
leetcode 456. 132 Pattern 132模式 题解(栈)
【例子1】132 Pattern
https://leetcode.com/problems/132-pattern/description/
Given a sequence of n integers a1, a2, ..., an, a 132 pattern is a subsequence ai, aj, ak such that i < j < k and ai < ak < aj. Design an algorithm that takes a list of n numbers as input and checks whether there is a 132 pattern in the list.
Note: n will be less than 15,000.
思路:求一个list中是否有132模式。利用一个栈,从后往前遍历数组,再设置一个second变量。栈中记录的是当前遍历到的最大值,而second则用来记录目前第二大的数。只要目前遍历的数,小于栈顶的最大值和second,这时候就刚好满足132模式。
代码:


bool find132pattern(vector<int>& nums) { if(nums.size()<3)return false; stack<int> s; int second=INT_MIN; for(int i=nums.size()-1;i>=0;i--){ if(nums[i]<second)return true; while(!s.empty()&&nums[i]>s.top()){ second = s.top(); s.pop(); } s.push(nums[i]); } return false; }
【例子2】直方图中的最大矩形
https://leetcode.com/problems/largest-rectangle-in-histogram/description/
Given n non-negative integers representing the histogram's bar height where the width of each bar is 1, find the area of largest rectangle in the histogram.

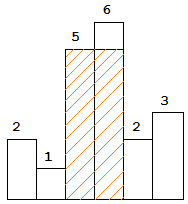
思路:这道题目有多种解法,例如:动态规划、分治法、线段树等等。这里主要讲一下用栈解决的思路。那么,最大矩形什么时候出现呢?
首先,最大矩形必定恰好包含了图中的一个直方,例如上面的右图。因此,我们只要计算出恰好包含第一个直方的最大矩形、恰好包含第二个直方的.最大矩形..然后得到其中的最大值就行了。
接着,考虑如何计算这些矩形的面积,它们的高就是恰好包含的直方的高h,只要计算各个矩形的跨度(L,R)即可,L表示矩形开始的位置,R表示结束位置。这时候的矩形面积就是h*(R-L+1)。如上面的右图的阴影部分,R=3,L=2。
最后,最大矩形的右边界很容易确定,只要出现一个直方h[j]小于当前直方h[i],就说明恰好包含h[i]的最大矩阵的右边界是j-1。但是开始的位置在哪里呢?这就需要用到栈,用栈来记录恰好包含第i个直方的最大矩阵的左边界。具体的计算过程,从左至右先将直方的下标逐一入栈s,如果遇到h[i]<s.top(),那么,就说明恰好包含h=s.top()的最大矩阵在R=i-1的位置结束,而它的左边界就是在s.pop()之后,L=s.top()+1,这时候的面积就是h*(R-L+1)。计算的过程中,与之前的结果比较大小,得到直方图的最大矩阵面积。
注意:按照上面的思路,我们在遍历h数组之后,最后的栈中并不一定为空。这是因为,存在直方的高度小于最右边的直方。在开始阶段,往数组h最右边插入一个0作为结束,就能够计算到每一个直方的最大矩阵面积了。
代码:
int largestRectangleArea(vector<int>& h) { h.push_back(0); int res = 0; vector<int> pos; for(int i=0;i<h.size();i++){ while(!pos.empty()&&h[i]<=h[pos.back()]){ int cur = h[pos.back()]; pos.pop_back();//出栈 int sidx = pos.empty() ? -1:pos.back(); res = max(res, cur*(i-sidx-1)); } pos.push_back(i); } return res; }
【例子3】最大全1子矩阵
https://leetcode.com/problems/remove-duplicate-letters/description/
Given a 2D binary matrix filled with 0's and 1's, find the largest rectangle containing only 1's and return its area.
For example, given the following matrix:
1 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 0 0 1 0
Return 6.
