少stalls的路上,CPU还采用了很多聪明的技术,比如分支预测,指令重排,寄存器重命名等等。
GPU则采用了另一种不同的策略:throughput。它提供了大量的专用处理器,由于GPU端数据的天然并行性,所以通过数据的大规模并行化处理,来降低延迟。这种设计优点是通过提高吞吐量,数据的整体处理时间减少,隐藏了处理的延迟。但是由于芯片上集成的核越多,留给其他设备的空间就越小,所以像memory cache和logical control这样的设备就会变少,导致每一路shader program的执行变得延迟很高。了解这个特性,我们来看一个例子,以此来说明如何利用GPU的架构,写出更高效的代码。
假如我们有一个mesh要被渲染,光栅化后生成了2000个fragment,那么我们需要调用一个pixel shader program 2000次,假如我们的GPU只有一个shader core(世界最弱鸡GPU),它开始执行第一个像素的shader program,执行一些算数指令,操作一下寄存器上的值,由于寄存器是本地的,所以此时并不会发生阻塞,但是当程序执行到某个纹理采样的操作时,由于纹理数据并不在程序的本地寄存器中,所以需要进行内存的读取操作,该操作可能要耗费几百甚至几千个时钟周期,所以会阻塞住当前处理器,等待读取的结果。如果真的只是这样设计这个GPU,那它真的就是太弱鸡了,所以为了让它稍微好点,我们需要提升它的性能,那如何降低它的延迟呢?我们给每个fragment提供一些本地存储和寄存器,用来保存该fragment的一些执行状态,这样我们就可以在当前fragment等待纹理数据时,切换到另一个fragment,开始执行它的shader program,当它遇到内存读取操作阻塞时,会再次切换,以此类推,直到2000个shader program都执行到这里。这时第一个fragment的颜色已经返回,可以继续往下执行了。使用这种方式,可以最大化的提高GPU的效率,虽然在单个像素来看,执行的延迟变高了,但是从2000个像素整体来说,执行的延迟减少了。
现代GPU当然不会弱鸡到只有一个shader core,但是它们也同样采用了这种方式来减低延迟。现代GPU为了提高数据的并行化,使用了SIMT(Single Instruction Multi Thread,SIMD的更高级版本),执行shader program的最小单位是thread,执行相同program的threads打包成组,NVIDIA称之为warp,AMD称之为wavefront。一个warp/wavefront在特定数量的GPU shader core上调度执行,warps调度器调度的基本单元就是warp/wavefront。
假如我们有2000个fragment需要执行shader program,以NVIDIA为例,它的GPU包含32个thread,所以要执行这些任务需要2000/32 = 62.5个warps,也就是说要分配63个warps,有一个只使用一半。
