

【Kaggle】学生表现预测大赛--Day2
记录学习中的一些技术点,零散记录
Python中Pandas.CSV()函数的作用。
pandas是一个Python包,并且它提供快速,灵活和富有表现力的数据结构。这样当我们处理"关系"或"标记"的数据(一维和二维数据结构)时既容易又直观。
pandas是我们运用Python进行实际、真实数据分析的基础,同时它是建立在NumPy之上的。
pandas.csv() 函数将逗号分离的值 (csv) 文件读入数据框架。还支持可选地将文件读入块或将其分解。
数据集表,通过:
train = pd.read_csv('/kaggle/input/predict-student-performance-from-game-play/train.csv')
train.head() # head()函数读取前5行,若想读取多行则train.head(10)
print( train.shape ) //打印出表格
targets['session'] = targets.session_id.apply(lambda x: int(x.split('_')[0]) )
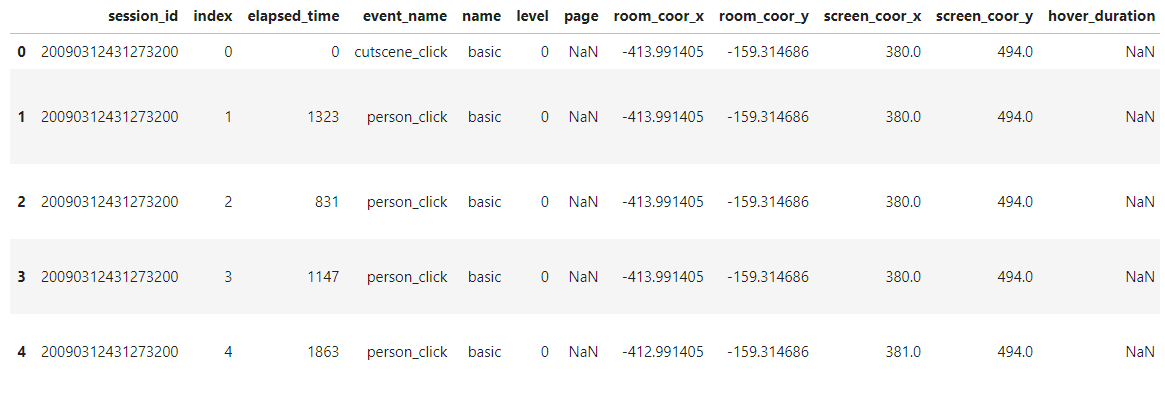
# Pandas.apply()函数
dataframe.apply(function,axis)对一行或一列做出一些操作(axis=1遍历行,axis=0遍历列)
遍历DataFrame元素(一行或者一列数据):
行遍历:
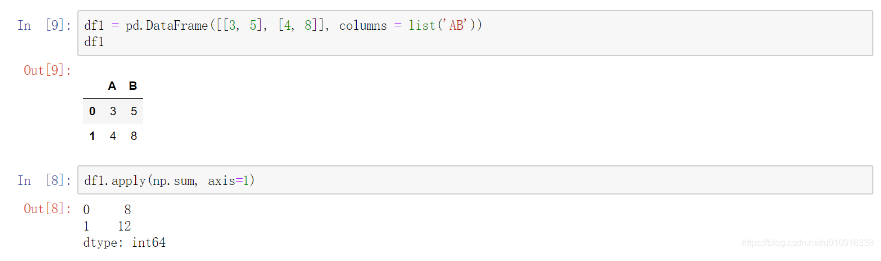
lambda函数作用:
函数式编程,使得apply()处理数据时,参数可以传函数。
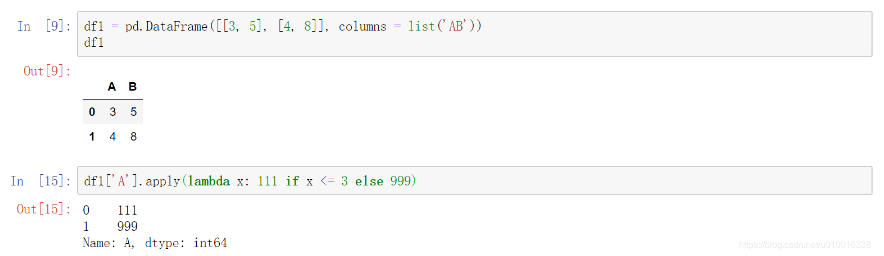
Python中默认的函数也可以用lambda函数传递,可以快速取出列表中每一列(行)中做大或者最小的数