思路:这个题目本质上和上一题是相同的,可以相互转化,上一题中可以转化为一个0-1矩阵,求最大全1子矩阵的大小即可。这一个问题也可以将各行分别看作直方图的x坐标,求出当前的最大子矩阵,然后比较得到各行当中的最大值即可。例如,第1-1行可以看作是一个直方图,第1-2行可以看作是一个直方图....矩阵中的最大全1子矩阵就从各个直方图的最大矩阵中去找。不多说了,上代码:
代码:
int maximalRectangle(vector<vector<char>>& m) { if(m.empty()) return 0; vector<int> h(m[0].size(),0); int res = 0; for(int i=0;i<m.size();i++){ for(int j=0;j<m[0].size();j++){ if(m[i][j]=='0') h[j] = 0; else h[j]++; } res = max(res,largestRectangleArea(h)); } return res; } int largestRectangleArea(vector<int>& h) { h.push_back(0); int res = 0; vector<int> pos; for(int i=0;i<h.size();i++){ while(!pos.empty()&&h[i]<=h[pos.back()]){ int cur = h[pos.back()]; pos.pop_back(); int sidx = pos.empty() ? -1:pos.back(); res = max(res, cur*(i-sidx-1)); } pos.push_back(i); } return res; }
【例子4】Verify Preorder Serialization of a Binary Tree
https://leetcode.com/problems/verify-preorder-serialization-of-a-binary-tree/description/
One way to serialize a binary tree is to use pre-order traversal. When we encounter a non-null node, we record the node's value. If it is a null node, we record using a sentinel value such as #.
_9_
/ \
3 2
/ \ / \
4 1 # 6
/ \ / \ / \
# # # # # #
For example, the above binary tree can be serialized to the string "9,3,4,#,#,1,#,#,2,#,6,#,#", where # represents a null node.
Given a string of comma separated values, verify whether it is a correct preorder traversal serialization of a binary tree. Find an algorithm without reconstructing the tree.
思路:验证是否为二叉树的先序序列。从左到右将各字符入栈,如果遇到栈顶字符是“#”,当前待压入栈中的字符是“#”,就说明栈顶的前一个字符是叶子节点,这时候,连续两个pop(),消去这个叶子节点。这时候,叶子节点的位置就是null,需要将“#”压入栈中。如果满足前面的条件,继续消去。如果遍历完整个字符串之后,栈中留下的只有一个“#”,就说明是先序序列。不过,如果出现连续三个“#”或者栈中只剩两个“#”的情况,这时候肯定不是先序序列,这要在栈的操作过程中加以判断。
另外,参考别人的discuss,二叉树只有度为0和度为2的两种节点,而根据公式:n0 = n2 + 1。如果在遍历的过程中遇到了n0>=n2+1(这时候遍历还未结束),就说明这个序列有问题了。同样,遍历完之后,如果n0!= n2 + 1,这也说明不是先序序列。
代码:
bool isValidSerialization(string pre) { char tmp; bool isNum = false; pre += ','; vector<char> s; for(auto tmp:pre){ if(tmp=='#'){ while(!s.empty()&&s.back()=='#'){ s.pop_back(); if(s.empty()||s.back()=='#')return false;//case“###” s.pop_back(); } s.push_back('#'); }else if(tmp==','){ if(isNum)s.push_back('n'); isNum = false; }else{ isNum = true; } } return s.back()=='#'&&s.size()==1; }
【例子5】二叉树的后序遍历(用栈)
思路:二叉树的用栈后序遍历,比用栈前序、中序遍历都要复杂,方法也比较多。
思路一,根据(左右中)的顺序,先将r压栈,再出栈,将r->left压栈,将r->right压栈,再将栈顶(r->right)出栈....这样就能够遍历到二叉树的每个节点,最后栈为空。可以发现,这样的出栈序列和二叉树的后序序列刚好相反。所以,只要在出栈的时候讲val存入vector数组,再反转即可,也可以采用insert函数,将每一次的val插入vector的首位。
思路二,如果目的仅仅是输出后序序列,那么,是否输出当前节点,只需要看看它的左右节点是否输出,或者左右节点是否为空。所以,添加一个pre指针,指向前一次输出的节点。在栈不为空的情况下,按照s.top()->right、s.top()->left的方式依次入栈。当目前栈顶元素的左右节点都未null,或者,pre节点是左节点且右子树为null,pre节点是右节点的时候,就输出栈顶val,再出栈,pre就等于当前出栈节点。这样循环下去,直到栈为空。
