07-安装Kafka
7、安装 Kafka
7.1 集群规划
| bigdata101 | bigdata102 | bigdata103 |
|---|---|---|
| zk | zk | zk |
| kafka | kafka | kafka |
7.2 安装
jar 包下载:http://kafka.apache.org/downloads kafka_2.11-2.4.1.tgz
7.2.1 解压
[bigdata@bigdata101 software]$ tar zxvf kafka_2.11-2.4.1.tgz -C /opt/module/
7.2.2 修改解压后的文件名称
[bigdata@bigdata101 module]$ mv kafka_2.11-2.4.1/ kafka
7.2.3 在 /opt/module/kafka 目录下创建 logs 文件夹
[bigdata@bigdata101 kafka]$ mkdir logs
7.2.4 修改 server.properties 配置文件
[bigdata@bigdata101 kafka]$ vim config/server.properties
修改或添加如下内容:
# broker的全局唯一编号,不能重复
broker.id=1
# kafka运行日志存放的路径
log.dirs=/opt/module/kafka/data
# 配置连接Zookeeper集群地址
zookeeper.connect=bigdata101:2181,bigdata102:2181,bigdata103:2181/kafka
7.2.5 配置环境变量
[bigdata@bigdata101 kafka]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容:
# KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile.d/my_env.sh
7.2.6 分发 kafka
[bigdata@bigdata101 module]$ xsync kafka/
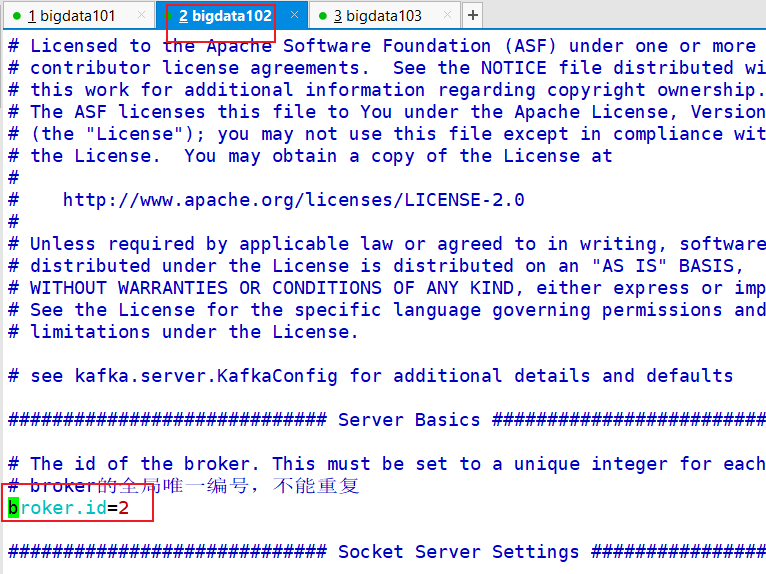
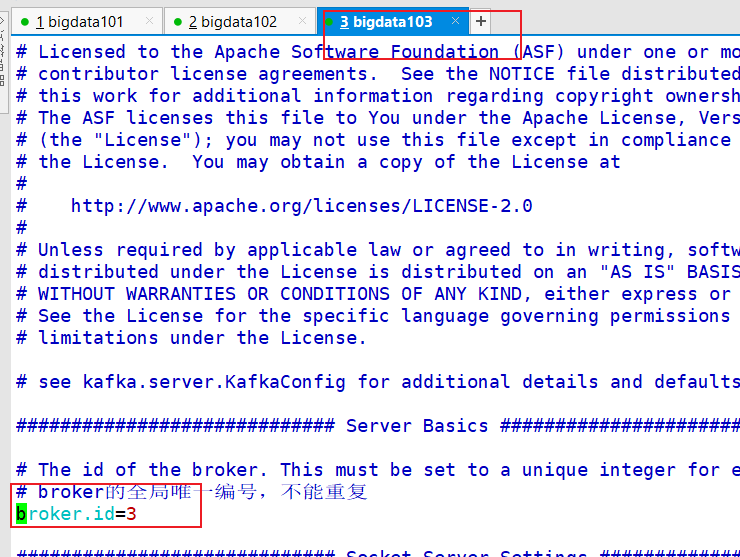
7.2.7 分别在 bigdata102 和 bigdata103 上修改配置文件
/opt/module/kafka/config/server.properties 中的 broker.id=1、broker.id=2
注:broker.id 不得重复
[bigdata@bigdata102 kafka]$ vim config/server.properties
[bigdata@bigdata103 kafka]$ vim config/server.properties
7.3 编写 kafka 群起脚本
[bigdata@bigdata101 bin]$ vim kf.sh
#!/bin/bash
<<EOF
该脚本是 kafka 集群的启动停止脚本
EOF
case $1 in
"start") {
for i in bigdata101 bigdata102 bigdata103; do
echo -e "\033[32m --------启动 $i Kafka------- \033[0m"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties "
done
} ;;
"stop") {
for i in bigdata101 bigdata102 bigdata103; do
echo -e "\033[31m --------停止 $i Kafka------- \033[0m"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop"
done
} ;;
esac
- 增加脚本执行权限: chmod +x kf.sh
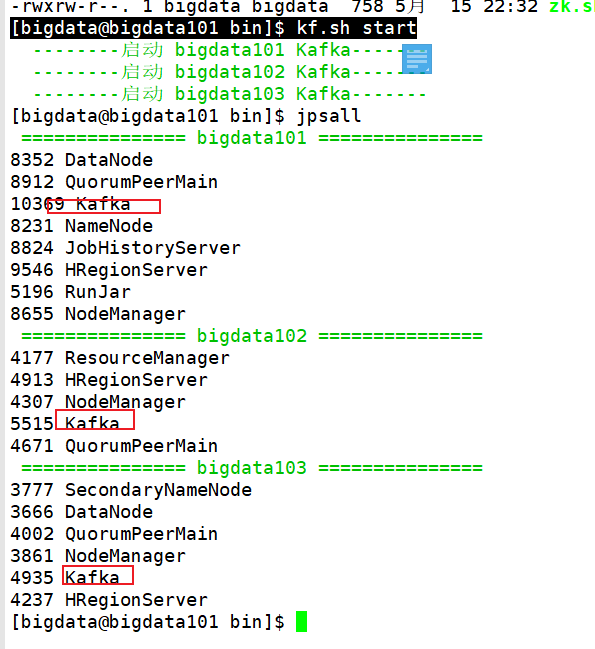
7.4 启动/停止测试
# 停止就是 kf.sh stop
[bigdata@bigdata101 bin]$ kf.sh start
