04-安装Hive
4、安装 Hive
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 的查询功能。
本质是: 将 HQL 转化为 MapReduce 程序。
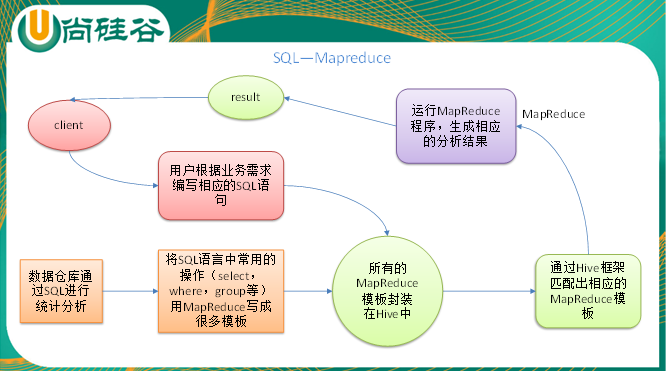
- Hive 处理的数据存储在 HDFS
- Hive 分析数据底层的实现是 MapReduce
- 执行程序运行在 Yarn 上
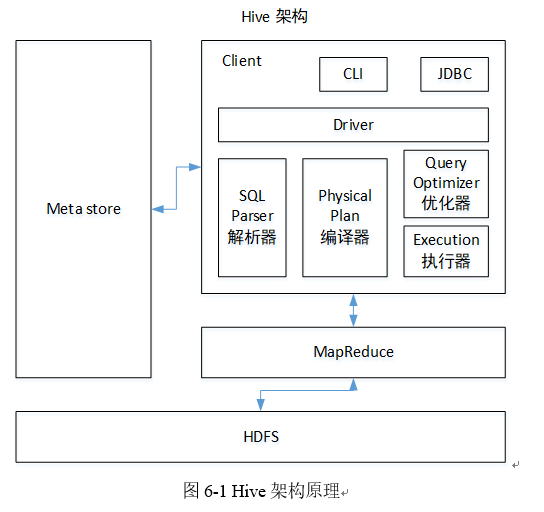
4.1 Hive 架构原理
4.2 Hive 安装
Hive 官网地址:http://hive.apache.org/
文档查看地址:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
4.2.1 上传 Jar 包到 目标目录
登录 bigdata101 主机,进入目录 /opt/software/ 目录下:
上传 apache-hive-3.1.2-bin.tar 包 相应目录下:
4.2.2 解压
tar zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/
解压后,修改一下名字: mv apache-hive-3.1.2-bin/ hive
4.3 Hive 配置
进入 /opt/module/hive 目录:
修改 /opt/module/hive/conf 目录下的 hive-env.sh.template 名称为 hive-env.sh
mv conf/hive-env.sh.template conf/hive-env.sh
4.3.1 配置环境变量
# HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile.d/my_env.sh 生效
4.3.2 解决日志 Jar 包冲突,进入 /opt/module/hive/lib 目录
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
4.3.3 Hive 元数据配置到 MySQL
4.3.3.1 拷贝驱动
将 MySQL 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
# 进入lib目录
cd /opt/module/hive/lib/
# 拷贝mysql驱动到hive的lib下
cp /opt/module/mysql/mysql-connector-java-5.1.27.jar /opt/module/hive/lib/
4.3.3.2 配置 MySQL 作为元数据存储
在 $HIVE_HOME/conf 目录下新建 hive-site.xml 文件
cd $HIVE_HOME/conf
touch hive-site.xml
vim hive-site.xml
