
es学习
数据整合


基于海量数据的搜索与分析,性能很强大
大数据的检索和分析
es概览
几个分布式搜索引擎的区别
倒排索引 (所有搜索引擎共有的特点)
lucene: 基于java的全文搜索引擎(高性能,功能全,无分布式、无高可用);是基于Java的类库, 其中集成了许多api方法; 可以理解Lucene是一个jar包; 只能结合Java使用; 集群十分复杂,需要自己实现;
solr与es都是基于lucene的搜索引擎;solr本质上是对Lucene进行的一层封装, Apche的开源项目;可以以容器的方式进行部署;可以实现集群;可靠性,容错性高
solr可tomcat部署;
es支持pb级 (查询搜索很快);支持分布式;restful接口,可供其他语言使用; 可扩展性更高;ES为用户提供近实时(速度很快)的搜索服务
GitHub 之前用的 solr 后续替换了ES , 使用ES的查询搜索速度是相当快的;ES官网 https://www.elastic.co/cn/what-is/elasticsearch
es用途:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能检测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
核心术语


索引 index 相当于数据库中的 表
类型 type (新版ES中 已经没有类型了, 相当于分类/类别/分组的概念) (6.x之前可以使用) 表逻辑类型 (某张表index, 这个表可能逻辑上都归类为吃的商品, 这个归类 :吃就是类型)
文档 document相当于数据库中的行 一行数据
字段 fields 对应数据库中的 列
映射 mapping 表结构定义 schema 类型,是否是分词
近实时 NRT 新增文档在1s内可被搜索到
节点 node 每一个服务器
分片 shard shard = primary shard(主分片)把索引库拆分为多份,分别放在不同的节点上,比如有3个节点,3个节点的所有数据加在一起是一个完整的索引库。分别保存到三个节点上,目的为了水平扩展,提高吞吐量。
备份 replica = replica shard(备份节点)每个shard的备份。
倒排索引
去根据单词搜索文档,搜索的性能比正排索引来的高

不仅可以记录属性值,还可以记录单次频率和出现的位置,重复次数(计分)
es 安装
https://class.imooc.com/lesson/1231#mid=29315
创建索引后,都会出现一个Unassigned,怎么去除呢?
看文档:https://www.cnblogs.com/mzli/p/12273735.html
ulimit -a 查看配置进程数
es-head可视化插件安装
google插件商店里有
手动安装
elasticsearch.conf配置Networt 模块

es集群状态
green 所有的主分片和副本分片都已经分配。你的集群式100%可用的。
yellow 所有的主分片已经分片,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。
red 至少一个主分片都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常
es语法
es基本命令
索引相关命令
https://class.imooc.com/lesson/1231#mid=29316
es索引mapping设置
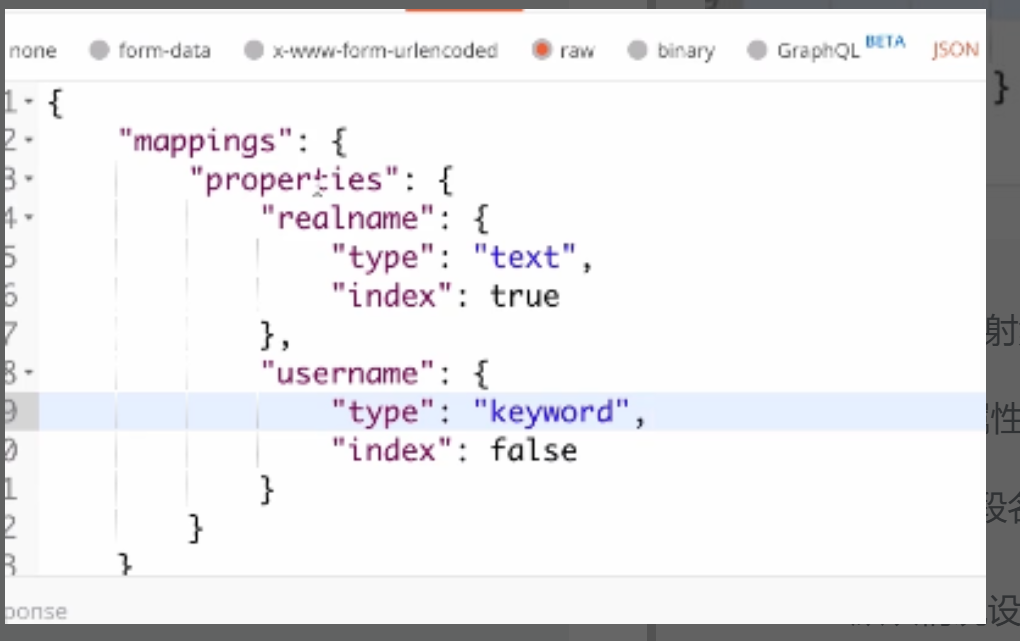
index:false 默认情况设置为true (可以不写); 设置为false,不被索引,在查询的时候不会被查询到(列如密码就使用这个)
keyword精确匹配,不会被分词;text会被分词查询
https://class.imooc.com/lesson/1231#mid=29317
mapping结构可以设置数组,但是数组的元素类型要一致,都是string或者integer,不能两个混在一起
文档操作
- 文档添加
(自动设置mapping)
https://class.imooc.com/lesson/1231#mid=29318
用法put 竟然也可以添加数据,如果不设置索引ID 就必须用post了
- 文档删除
并不是从磁盘上真正的删除,而是逻辑删除;