7.5 Kafka 创建 topic
[bigdata@bigdata101 kafka]$ bin/kafka-topics.sh --bootstrap-server bigdata101:9092 --create --topic maxwell --partitions 3
查看刚才创建的 topic:
bin/kafka-topics.sh --bootstrap-server bigdata101:9092 --list
7.6 Kafka 监控
kafka 监控这里配置的jdbc是mysql,因此你必须得先安装好 mysql 才可以(当然你如果你配置了 oracle 等也是可以的),配置监控时先不要启动 kafka。
7.6.1 修改 kafka 启动命令
# 进入 /opt/module/kafka/bin 目录
[bigdata@bigdata101 bin]$ vim kafka-server-start.sh
修改 kafka-server-start.sh 命令中
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
注意:修改之后在启动 Kafka 之前要将 kafka-server-start.sh 文件分发至其它节点。
7.6.2 上传 kafka-eagle-bin-1.3.7.tar.gz 到 bigdata101 /opt/software目录
- 解压到本地
[bigdata@bigdata101 software]$ tar -zxvf kafka-eagle-bin-1.3.7.tar.gz
- 进入刚才解压的目录,可以看到还有一个 kafka-eagle-web-1.3.7-bin.tar.gz 压缩包
- 将kafka-eagle-web-1.3.7-bin.tar.gz解压至/opt/module
[bigdata@bigdata101 kafka-eagle-bin-1.3.7]$ tar zxvf kafka-eagle-web-1.3.7-bin.tar.gz -C /opt/module/
- 修改名称
[bigdata@bigdata101 module]$ mv kafka-eagle-web-1.3.7/ eagle
- 给启动文件配置执行权限
[bigdata@bigdata101 bin]$ chmod +x ke.sh
- 修改配置文件
[bigdata@bigdata101 conf]$ vim system-config.properties
将对应的内容修改为如下内容:
######################################
# multi zookeeper&kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=bigdata101:2181,bigdata102:2181,bigdata103:2181
######################################
# kafka offset storage
######################################
cluster1.kafka.eagle.offset.storage=kafka
######################################
# enable kafka metrics
######################################
kafka.eagle.metrics.charts=true
kafka.eagle.sql.fix.error=false
######################################
# kafka jdbc driver address
######################################
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://bigdata101:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=123456
这里只配置了 cluster1,将 cluster2 注释掉了...
