
一、消息堆积与消费延迟概念
消息处理流程中,如果 Consumer 的消费速度跟不上 Producer 的发送速度,MQ 中未处理的消息会越来越多(进的多出的少),这部分消息就被称为堆积消息。消息出现堆积进而会造成消息的消费延迟。
以下场景需要重点关注消息堆积和消费延迟问题:
- 业务系统上下游能力不匹配造成的持续堆积,且无法自行恢复。
- 业务系统对消息的消费实时性要求较高,即使是短暂的堆积造成的消费延迟也无法接受。
二、产生原因分析
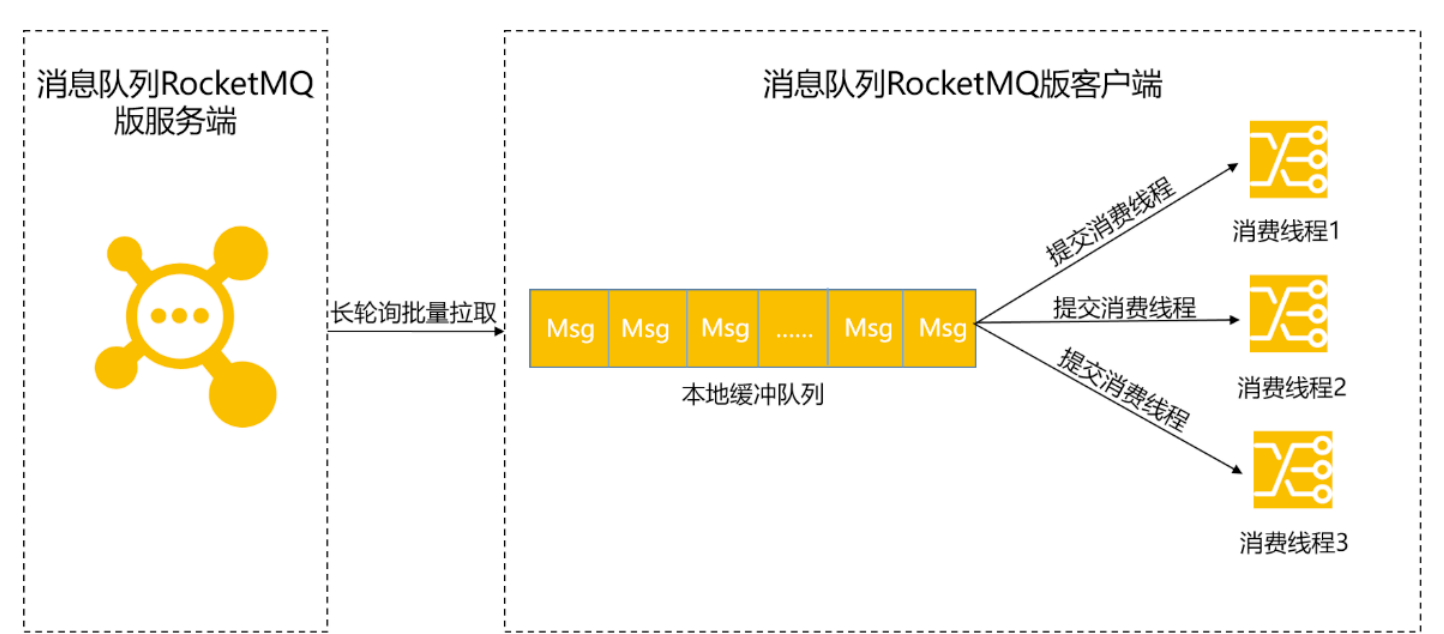 Consumer 使用长轮询 Pull 模式消费消息时,分为以下两个阶段:
Consumer 使用长轮询 Pull 模式消费消息时,分为以下两个阶段:
1、消息拉取
Consumer 通过长轮询 Pull 模式批量拉取的方式从服务端获取消息,将拉取到的消息缓存到本地缓冲队列中。对于拉取式消费,在内网环境下会有很高的吞吐量,所以这一阶段一般不会成为消息堆积的瓶颈。
一个单线程单分区的低规格主机(Consumer,4C8G),其可达到几万的 TPS。如果是多个分区多个线程,则可以轻松达到几十万的 TPS。
2、消息消费
Consumer 将本地缓存的消息提交到消费线程中,使用业务消费逻辑对消息进行处理,处理完毕后获取到一个结果。这是真正的消息消费过程。此时 Consumer 的消费能力就完全依赖于消息的消费耗时和消费并发度了。如果由于业务处理逻辑复杂等原因,导致处理单条消息的耗时较长,则整体的消息吞吐量肯定不会高,此时就会导致 Consumer 本地缓冲队列达到上限,停止从服务端拉取消息。
3、结论
消息堆积的主要瓶颈在于客户端的消费能力,而消费能力由消费耗时和消费并发度决定。注意,消费耗时的优先级要高于消费并发度。即在保证了消费耗时的合理性前提下,再考虑消费并发度问题。
三、消费耗时
影响消息处理时长的主要因素是代码逻辑。而代码逻辑中可能会影响处理时长代码主要有两种类型:CPU 内部计算型代码和外部 I/O 操作型代码。
通常情况下代码中如果没有复杂的递归和循环的话,内部计算耗时相对外部 I/O 操作来说几乎可以忽略。所以外部 IO 型代码是影响消息处理时长的主要症结所在。
外部 IO 操作型代码举例:
读写外部数据库,例如对远程 MySQL 的访问
读写外部缓存系统,例如对远程 Redis 的访问
下游系统调用,例如 Dubbo 的 RPC 远程调用,Spring Cloud 的对下游系统的 Http 接口调用
关于下游系统调用逻辑需要进行提前梳理,掌握每个调用操作预期的耗时,这样做是为了能够判断消费逻辑中 IO 操作的耗时是否合理。通常消息堆积是由于下游系统出现了服务异常或达到了 DBMS 容量限制,导致消费耗时增加。
服务异常,并不仅仅是系统中出现的类似 500 这样的代码错误,而可能是更加隐蔽的问题。例 如,网络带宽问题。
达到了 DBMS 容量限制,其也会引发消息的消费耗时增加。
四、消费并发度
一般情况下,消费者端的消费并发度由单节点线程数和节点数量共同决定,其值为单节点线程数*节点数量。不过,通常需要优先调整单节点的线程数,若单机硬件资源达到了上限,则需要通过横向扩展来提高消费并发度。