DELETE /my_doc/_doc/1 - 文档更新
- 局部
POST /my_doc/_doc/1/_update { "doc": { "name": "慕课" } }- 全量替换:
PUT /my_doc/_doc/1 { "id": 1001, "name": "imooc-1", "desc": "imooc is very good, 慕课网非常牛!", "create_date": "2019-12-24" }
Luence需要全量替换 (所有属性字段值都要写)
es底层就是Luence,只不过es的post增量方法是对 做了一层二次封装;
每次修改/删除后, version都会改变, 删除也相当于一次修改(修改了逻辑删除状态),
即使删除不存在的数据,version也会改变
https://class.imooc.com/lesson/1231#mid=29319
乐观锁更新
https://class.imooc.com/lesson/1231#mid=29321
ES DSL语法
Domain Specific Language
特定领域语言
https://class.imooc.com/lesson/1231#mid=29326
查询更灵活,有利于复杂查询
查询所有和分页
查询指定字段及分页
POST /shop/_doc/_search
{
"query": {
"match_all": {}
},
"_source": ["id", "nickname", "age"],
"from": 0,
"size": 10
}
https://class.imooc.com/lesson/1231#mid=29327
term/match
term方式,【不会】对查询条件做分词,直接把查询条件的完整词汇进行匹配搜索。
match方式,【会】对查询条件做分词,之后对每个分词进行匹配搜索。
terms搜索是tag的or結合 不是and
https://class.imooc.com/lesson/1231#mid=29328
term关键字的确不对关键字进行分词,但是不代表字段本身不会分词。
既然如此的话,term查询之前,实际上字段的内容可能已经经过分词处理了,所以term对整段文字进行匹配才会查不到数据。
match(operator)/ids
https://class.imooc.com/lesson/1231#mid=29330
POST /shop/_doc/_search
{
"query": {
"match": {
"desc": "慕课网"
}
}
}
# 等同于
{
"query": {
"match": {
"desc": {
"query": "xbox游戏机",
"operator": "or",
"minimum_should_match": "60%"
}
}
}
}
{
"query": {
"ids": {
//"type": "_doc",
"values": ["1001", "1010", "1008"]
}
}
}
# 相当于 select * from shop where desc='xbox' or|and desc='游戏机'
match_phrase
match_phrase 词组匹配,顺序相同且连续
slop允许跳过的词数量
https://class.imooc.com/lesson/1231#mid=29329
multi_match/boost
https://class.imooc.com/lesson/1231#mid=29331
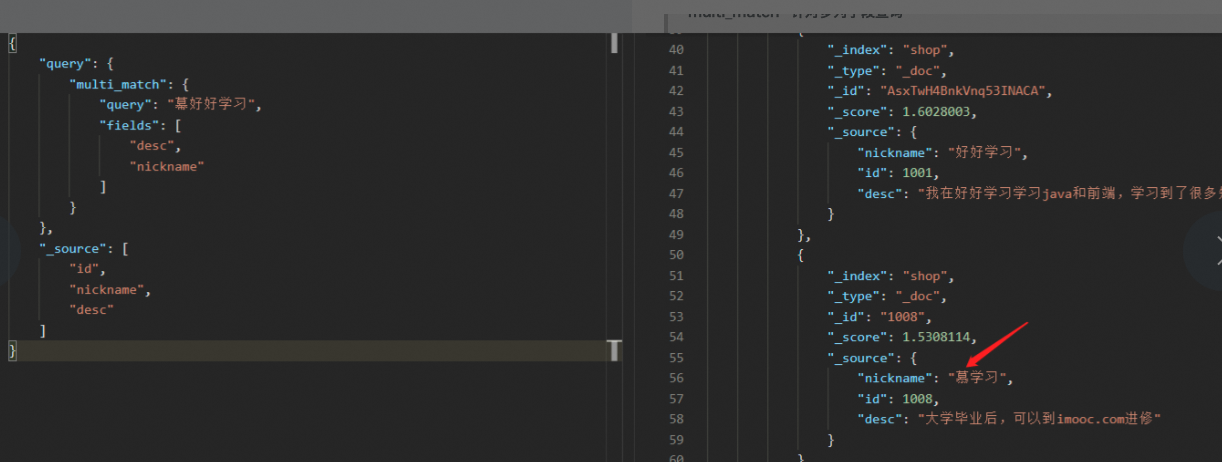
配置权重分数比列
- 查询出的数据中都是按照 "_soure"的大小值进行排序;这些分数是通过文档每个字段匹配关键字汇总得出的比列分数
- 可以给某个字段配置权重(对应匹配分数会乘以对应的权重), 让如果某一字段列出现了关键字分词,那么他出现的"_soure"就更高,也就说明他的排名会变的更高,更容易被用户看到,
bool(must/not/should)
可以通过es-head去自动化生成dsl语句,避免手动操作
bool:{
must:必须匹配,当于数据库中的 AND, must中的内容必须要同时满足
must_not: 不匹配, 相当于数据库中的 != ,must_not中的内容必须都保证不满足