编辑 hive-site.xml 文件,添加如下内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata101:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>bigdata101</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
4.4 启动 Hive
4.4.1 初始化元数据库
- 登录 mysql
mysql -uroot -p123456
- 新建 hive 元数据库
mysql> create database metastore;
mysql> quit;
- 初始化 Hive 元数据库
# 就在 /opt/module/hive/conf 目录执行即可
schematool -initSchema -dbType mysql -verbose
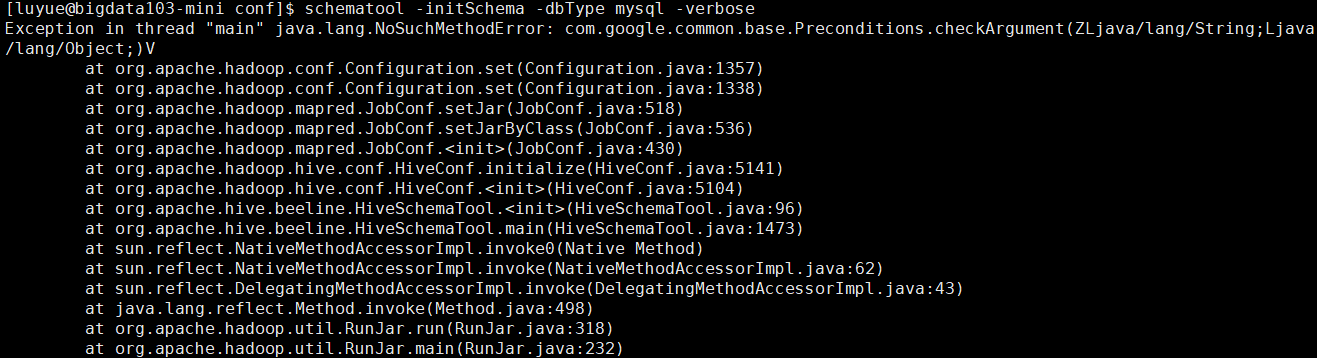
如果报如下错误:
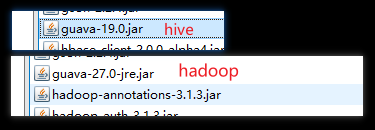
则说明是因为/opt/module/hadoop-3.1.3/share/hadoop/common/lib和/opt/module/hive/lib中的 guava.jar 包的依赖版本不一致造成的,如下所示:
解决方案:删除hive中低版本的guava-19.0.jar包,将hadoop中的guava-27.0-jre.jar复制到hive的lib目录下即可。cp /opt/module/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar /opt/module/hive/lib/
4.4.2 启动 hive 客户端
[bigdata@bigdata101 hive]$ nohup hive --service metastore &
[bigdata@bigdata101 hive]$ bin/hive
4.4.3 修改元数据库字符集
Hive元数据库的字符集默认为Latin1,由于其不支持中文字符,故若建表语句中包含中文注释,会出现乱码现象。如需解决乱码问题,须做以下修改。
- 修改 Hive 元数据库中存储 字段注释 的字段的字符集为 uft-8
# 登录 mysql
mysql -uroot -p123456
# 切换 metastore 库
use metastore;
# 修改 字段注释 字段的字符集
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
- 修改 Hive 元数据库中存储 表注释的 字段的字符集为 utf-8
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
4.5 实操
4.5.1 将本地文件导入 Hive 案例
需求:将本地 /opt/module/datas/student.txt 这个目录下的数据导入到 hive 的 student(id int, name string)表中。
