
软件工程作业3
1、要求地址
- 博客要求地址:https://www.cnblogs.com/happyzm/p/9626779.html
- Fork码云项目地址:https://gitee.com/YeHei/PairProject-Java/tree/master
- 结对伙伴:余硕铭 博客地址:http://www.cnblogs.com/ysm0301/p/9751621.html
2.PSP表格
| PSP2.1 | 个人开发流程 | 预估耗费时间(分钟) | 实际耗费时间(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | 明确需求和其他相关因素,估计每个阶段的时间成本 | 30 | 50 |
| Development | 开发 | 550 | 650 |
| · Analysis | 需求分析 (包括学习新技术) | 50 | 60 |
| · Design Spec | 生成设计文档 | 20 | 30 |
| · Design Review | 设计复审 | 40 | 50 |
| · Coding Standard | 代码规范 | 10 | 15 |
| · Design | 具体设计 | 45 | 85 |
| · Coding | 具体编码 | 100 | 110 |
| · Code Review | 代码复审 | 30 | 25 |
| · Test | 测试(自我测试,修改代码,提交修改) | 60 | 240 |
| Reporting | 报告 | 30 | 40 |
| · | 测试报告 | 15 | 15 |
| · | 计算工作量 | 5 | 10 |
| · | 并提出过程改进计划 | 20 | 15 |
3.基本思路:
根据题目的要求,首先需要在对已经建好或导入的文档进行读取,这里就需要有文件读取类,对文件中的所有进行读取。
文件读取之后,将相应的字符、单词、行数等进行计数,并在判断是否为单词后,利用Map实现对单词的词频统计,根据题目中要求进行计算。