should: 或 ,相当于数据库中的 OR, should中的内容满足其一即可
}
三者按实际先后顺序and拼接,以上面查询出来的结果作后续查询条件的输入,should不会对must结果造成影响
boost加权,提高分数,让数据排在更前面。
https://class.imooc.com/lesson/1231#mid=29332
过滤器(post_filter)
不会根据词语去检索,不会计算数据相关匹配度分数,是根据query已经检索出来的结果作过滤,性能较高
https://class.imooc.com/lesson/1231#mid=29333
不可以复合使用
排序
- es搜索结果默认是按照 "_soure" 关键字所占文档分数比例进行排序的;
- 可以组合排序, 现根据某属性进行排序, 排完序如果有重复的再根据下一个属性进行排序
- type是text,由于分词的原因,不能排序;是keywords的话 可以进行排序;text需要给分词增加一个fields且type是keyword的属性,搜索用a.b的形式排序
https://class.imooc.com/lesson/1231#mid=29334
关键字高亮
https://class.imooc.com/lesson/1231#mid=29524
拓展
查询官方文档
https://class.imooc.com/lesson/1231#mid=29526
深度分页
当查询的[当前页数--from]越大,说明查询的分页深度越深, 这是会影响的一定的性能的
es会控制页数在10000以内,以防止分页深度太深造成的性能上的损害;

和常规分页逻辑不同; es是先全部拿出来,再从中取 size 条数据; 这个过程数据量一多必然会造成性能的损耗
(正常分页逻辑是每次查询, pagesize条数据,切换页数的时候在进行下一次查询)
控制分页数, 将搜索结果控制在100页之内(这样数据量不会超过1万,不会出现深度分页)
滚动搜索
https://class.imooc.com/lesson/1231#mid=29529
- 针对于大量数据的查询
- 第一次查询进行初始化
- 通过scroll_id,来区分,以便进行下一次的滚动查询
- 在查询期间是快照查询, 如果在此期间有 被查询数据进行了修改, 那么用户在查询期间是不会查询出变化的、
可以用来做批量导出的操作,当数据量很多的时候,使用 scroll来做批量导出是完全没有问题的
查看/修改设置
https://class.imooc.com/lesson/1231#mid=29528
批量操作
批量查询
批量搜索_mget与query的主要区别
_mget如果没有查询到,会返回一个"found": false
query如果没有查询到,则直接不返回结果。
/shop/_mget
{
"ids":["1001","1002","1111"]
}
/_search
{
"query": {
"ids": {
"type": "_doc",
"values":["1001", "1003", "1005"]
}
}
}
bulk(批量更新/修改/查询)
https://class.imooc.com/lesson/1231#mid=29530
bulk 批量数据操作请求会加载到内存中,不宜过多,有阈值,1000-5000,一般1000差不多
https://www.elastic.co/guide/cn/elasticsearch/guide/current/bulk.html
es分词器
standard :默认分词,单词会被拆分,大小写会转换小写, 不支持中文。
simple:按照非字母分词(空格, 数字, 符号, 且会去除)。大写会转为小写。
whitespace :按照空格分词。忽略大小写。
stop: 去除无意义单词。比如the/a/an/is...;大写会转为小写
keyword:不做分词。把整个文本作为一个单独的关键词
POST /my_doc/_analyze
{
"analyzer": "standard",
"field": "name",
"text": "text文本"
}
{
"analyzer": "standard",
"text": "My name is Peter Parker,I am a Super Hero. I don't like the Criminals."
