08-安装Spark
8、安装 Spark
我们这里就只配置 Yarn 模式的 Spark 集群,若需要 Standalone 模式 和 Local 模式,请参考角标文档
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其它框架提供资源。这种方式降低了和其它第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是要和其它专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的 Yarn 环境下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)
8.1 上传文件
将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 linux /opt/software/ 目录下
8.2 解压缩并改名
[bigdata@bigdata101 software]$ tar zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[bigdata@bigdata101 module]$ mv spark-3.0.0-bin-hadoop3.2/ spark-yarn
8.3 配置环境变量
[bigdata@bigdata101 spark-yarn]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容:
# Spark_HOME
export SPARK_HOME=/opt/module/spark-yarn
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
8.4 修改 spark-env.sh 配置文件
[bigdata@bigdata101 spark-yarn]$ mv conf/spark-env.sh.template conf/spark-env.sh
在里面添加如下内容:
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop
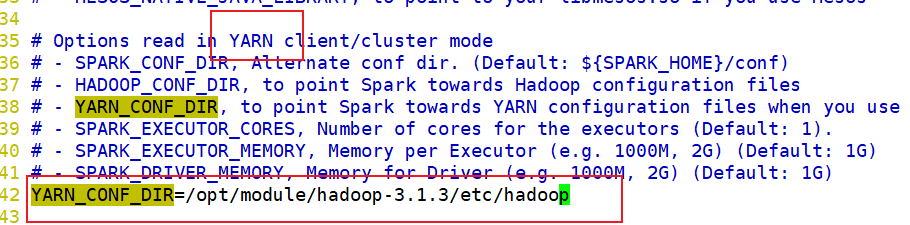
不需要添加 jdk 的配置,因为统一在 my_env.sh 中配置了
- 注意:一定要 source /etc/profile.d/my_env.sh,我就是忘记了这一步,找了好久的原因😂🤣😜
8.5 分发 Spark
[bigdata@bigdata101 module]$ xsync spark-yarn/
8.6 启动测试
确保 hadoop,zookeeper 都已正常启动了
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.12-3.0.0.jar 10