- 配置 eagle 的环境变量
# Kafka 监控
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin
注意:source /etc/profile.d/my_env.sh
- 先启动 kf.sh start,再进入 /opt/module/eagle/ 启动
bin/ke.sh start监控
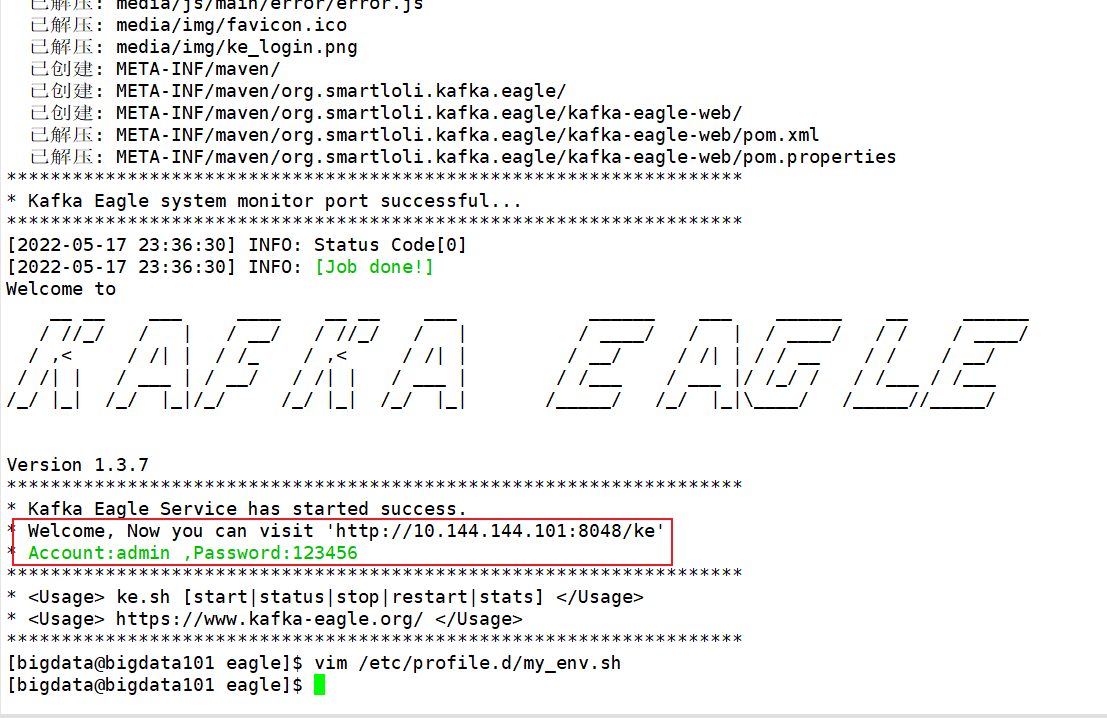
之后访问给出的地址,输入对应的账号密码,查看信息:
更多内容参考:《尚硅谷大数据技术之Kafka.docx》 备用链接
本文来自博客园,作者:LoremMoon,转载请注明原文链接:https://www.cnblogs.com/hello-cnblogs/p/16275378.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号