}
中文分词器
github elasticsearch-analysis-ik插件;
需要注意藁本的插件,不需要建立ik目录了,直接解压;以及目录不能有空格以及中文等非字符;
自定义中文字典
.在{es}/plugins/ik/config下创建:custom.dic自定义中文字典,也支持站点形式维护txt文件
es集群
es集群架构原理
单个ES节点也是可以为用户服务的,一旦数据量庞大,单个节点可能服务不过来,因此可以增加节点来做集群以提高整个服务的吞吐量,
每个node shard都有一个进程,并且每个shard是并行处理的,提高吞吐量,也就是分布式计算处理的能力(平均分配)
分片可以提高吞吐量,提高性能,因为每个shard都有一个es进程,都可以处理请求,增加节点,也可以达到扩容的机制,水平扩展,replica冗余备份,高可用,以免shard宕机数据丢失。
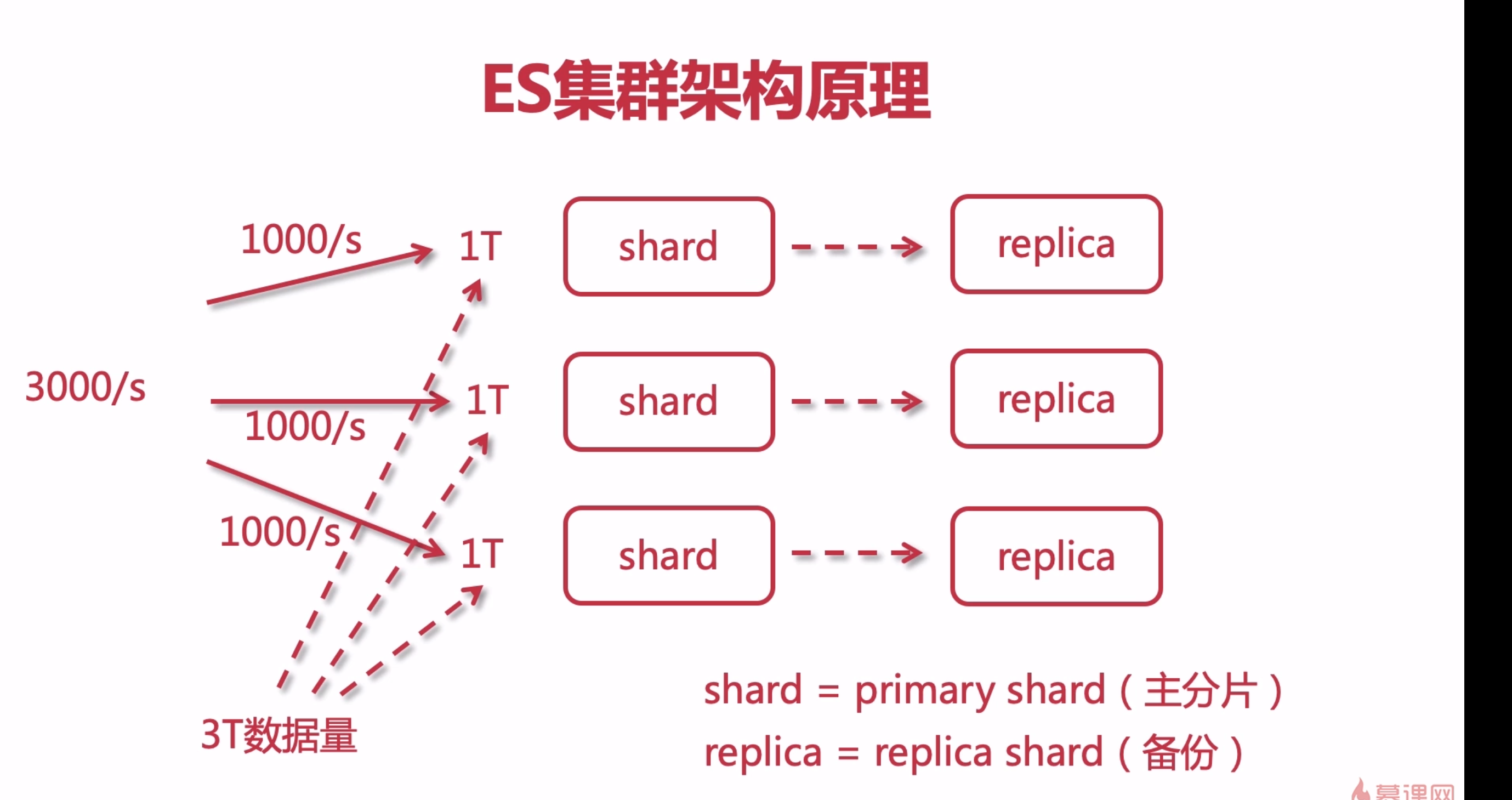
集群概念

高可用:保证主分片不能和备份分片放在同一台服务器节点; 防止服务器挂掉后,其中主备分片的数据都丢失了!因此单机无法实现集群,必须两台以上
https://class.imooc.com/lesson/1231#mid=29532
搭建集群
高版本cluster.initial_master_nodes这个参数必须配置多个master节点,看官方api也是推荐>=3
node.master:true, 代表这个节点未来可能成为master
node.data:true,数据节点
discovery.seed.hosts:服务节点,所有节点ip
查看配置文件
more elasticsearch.yml | grep ^[^#] 过滤掉注释
修改配置文件
# 配置集群名称,保证每个节点的名称相同,如此就能都处于一个集群之内了
cluster.name: imooc-es-cluster
# 每一个节点的名称,必须不一样
node.name: es-node1
# http端口(使用默认即可)
http.port: 9200
# 主节点,作用主要是用于来管理整个集群,负责创建或删除索引,管理其他非master节点(相当于企业老总)
node.master: true
# 数据节点,用于对文档数据的增删改查
node.data: true
# 集群列表
discovery.seed_hosts: ["192.168.1.184", "192.168.1.185", "192.168.1.186"]
# 启动的时候使用一个master节点
cluster.initial_master_nodes: ["es-node1"]
# 配置访问ip
network.publish_host: 192.168.33.31
集群测试