思路三,先从p节点一直往左下走,直到p->left=NULL,这时候,再判断p->right,是否为NULL,如果是则将p出栈,否则,需要将p->right入栈。如果p->right是叶子节点,则出栈,这时候需要添加一个指针为q,指向p->right,代表此节点已经被访问。这时候回退到了p节点,如果p->right==q,就知道它的右子节点已经被访问了,故继续出栈,访问p节点,这时候的q指针就指向p节点。
思路四,和前面两种思路差不多,都用到pre前驱节点,对于每一个栈顶节点(初始是root),看看是否需要继续添加它的子节点入栈,不需要的话就输出这个节点,并出栈,否则就分别就左右子节点入栈。判断是否需要的关键在于当前的pre节点是哪个。
总结起来,可以用q来表示已经访问过的指针,q初始值为NULL,只有在visit(p->right)之后,q=p->right,所以,当p->right = q时,这时候就需要访问p节点了。
//思路一: vector<int> postorderTraversal(TreeNode* r) { vector<int> v; if (!r) return v; stack<TreeNode*> s; s.push(r); while(!s.empty()){ TreeNode* cur = s.top(); v.insert(v.begin(),cur->val); s.pop(); if(cur->left)s.push(cur->left); if(cur->right)s.push(cur->right); } return v; } //思路二: vector<int> postorderTraversal(TreeNode* r) { vector<int> v; if (!r) return v; stack<TreeNode*> s; TreeNode* pre; s.push(r); while(!s.empty()){ TreeNode* cur = s.top(); if((!cur->left&&!cur->right)||(pre == cur->left&&!cur->right)||(pre&&pre==cur->right)){ v.push_back(cur->val); s.pop(); pre = cur; }else{ if(cur->right)s.push(cur->right); if(cur->left)s.push(cur->left); } } return v; } //思路三: vector<int> postorderTraversal(TreeNode* r) { vector<int> v; if (!r) return v; stack<TreeNode*> s; TreeNode* p = r; do{ while(p){ //0,最开始将左节点全部入栈 s.push(p); p=p->left; } TreeNode* pre = NULL; while(!s.empty()){ p = s.top(); if(p->right==pre){//1,访问过、或者右子树为空才出栈 v.push_back(p->val); pre = p; s.pop(); }else{//2,没有访问过、跳出继续将p->right的一路左子树入栈,执行0 p = p->right; break; } } }while(!s.empty()); return v; }
vector<int> postorderTraversal(TreeNode* r) { vector<int> v; if (!r) return v; stack<TreeNode*> s; s.push(r); //pre表示后序序列中节点的前驱 //最开始的pre不能为空,要将pre和cur的左右子节点进行比较 //当访问最左边节点时,如果pre=NULL且右节点==NULL,这一点就不能够入栈 TreeNode *pre =new TreeNode(0); while(!s.empty()){ TreeNode* cur = s.top(); //有左节点,且左右节点都还没访问过,入栈 if(cur->left&&pre!=cur->left&&pre!=cur->right){ s.push(cur->left); //有右节点,且没有访问过,而左节点访问过 }else if(cur->right&&pre!=cur->right&&(!cur->left||cur->left == pre)){ s.push(cur->right); }else{ //其他情况,由于栈后进先出,栈顶出栈即可,这时候pre就指向cur v.push_back(cur->val); pre = cur; s.pop(); } } return v; }
【例子6】中缀表达式求值
思路:中缀就是我们平常所见的表达式序列。直接进行中缀求值需要用两个栈,一个栈存操作数,一个栈存放操作符,包括“+-*/()”。如果遍历的操作符优先级不比栈顶操作符大,就将栈顶操作符出栈,同时将两个操作数出栈,计算得到的结果再入栈。
为了减少操作数压栈入栈的次数,设置一个cur变量,代表当前得到的操作数。在需要计算的时候,只需将一个操作数出栈,计算得到的结果仍然是cur,直到目前的操作符优先级大于当前栈顶的优先级,才将cur压入栈中。
另外,考虑到遍历之后,两个栈中仍然有数据需要计算,这样就会有比较重复的代码了。为了解决这个问题,只需在最开始的时候,给表达式加上括号,这样在遍历之后,两个栈全部清空,这时候表达式的值就是cur。
#include<iostream> #include<cstring> #include<stack> #include<unordered_map> #include<unordered_set> #include<functional> using namespace std; unordered_map<char, function<int (int, int )>> op_map = { { '+' , [] (int a, int b) { return a + b; } }, { '-' , [] (int a, int b) { return a - b; } }, { '*' , [] (int a, int b) { return a * b; } }, { '/' , [] (int a, int b) { return a / b; } } }; unordered_map<char, int> priority = { {'+',1},{'-',1},{'*',2},{'/',2},{'(',0} }; /* 利用两个栈进行模拟计算 */ int Compute(string s) { stack<char> opstk; //操作符栈 stack<int> numstk; //操作数栈 int pos = 0; s = "(" + s + ")"; int cur; while(pos < s.length()) { if (s[pos] == '('){ opstk.push('('); if(s[++pos]=='-')cur = 0;//负号必定出现在'('的后面,变成减法 }else if (s[pos] == ')'){ //括号内计算得到的cur不需要入栈 while (opstk.top() != '('){ cur = op_map[opstk.top()](numstk.top(), cur);//只需拿cur与栈顶数字进行计算 numstk.pop(); opstk.pop(); } opstk.pop(); //删除'(' pos++; }else if (s[pos] >= '0' && s[pos] <= '9'){ int integer = 0; while (s[pos] >= '0' && s[pos] <= '9'){ integer = integer*10 + (s[pos++] - '0'); } cur = integer; }else{ while(priority[s[pos]] <= priority[opstk.top()]){ cur = op_map[opstk.top()](numstk.top(), cur); numstk.pop(); opstk.pop(); } numstk.push(cur); opstk.push(s[pos++]); } } return cur; } int main() { string s = "-2+3*(-2+3*4)-(-(-2))"; cout << "结果为:" << Compute(s) << endl;//输出结果为26 return 0; }
【例子7】 用栈模拟汉诺塔问题
就是将一个递归问题用栈写出来。
代码:
#include <queue> #include<iostream> #include<stack> #include<cstdio> using namespace std; /*定义状态*/ typedef struct Statute{ char left,right,mid; int n; Statute(){}; Statute(char L,char m,char r,int n):left(L),mid(m),right(r),n(n){}; }Statute; /*用栈*/ void HanNouWei(Statute s){ stack<Statute> stk; stk.push(s); int cnt = 0; while(!stk.empty()){ Statute cur = stk.top(); stk.pop(); if(cur.n==1){ cout << " from "<< cur.left << " to " << cur.right << endl; }else{ stk.push(Statute(cur.mid,cur.left,cur.right,cur.n-1)); //此处并不能够直接输出结果,而应该将这一步的状态放入栈中 //cout << " from "<< cur.left << " to " << cur.right << endl; stk.push(Statute(cur.left,cur.mid,cur.right,1)); stk.push(Statute(cur.left,cur.right,cur.mid,cur.n-1)); } } } /*递归*/ void hanoi(Statute s){ Statute cur = s; if(cur.n == 1) { cout << " from "<< cur.left << " to " << cur.right << endl; return; } else { hanoi(Statute(cur.left,cur.right,cur.mid,cur.n-1)); cout << " from "<< cur.left << " to " << cur.right << endl; hanoi(Statute(cur.mid,cur.left,cur.right,cur.n-1)); } } int main(){ Statute s = Statute('A','B','C',4); HanNouWei(s); cout << "==============================="<< endl; hanoi(s); return 0; }
总结:如果问题的结构类似于(A(B)(C(D(E)))),其中A代表原问题,B、C、D分别代表嵌套的子问题,一个括号表示一个完整子问题的左右边界,完整意味着这个子问题的解可能是最后的最优解,或者说是最终解中的一部分。在这里原问题的解决需要先解决嵌套的子问题,这时候就可以用栈来解决问题。这里我总结出一个不成熟的方法,既然括号的匹配是最典型的的栈问题,那么,我们可以用括号来划分那些完整的子问题。就拿例子2来说,2,1,5,6,2,3,可以划分为( (2), 1, ((5, (6)), 2, (3))),每一个括号里面只有一个单独的数字,括号就刚好代表该高度的矩形的跨度。即使不知道能否用栈,只要我们能够标明括号,来划分完整的子问题,这就很容易得到用栈的解决方法了。左括号入栈,右括号出栈,其他操作.....这样执行下去,直到找到答案。另外,拿例子1来说,1, 3, 6, 4, 2,用栈的话就是(((2), 4), 6), 3, 1,当然,能够这样做的前提就是,我们需要意识到数组从右至左最大值和次大值的重要性。
【例子8】[LeetCode] Closest Binary Search Tree Value II 二分搜索树中离target最近的k个值
Given a non-empty binary search tree and a target value, find k values in the BST that are closest to the target.