单节点线程数,即单个 Consumer 所包含的线程数量
节点数量,即 Consumer Group 所包含的 Consumer 数量
对于普通消息、延时消息及事务消息,并发度计算都是单节点线程数*节点数量。但对于顺序消息则是不同的。顺序消息的消费并发度等于Topic 的 Queue 分区数量。
1)全局顺序消息:该类型消息的 Topic 只有一个 Queue 分区。其可以保证该 Topic 的所有消息被 顺序消费。为了保证这个全局顺序性,Consumer Group 中在同一时刻只能有一个 Consumer 的一 个线程进行消费。所以其并发度为 1。
2)分区顺序消息:该类型消息的 Topic 有多个 Queue 分区。其仅可以保证该 Topic 的每个 Queue 分区中的消息被顺序消费,不能保证整个 Topic 中消息的顺序消费。为了保证这个分区顺序性, 每个 Queue 分区中的消息在 Consumer Group 中的同一时刻只能有一个 Consumer 的一个线程进行 消费。即,在同一时刻最多会出现多个 Queue 分蘖有多个 Consumer 的多个线程并行消费。所以 其并发度为 Topic 的分区数量。
五、单机线程数计算
对于一台主机中线程池中线程数的设置需要谨慎,不能盲目直接调大线程数,设置过大的线程数反而会带来大量的线程切换的开销。理想环境下单节点的最优线程数计算模型为:C *(T1 + T2)/ T1。
- C:CPU 内核数
- T1:CPU 内部逻辑计算耗时
- T2:外部 IO 操作耗时
最优线程数 = C _(T1 + T2)/ T1 = C _ T1/T1 + C _ T2/T1 = C + C _ T2/T1
注意,该计算出的数值是理想状态下的理论数据,在生产环境中,不建议直接使用。而是根据 当前环境,先设置一个比该值小的数值然后观察其压测效果,然后再根据效果逐步调大线程 数,直至找到在该环境中性能最佳时的值。
六、如何避免
为了避免在业务使用时出现非预期的消息堆积和消费延迟问题,需要在前期设计阶段对整个业务逻辑进行完善的排查和梳理。其中最重要的就是梳理消息的消费耗时和设置消息消费的并发度。
1、梳理消息的消费耗时
通过压测获取消息的消费耗时,并对耗时较高的操作的代码逻辑进行分析。梳理消息的消费耗时需要关注以下信息:
- 消息消费逻辑的计算复杂度是否过高,代码是否存在无限循环和递归等缺陷。
- 消息消费逻辑中的 I/O 操作是否是必须的,能否用本地缓存等方案规避。
- 消费逻辑中的复杂耗时的操作是否可以做异步化处理。如果可以,是否会造成逻辑错乱。
2、设置消费并发度
对于消息消费并发度的计算,可以通过以下两步实施:
- 逐步调大单个 Consumer 节点的线程数,并观测节点的系统指标,得到单个节点最优的消费线程数和消息吞吐量。
- 根据上下游链路的流量峰值计算出需要设置的节点数
节点数 = 流量峰值 / 单个节点消息吞吐量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号