# 切换目录
cd /opt/module/
# 创建目录
mkdir datas
# 创建文件
cd datas; vim student.txt
写入如下内容:
1001 zhangshan
1002 lishi
1003 zhaoliu
登录 hive ,创建 student 表
# 就使用默认的 default 库即可,删除表使用 drop table student;
hive (default)> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
加载 /opt/module/datas/student.txt 文件到 student 数据库表中:
hive (default)> load data local inpath '/opt/module/datas/student.txt' into table student;
hive 查询 student 表可以正常查询。
4.6 HiveJDBC 访问
4.6.1 启动 hiveserver2 服务
# 进入 hive 目录
cd /opt/module/hive/
# 以后台服务的方式启动 hiveserver2,注意这里一定要切换成root用户再执行如下一条命令,当执行完后,再切换回 bigdata 用户即可
# nohup bin/hiveserver2 & # 不推荐这种方式
# 推荐如下方式启动 hiveserver2 服务,进入 /home/luyue 用户目录
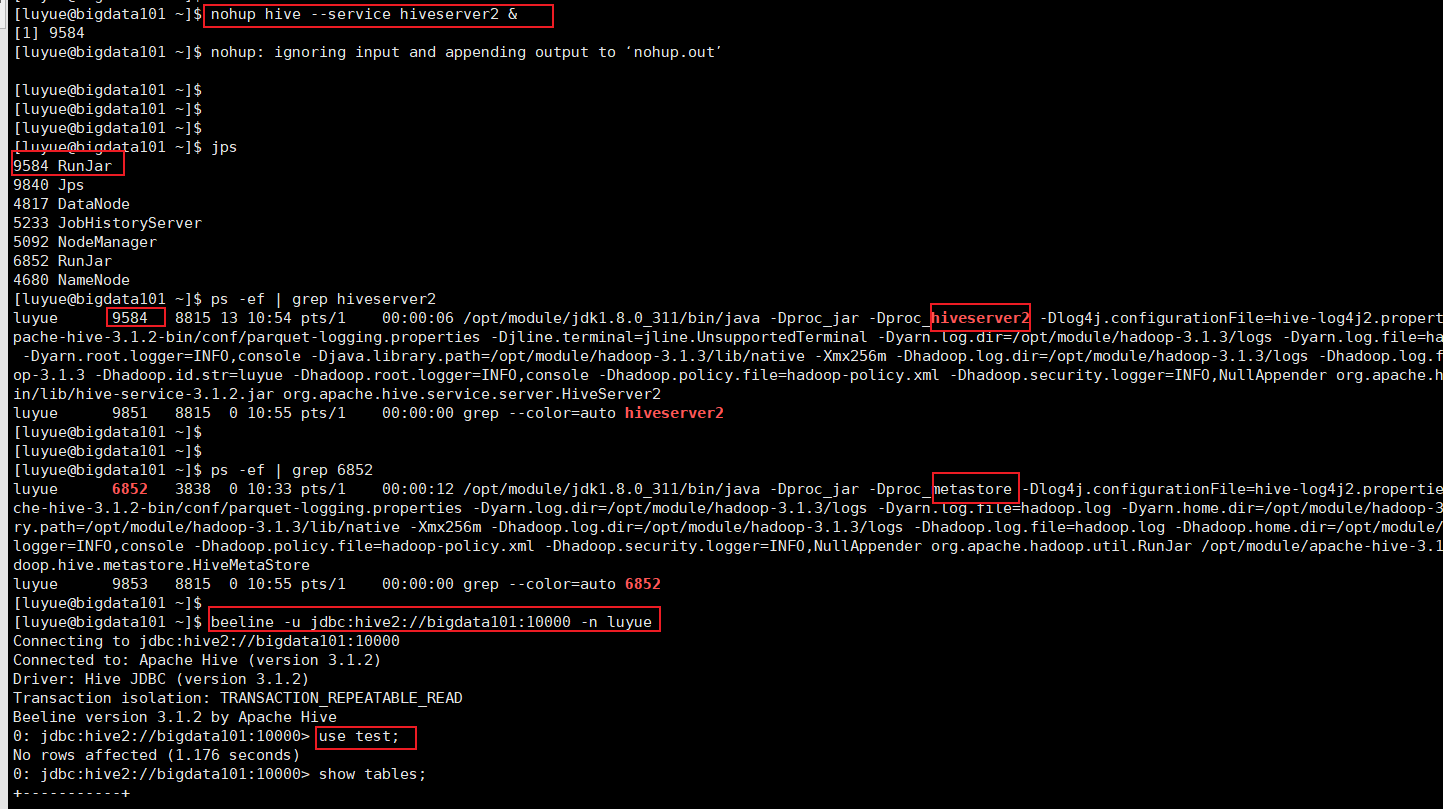
nohup hive --service hiveserver2 &
4.6.2 启动 beeline,并连接 hiveserver2
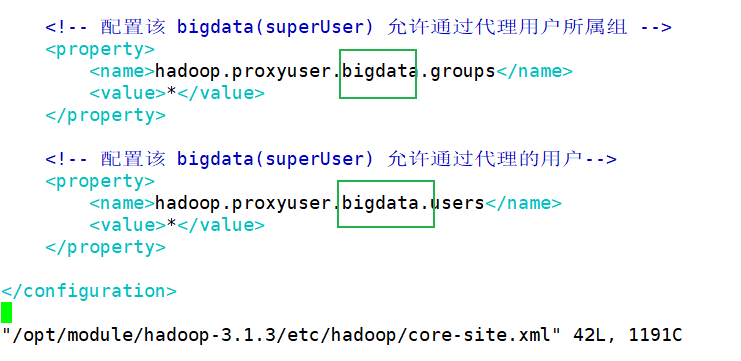
bin/beeline -u jdbc:hive2://bigdata101:10000 -n bigdata
这里使用的 bigdata 用户,是因为其配置在 $HADOOP_HOME/etc/hadoop/core-site.xml
4.6.3 使用dbeaver通过jdbc连接hive
驱动
进入 cd /opt/module/apache-hive-3.1.2-bin/jdbc/ 目录,将这个jar包下载下来,配置在dbeaver的驱动中,账号密码同 beeline -u jdbc:hive2://bigdata101:10000 -n bigdata 中的用户和密码
其他内容请参考文档:《尚硅谷大数据技术之Hive.doc》 备用链接
本文来自博客园,作者:LoremMoon,转载请注明原文链接:https://www.cnblogs.com/hello-cnblogs/p/16274948.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号