对统计出来的数据输出。
4.设计实现过程。
代码组织:
1.WordCount类:对字符数、单词数、行数等进行统计。
- countChar();统计字符数
- countWords();统计单词数
- countLine();统计行数
- WordFre();实现单词词频统计并出现次数从高到低排列
2.FileRead类:导入需要WordCount的文件,进行文件读取等操作
- FileOutput();文件读取
- FileInput();文件写入
3.Main类:实现数据的输出和文件路径的输入,并将WordCount类和FileInput类调用,实现功能。:
5、主要函数
- countChar() : 统计字符数量
public static int countChar(String str) { //统计字符数量
char s;
int CharSum=0;
for (int i = 0; i < str.length(); i++) {
s=str.charAt(i);
if (s>=32 && s<=126 || s=='\r' || s=='\n' || s=='\t') {
CharSum++;
}
}
return CharSum;
}
- countWords():统计单词数量
public int countWords(String[] str) { //统计单词数量
String str1=text;
int WordsSum=0;
String[] words=str1.split("\\s*[^0-9a-zA-Z]"); //调用正则表达式中spilt()方法来切分字段,将字符串中的单词提取出来
for(String s:words) {
if(s.matches("[a-zA-Z{4,}[z-zA-Z0-0]*")) { //调用matchs方法来判断这个字符串是否在给定的正则表达式匹配
WordsSum++;
}
}
return WordsSum;