es进行集群配置之后,创建索引的时候,会自动完成主分片和备份分片的配置;且主备不会出现在同一台服务器上;
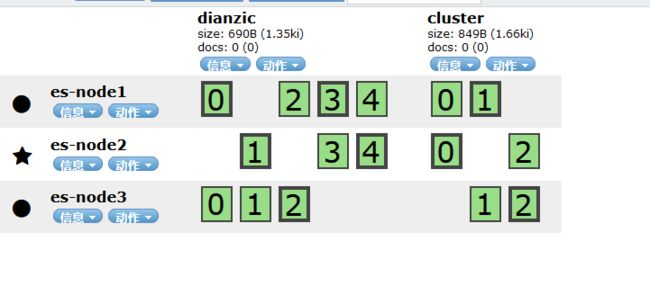
宕机测试
master宕机:
会自动选择一个 配置了 【node.master: true】的服务器节点重新作为master;
原来的master恢复后,原来的那个master会作为 从节点继续服务, 而不会回到主节点

salve从宕机: 将宕机从节点的 主备分片在分配到其他服务器节点上;
宕机后分片会重新同步分配
出处
https://class.imooc.com/lesson/1231#mid=29531
集群脑裂
出现的情况:
当服务器有一个节点想成为master,只要有一票就可以成为主节点,当宕机的master节点恢复服务时,有可能自己给自己投了一票,导致自己又重新成为了master,就导致集群被拆分
解决方案:
至少要有半数以上的节点投票,才能成为master
而不能用最小投票人数为1
discovery.zen.minimum_master_nodes=(N/2)+1
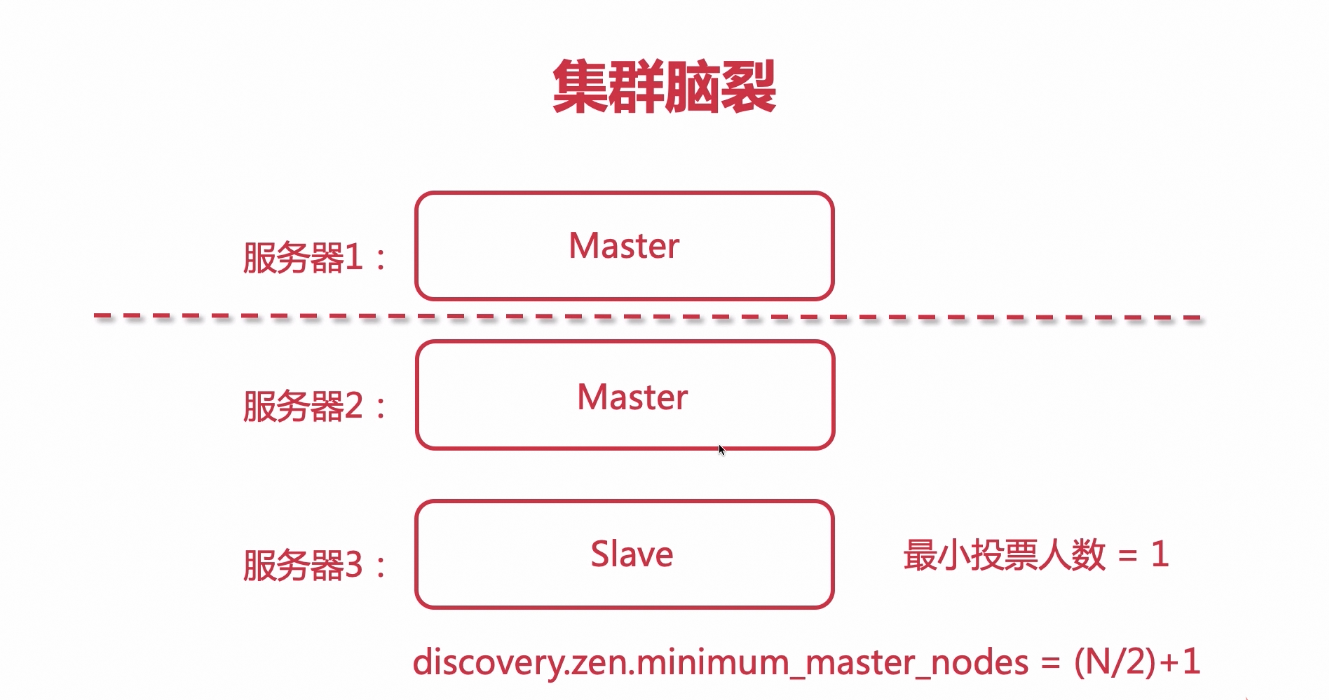
N代表 config中 node.master 被设置为 true 的数量
ES 7.x 没有脑裂的问题(已经不支持这个参数了,由es自己进行管理)
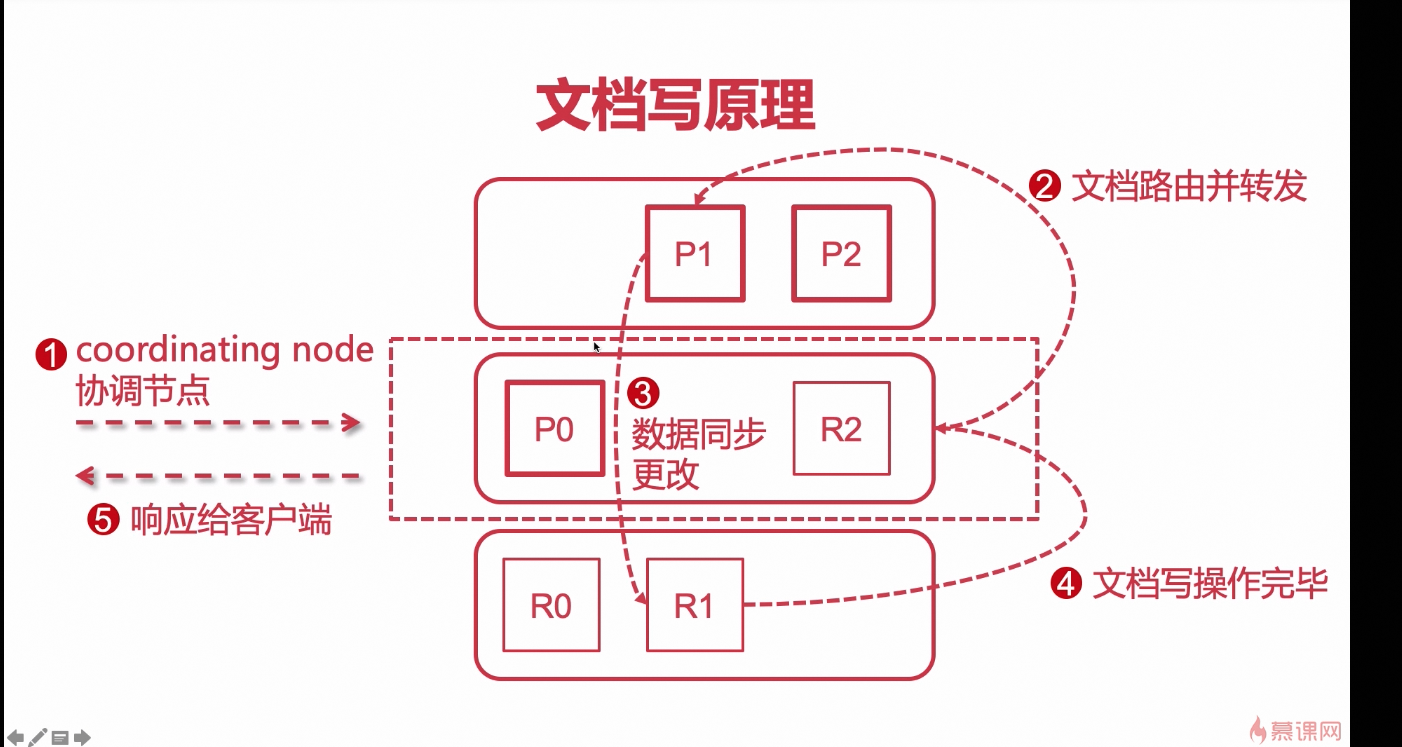
文档读写原理
文档写操作
- 用户访问服务器和es进行交互, 服务器都是指定一台 es节点服务器作为交互方;
- 当服务器访问的这台es服务器时,这台服务器就会被es认作为 es集群中的协调节点(负责接收 响应用户请求);
- 会做一个算法(hash算法),通过算法结果来决定 具体写到哪一个主分片;(路由转发)
- 文档存入主分片之后, 再将数据同步到副本分片上
- 当主分片和副本分片的文档数据都写入之后, 再由[协调节点]响应客户端结果
文档读操作
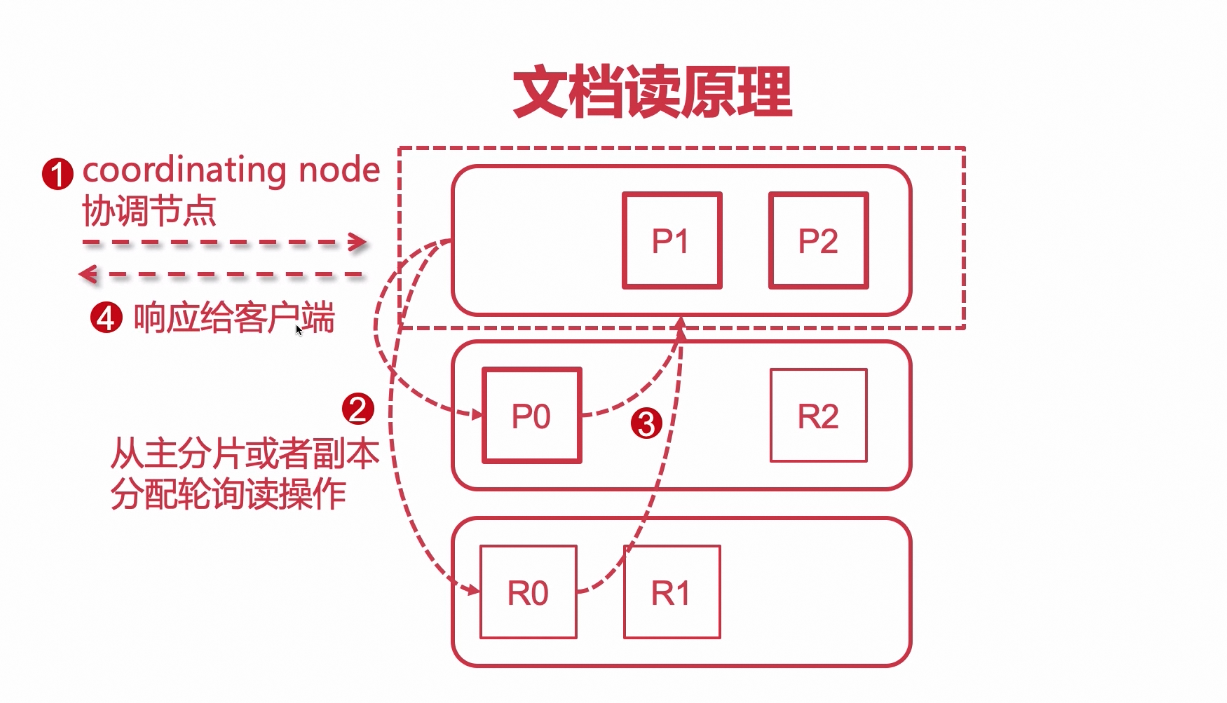
- 客户端请求 协调节点;
- 协调节点 针对 文档id 做 路由转发(采用的算法类似hash算法,计算出文档保存在哪个位置)
- 之后在 轮询的方式 转发到 存储该文档的 主节点或者备份节点(这么做可以分担请求压力提高效率)
- 之后数据返回给协调节点,由协调节点响应客户端
负载均衡,高负载
springboot整合es
queryForPage可以检索文档数据,以List形式返回
https://blog.csdn.net/weixin_51408465/article/details/131847032
https://blog.csdn.net/UbuntuTouch/article/details/120948876
logstash数据采集引擎