一个warp的执行过程跟单个GPU shader core的执行过程是类似的,32个像素的shader program对应的thread,会在32个GPU shader core上同时以lock-step的方式执行,当着色器程序遇到内存读取操作时,比如访问纹理(非常耗时),因为32个threads执行的是相同的程序,所以它们会同时遇到该操作,内存读取意味着该线程组将会阻塞(stall),全部等待内存读取的结果。为了降低延迟,GPU的warp调度器会将当前阻塞的warp换出,用另一组包含32个线程的warp来代替执行。换出操作跟单核的任务调度一样的快,因为在换入换出时,每个线程的数据都没有被触碰,每个线程都有它自己的寄存器,每个warp都负责记录它执行到了哪条指令。换入一个新的warp,不过是将GPU 的shader cores切换到另一组线程上继续执行,除此之外没有其他额外的开销。该过程如下图所示:
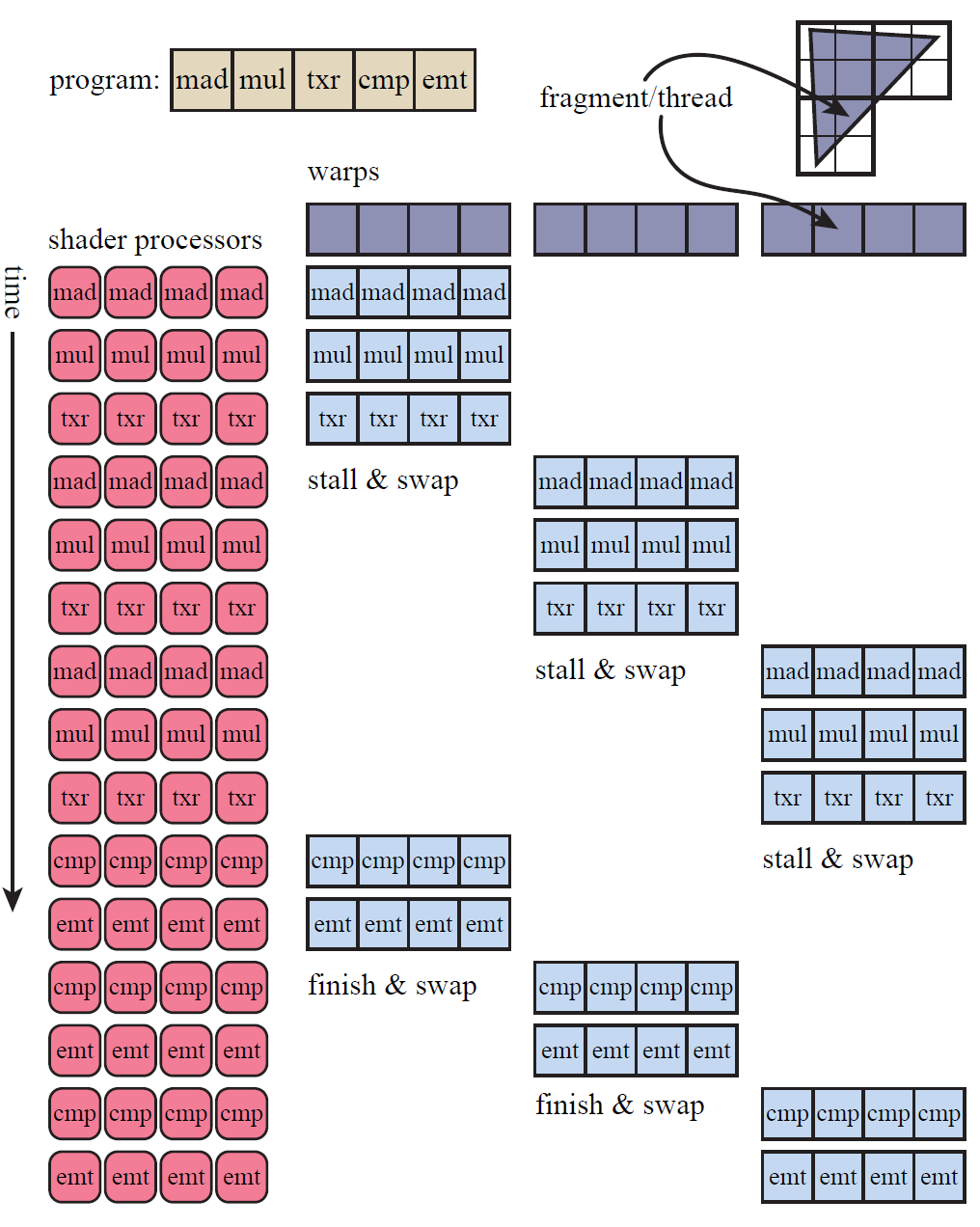
在我们这个简单的例子中,内存读取的延迟(latency)会导致warp被换出,在实际的应用中,可能更小的延迟就会导致warp的换出操作,因为换入换出的操作开销非常低。warp-swapping的策略是GPU隐藏延迟(latency)的主要方式。但是有几个关键因素,会影响到该策略的性能,比如说,如果我们只有很少的threads,也就是只能创建很少的warp,会使隐藏延迟出现问题。
shader program的结构是影响性能的主要角色,其中最大的一个影响因素就是每个thread需要的寄存器的数量。在上面例子的讲解过程中,我们一直假设例子中的2000个thread都是同时驻留在GPU中的。但是实际上,每个thread绑定的shader program中需要的寄存器越多,产生的threads就越少(因为寄存器的数量是固定的),能够驻留在GPU中的warp就越少。warps的短缺也就意味着无法使用warp-swapping的策略减缓延迟。warps在GPU中存在的数量称之为占用率,高占用率意味着有更多的warps可以用来执行,低占用率则会严重影响GPU的并行效率。
另一个影响GPU性能的因素就是动态分支(dynamic branching),主要是由if和循环引进的。因为一个warp中的所有线程在执行到if语句时,就会出现分裂,如果大家都是执行的相同的分支,那也没什么,但但凡有一个线程执行另一个分支,那么整个warp会把两个分支都执行一遍,然后每个线程扔掉它们各自不需要的结果,这种现象称为thread divergence。
了解了上面的基本原理,我们可以看出,整个GPU的设计其实也是一种trade-off,用单路数据的高延迟,来换整体数据的吞吐量,以此来最大化GPU的性能,降低stall。在实际的编码过程中,尤其是shader的编写过程中,也要严肃影响GPU优化策略的几个因素,只有这样,才能写出更加高效的代码,真正发挥出GPU的潜力。
下一篇会更加详细的介绍GPU的结构和逻辑管线,如果错误,欢迎指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号