}
- countLine :统计行数
public static int countLine(String[] str) { //统计行数
int LineSum=0;
for (int i = 0; i < str.length; i++) {
while(str[i]!=null) {
if(str[i].trim().length()==0 || str[i].trim().equals("")) {
continue; //调用trim()方法将头尾空格去掉,来判断行数
}
LineSum++;
}
}
return LineSum;
}
- WordFre :计算全文的单词词频:
public List<Entry<String, Integer>> WordFre()
{
WordFre= new HashMap<String, Integer>();
String t = text;
String[] words = t.split("\\s"); // 将字符串进行分割
for (int i = 0; i < words.length; i++) {
if (isWord(words[i])) { // 判断是否为单词,调用isWord函数
words[i] = words[i].trim().toLowerCase();//将大写字母变成小写字母
if (WordFre.get(words[i]) == null) { // 判断之前Map中是否出现过该字符串
WordFre.put(words[i], 1);// 如果为新单词,放入map中作为key值,value设为1
} else
WordFre.put(words[i], WordFre.get(words[i]) + 1);//如果出现过的单词则将value值+1
}
}
- 将词频排序用list储存:
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(WordFre.entrySet());//用list列表储存键值
list.sort(new Comparator<Map.Entry<String, Integer>>() {//对list排序
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
if (o1.getValue() == o2.getValue()) {//判断词频是否相等
return o1.getKey().compareTo(o2.getKey());//字典序排列
}
return o2.getValue() - o1.getValue();//降序排列
}
});
return list;
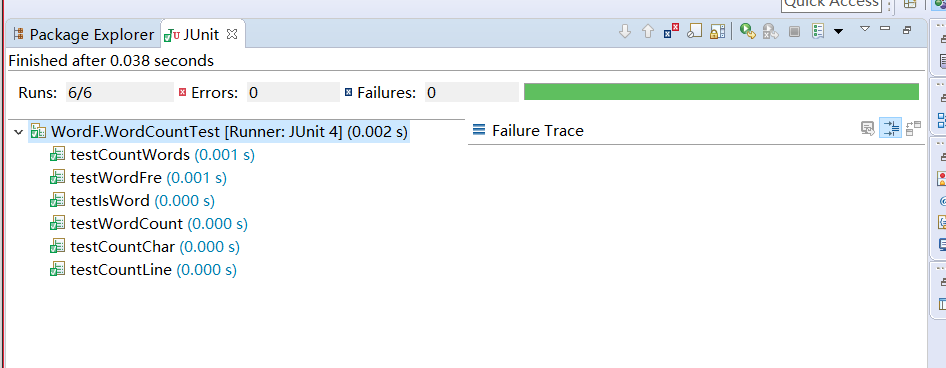
5、单元测试
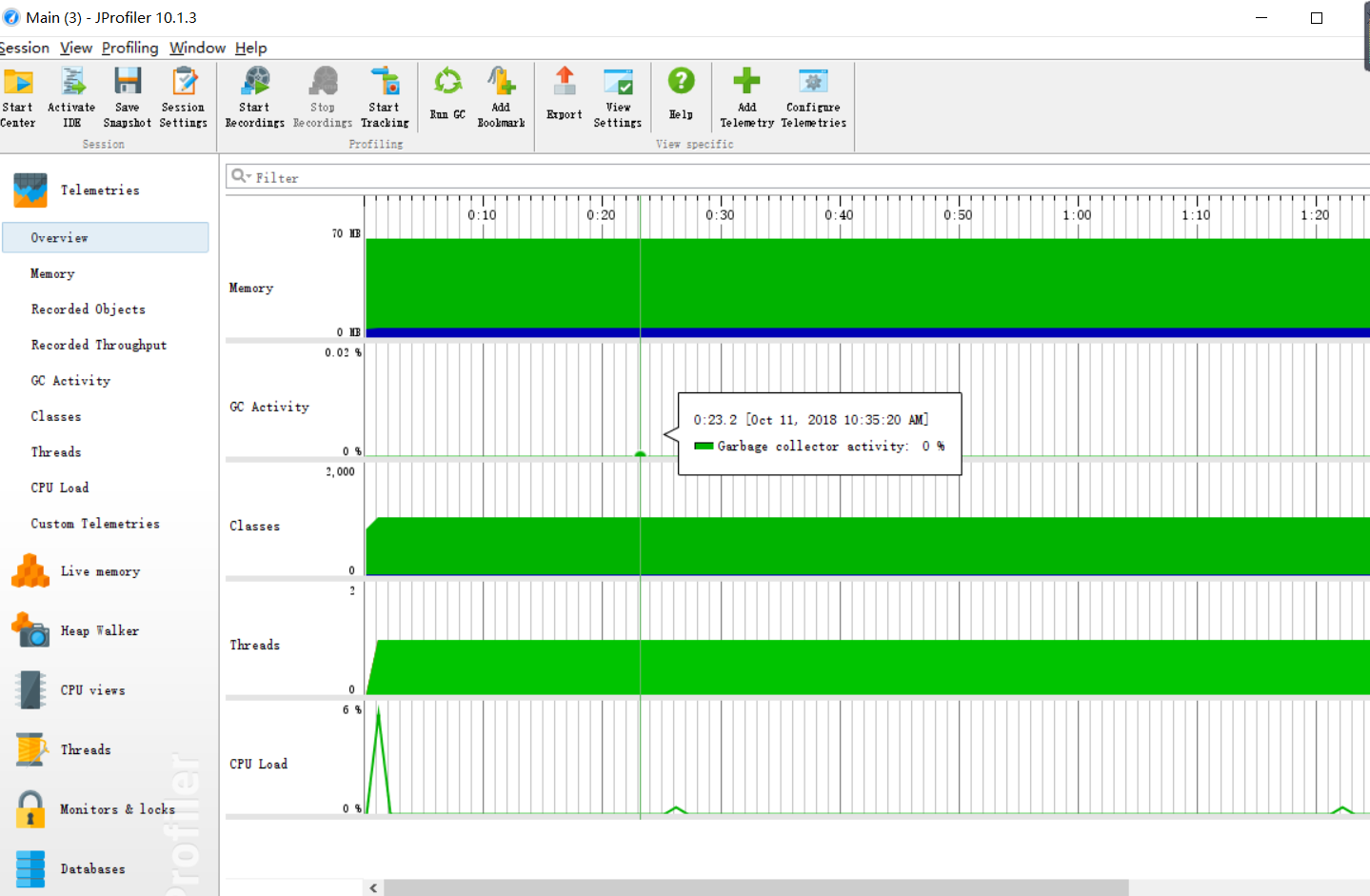
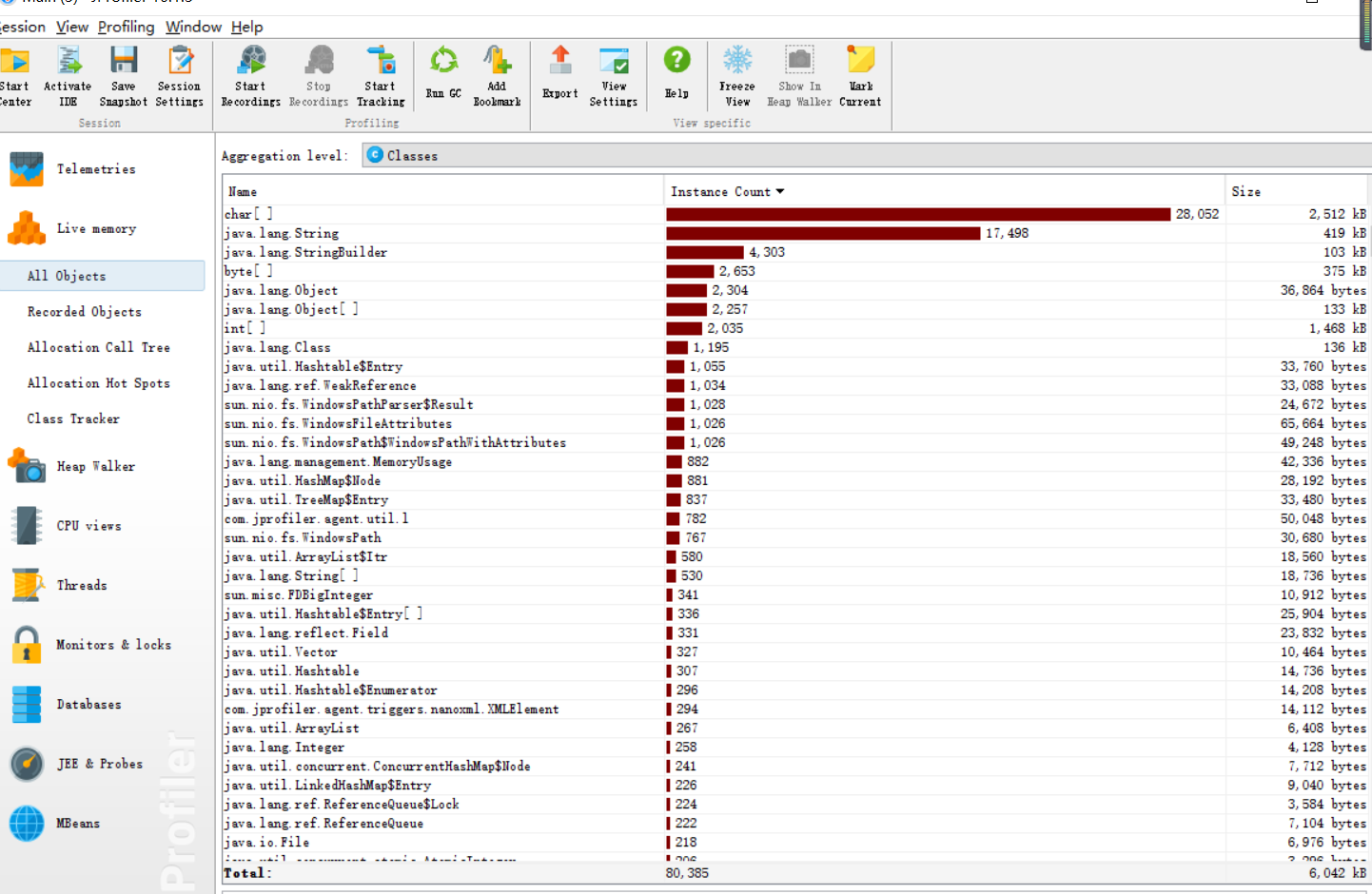
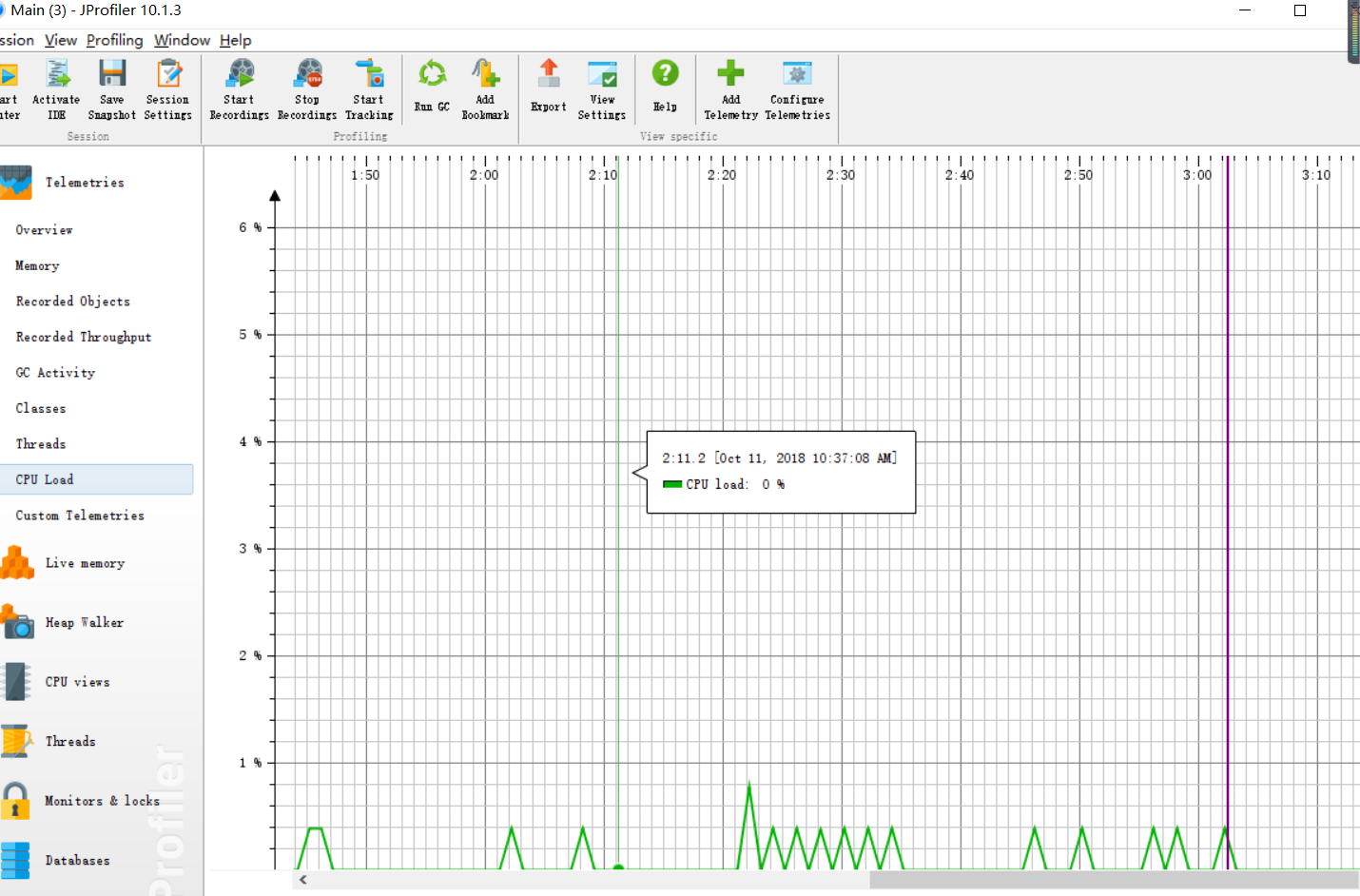
6、效能分析
7、结合在构建之法中学习到的相关内容与结对项目的实践经历,描述结对的感受,是否1+1>2?

- 实验感受:在这次实验中,由于有上一次的饰演的基础,对原来的代码有了优化,但对于GUI界面的实现,还没有能过够很好的实现,对于这方面的知识还不能很好的实现,这是这次实验中遇到的较大的困难,我会在后面将其补上,在之前所想要实现的功能和自己的能力相悖,所以导致后面界面不能够完全实现,但我一定会克服这一困难。
- 在这次的结对编程中,由于在之前的结对经验不足,在这次实验中并能很好的分配其中的任务,让这次试验一开始出现了较大的困难,沟通方面出现了一些歧义,不够在后来的实验中慢慢的能够克服,让实验走向正轨,这次实验并没有完成的很好,实际上只能达到1+1=0.9的程度,我们会在后面的实验中做到>2的!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号