Note:
- Given target value is a floating point.
- You may assume k is always valid, that is: k ≤ total nodes.
- You are guaranteed to have only one unique set of k values in the BST that are closest to the target.
Follow up:
Assume that the BST is balanced, could you solve it in less than O(n) runtime (where n = total nodes)?
思路:这道题是寻找二分搜索树中和target最接近的k个点(突然想起了最近邻法)。这里的思路还是比较简单的,二分搜索树的中序序列,恰好是从小到大,所以,我们只要中序遍历,用一个vector(在这里其实是充当队列)来存储得到的k个点,如果遍历到第k+1个位置,就看看k该节点和vector中第一个节点,哪个里target最近。。。所以,这里其实就是在中序遍历上面加点visit()代码即可,既可以用到栈,也可以用递归。这里时间复杂度o(n),空间复杂度是o(k)。
这里还有一个lgn的思路,用到两个栈,一个栈用来存储比tartget小的若干个数,另一个存储比target大的若干个数。先init两个栈,找到离target最近的两个值(一个小于或者等于,一个大于)分别入栈。接着,归并这两个栈,如果还没有达到k个,则需要从这两个栈中的节点出发,再取寻找那些“稍远”的点入栈,越到栈顶,离target越近。继续归并。
如果简化这道题,只用寻找一个点的话,则可以用到二分法,时间复杂度是lgn。
代码:
【例子9】Ternary Expression Parser三元表达式解析
Given a string representing arbitrarily nested ternary expressions, calculate the result of the expression. You can always assume that the given expression is valid and only consists of digits 0-9, ?, :, T and F (T and Frepresent True and False respectively).
Note:
- The length of the given string is ≤ 10000.
- Each number will contain only one digit.
- The conditional expressions group right-to-left (as usual in most languages).
- The condition will always be either
TorF. That is, the condition will never be a digit. - The result of the expression will always evaluate to either a digit
0-9,TorF.
Example 1:
Input: "T?2:3" Output: "2" Explanation: If true, then result is 2; otherwise result is 3.
Example 2:
Input: "F?1:T?4:5" Output: "4"
思路:这里从后往前遍历,将数全部入栈,忽略冒号,如果遇到?,则看看前面的字符是T还是F,有选择地进行出栈即可。如果要从左往右遍历的话,那么,加得等到所有?的index都入栈之后,才能够从最后一个?开始计算。
这里还有一个比较巧妙的递归解法,考虑到合法表达式中?和:的数目总是相等的,所以,可以设置一个cnt1计算?的个数,cnt2计算:的个数,当cnt1 == cnt2时,根据?前面的‘T’或‘F’选择:前面的子串或者后面的子串进行计算。
还有一个使用STL中内置函数find_last_of的简单方法,每次只需找到字符串中最后一个?,这时候后面必定紧跟着A:B,计算出这一步的结果,再放回字符串中,循环下去就能够得到整个式子的结果了。
【例子10】Verify Preorder Sequence in Binary Search Tree
验证一个list是不是一个BST的preorder traversal sequence。
Given an array of numbers, verify whether it is the correct preorder traversal sequence of a binary search tree.
You may assume each number in the sequence is unique.
Follow up:
Could you do it using only constant space complexity?
思路:二分数例如,123 4 567,它的先序序列是421 3 65 7,所以可以从左开始依次将数字入栈,如果遇到比top大的数字,则pop,将比当前数字小的都出栈。这时将这个节点坐标的节点都出栈了,同时记住最后一个出栈的数字,为min,min就是这个数字的父母节点。再将当前数字入栈,如果按照先序序列的话,后面的数字必定都比min大。例如,4 2 1 3 -> 4 3(min 2)-> 4 3 6 -> 6 (min 4) -> 6 5 7 -> 7 (min 6)。
另一种思路,使用常量空间。直接在序列上面进行修改,其实也只需改掉遍历时的前一个数字即可。另外,这个问题同样可以用递归来解决。