以id作为判断 来添加数据的话 有弊端,只能添加 DB中新增的数据,以前同步过了但是有更新的数据就不会被再同步了
所以会采用以update_time为判断 依据

logstash 用数据进行同步
1、数据采集(从数据库等任意数据源)
2、以id或update_time作为同步边界
3、logstash-input-jdbc插件
4、logstash要和es版本一致
5、索引要手动创建(如数据库表要先创建,再进行导入数据)

通过定时任务来进行扫描,同步。
https://class.imooc.com/lesson/1231#mid=29536
logstash配置mysql同步es
- 创建sync目录
- copy数据库驱动到sync目录
- sync目录创建logstash-db-sync.conf
input { jdbc { # 设置 MySql/MariaDB 数据库url以及数据库名称 jdbc_connection_string => "jdbc:mysql://192.168.1.6:3306/foodie-shop-dev?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true" # 用户名和密码 jdbc_user => "root" jdbc_password => "root" # 数据库驱动所在位置,可以是绝对路径或者相对路径 jdbc_driver_library => "/usr/local/logstash-6.4.3/sync/mysql-connector-java-5.1.41.jar" # 驱动类名 jdbc_driver_class => "com.mysql.jdbc.Driver" # 开启分页 jdbc_paging_enabled => "true" # 分页每页数量,可以自定义 jdbc_page_size => "10000" # 执行的sql文件路径 statement_filepath => "/usr/local/logstash-6.4.3/sync/foodie-items.sql" # 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务 schedule => "* * * * *" # 索引类型 type => "_doc" # 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件 use_column_value => true # 记录上一次追踪的结果值 last_run_metadata_path => "/usr/local/logstash-6.4.3/sync/track_time" # 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间 