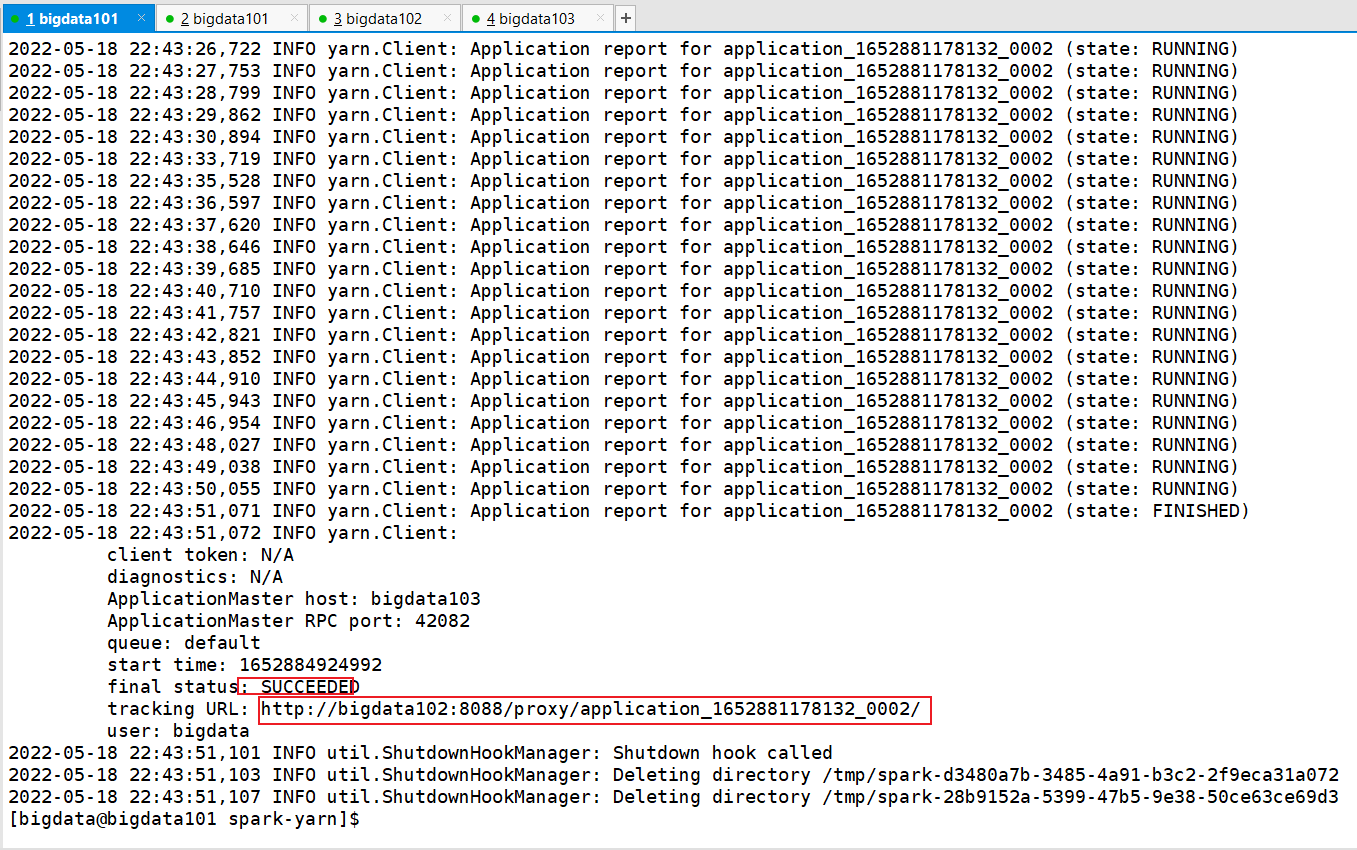
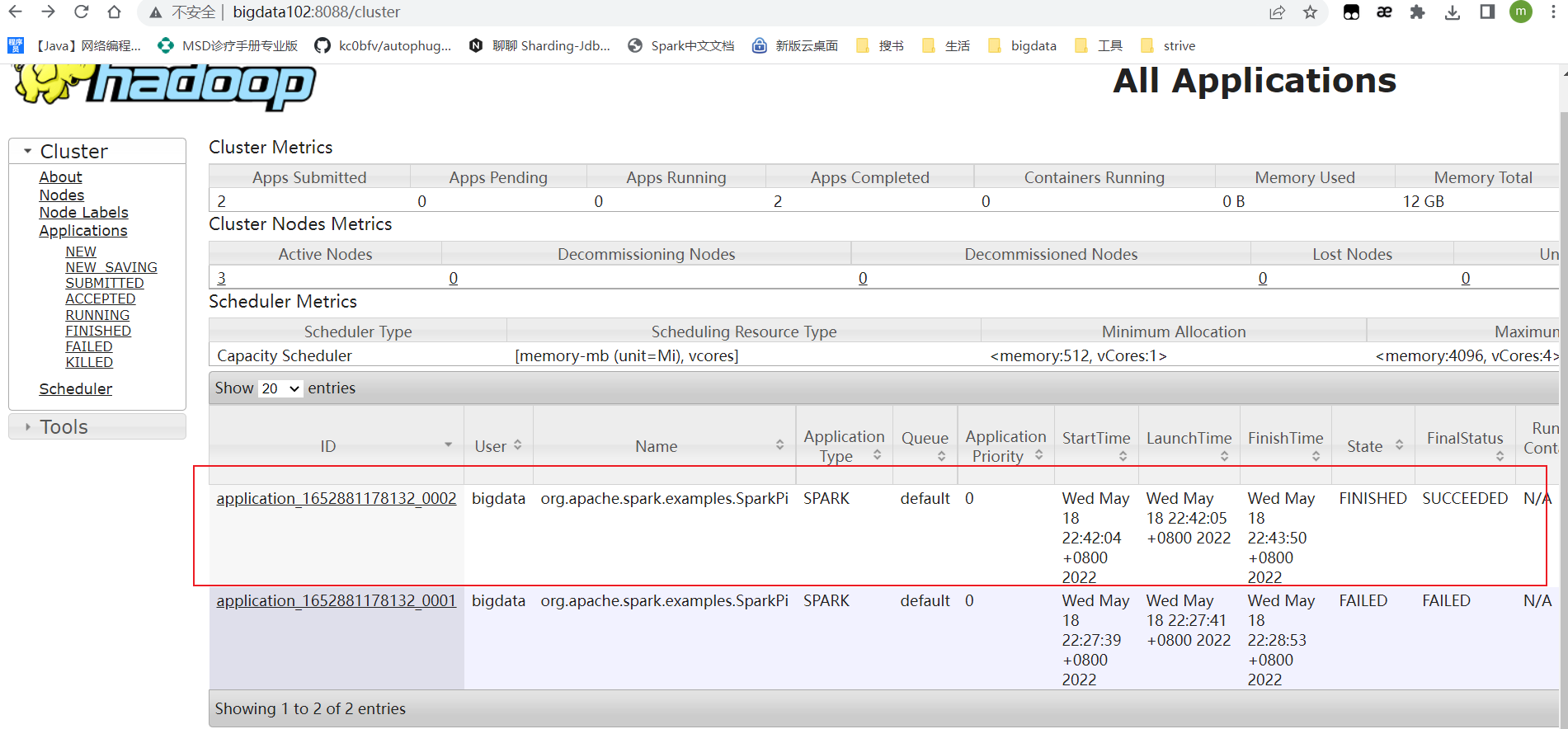
若你的结果也是和我的一样,恭喜你,说明配置成功了。
8.7 配置历史服务器
8.7.1 修改 spark-defaults.conf.template 文件名
# 修改 spark-defaults.conf.template 文件名
[bigdata@bigdata101 spark-yarn]$ mv conf/spark-defaults.conf.template conf/spark-defaults.conf
8.7.2 修改 spark-defaults.conf 文件
修改 spark-defaults.conf 文件,配置日志存储路径
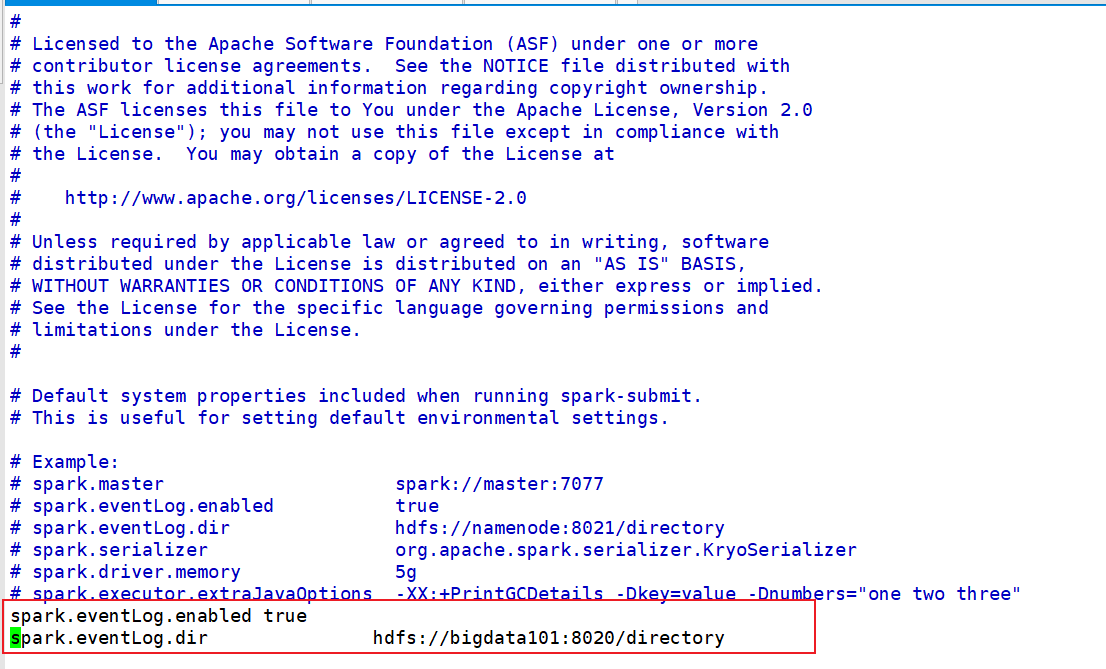
注意:根据你的需要修改以上内容
注意:需要启动 hadoop 集群(我这里使用了myhadoop.sh 一键启动脚本),HDFS 上的目录需要提前存在。(不存在的话还等什么,赶紧去创建啊)
[bigdata@bigdata101 spark-yarn]$ hdfs dfs -mkdir /directory
8.7.3 修改 spark-env.sh 文件,添加日志配置
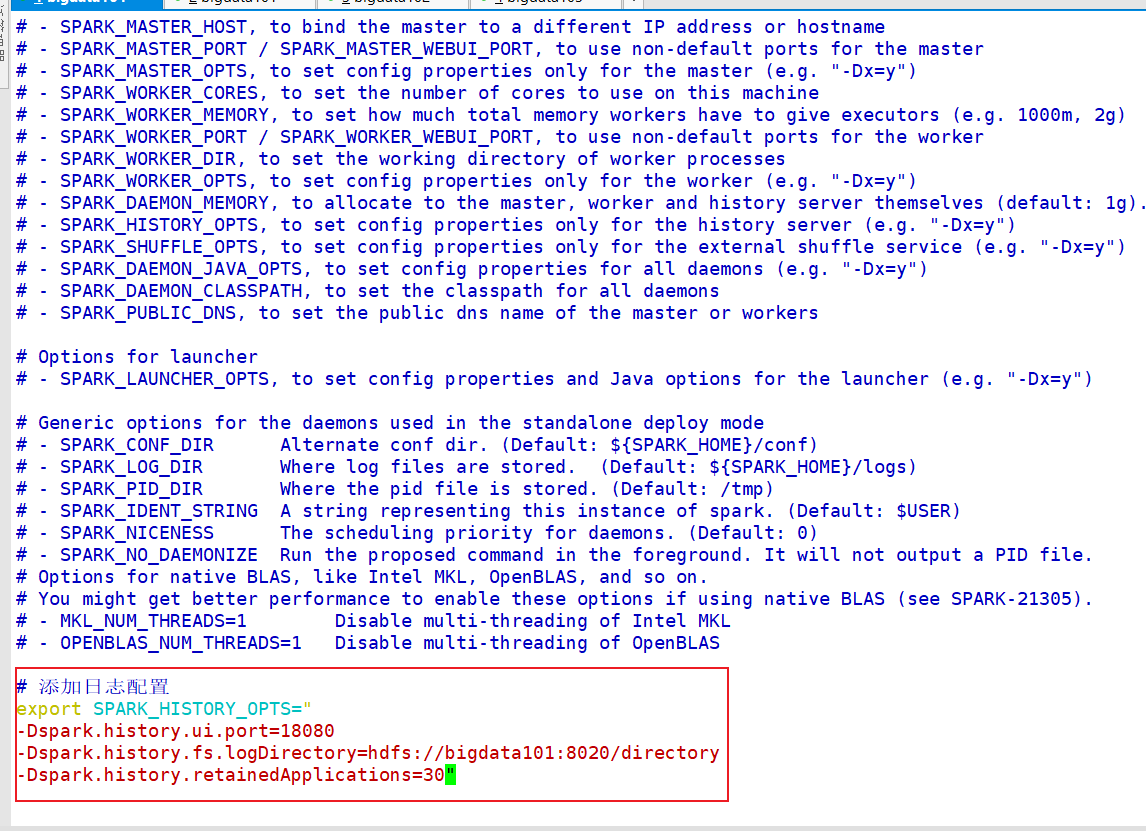
添加如下内容:
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://bigdata101:8020/directory
-Dspark.history.retainedApplications=30"
- 参数1含义:WEB UI 访问的端口号为 18080
- 参数2含义:指定历史服务器日志存储路径
- 参数3含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数
8.7.4 修改 spark-defaults.conf 文件
添加如下内容:
spark.yarn.historyServer.address=bigdata101:18080
spark.history.ui.port=18080
8.7.5 启动历史服务
[bigdata@bigdata101 spark-yarn]$ sbin/start-history-server.sh
重新提交应用:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
如果不成功,则删除掉 集群上 hadoop/data hadoop/logs,然后重新格式化,再启动就可以了,然后再按照上面配置即可。
更多内容请参考:01_尚硅谷大数据技术之SparkCore.pdf 备用链接
本文来自博客园,作者:LoremMoon,转载请注明原文链接:https://www.cnblogs.com/hello-cnblogs/p/16286857.html