tracking_column => "updated_time" # tracking_column 对应字段的类型 tracking_column_type => "timestamp" # 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录 clean_run => false # 数据库字段名称大写转小写 lowercase_column_names => false } } output { elasticsearch { # es地址 hosts => ["192.168.1.187:9200"] # 同步的索引名 index => "foodie-items" # 设置_docID和数据相同 document_id => "%{id}" } # 日志输出 stdout { codec => json_lines }} - foodie-items.sql
:sql_last_value是一个变量,表示每次同步完的时间SELECT i.id as itemId, i.item_name as itemName, i.sell_counts as sellCounts, ii.url as imgUrl, tempSpec.price_discount as price, i.updated_time as updated_time FROM items i LEFT JOIN items_img ii on i.id = ii.item_id LEFT JOIN (SELECT item_id,MIN(price_discount) as price_discount from items_spec GROUP BY item_id) tempSpec on i.id = tempSpec.item_id WHERE ii.is_main = 1 and i.updated_time >= :sql_last_value - 启动logstash
./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf
https://class.imooc.com/lesson/1231#mid=29537
问题记录
记住同步数据的时候如果有多余的索引要删除
比如案例中只有 foodie-items这个索引就只保留这个索引就可以了
不要添加多余的索引
这是一个坑
logstash修改默认同步模板
使用http://url:9200/_template/logstash获取模板,在string_fields中添加"analyzer": "ik_max_word"来设置分词器


- 修改模板如下
{
//可以将自定义模板中的order增大(默认的logstash模板order为0)以提高优先级
"order": 0,
"version": 1,
"index_patterns": ["*"],
"settings": {
"index": {
"refresh_interval": "5s"
}
},
"mappings": {
"_default_": {
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false
}
}
},
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false,
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
],
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "keyword"
},
"geoip": {
"dynamic": true,
"properties": {
"ip": {
"type": "ip"
},
"location": {
"type": "geo_point"
},
"latitude": {
"type": "half_float"
},
"longitude": {
"type": "half_float"
}
}
}
}
}
},
"aliases": {}
}
- logstash配置做如下修改
# 定义模板名称
template_name => "myik"
# 模板所在位置
template => "/usr/local/logstash-6.4.3/sync/logstash-ik.json"
# 重写模板
template_overwrite => true
# 默认为true,false关闭logstash自动管理模板功能,如果自定义模板,则设置为false
manage_template => false
- 重新启动同步
./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf
https://class.imooc.com/lesson/1231#mid=29538
logstash如何同步删除
- 逻辑删除,通过标识和更新时间,更新es中数据标识为已删除
- 通过设置linux定时任务定时删除一定时间前的es数据(例如7天前)
curl -XDELETE "http://elasticseatch:9200/index"
脑图

复习
https://class.imooc.com/lesson/1231#mid=29539
备注
有兴趣可以去了解一下磁盘阵列或者NAS的raid0+1


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?