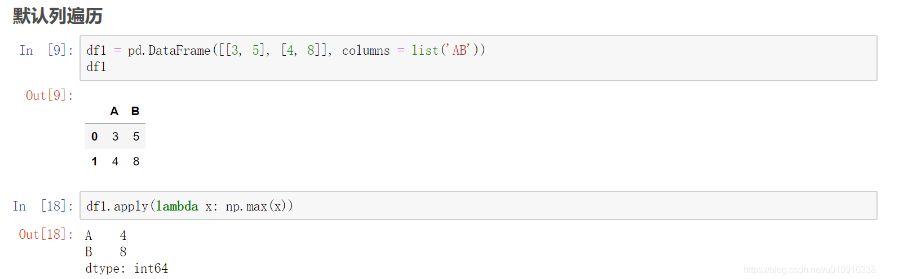
targets['session'] = targets.session_id.apply(lambda x: int(x.split('_')[0]) ) //Python split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
targets['q'] = targets.session_id.apply(lambda x: int(x.split('_')[-1][1:]) )
Pandas.group()分组原理

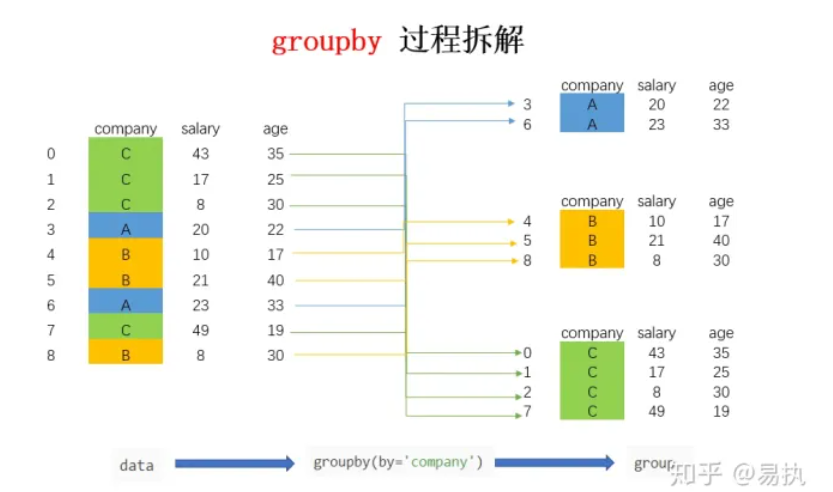
总结来说,groupby的过程就是将原有的DataFrame按照groupby的字段(这里是company),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。理解了这点,也就基本摸清了Pandas中groupby操作的主要原理。下面来讲讲groupby之后的常见操作。
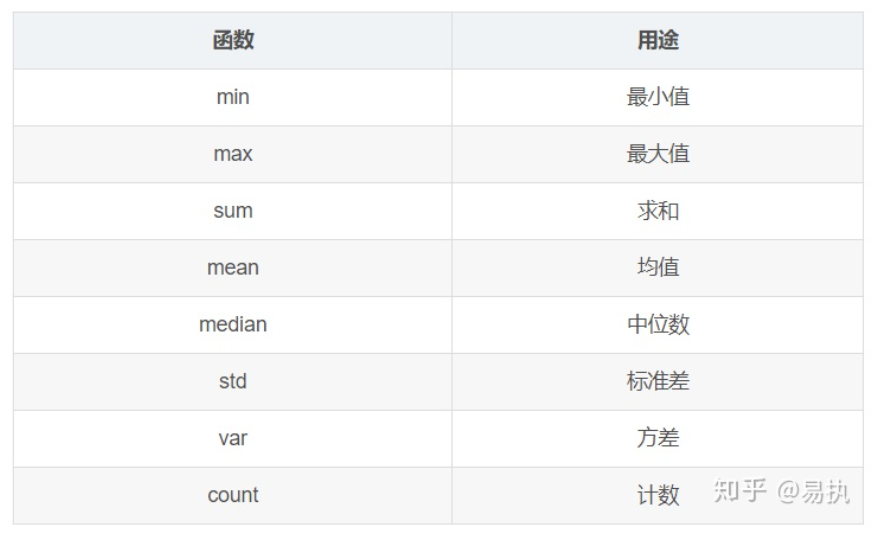
Pandas.age()聚合操作:
聚合操作可以用来求和、均值、最大值、最小值等,下面的表格列出了Pandas中常见的聚合操作。
print( targets.shape )
-----
def feature_engineer(train):
dfs = []
for c in CATS:
tmp = train.groupby(['session_id','level_group'])[c].agg('nunique')
tmp.name = tmp.name + '_nunique'
dfs.append(tmp)
for c in NUMS:
tmp = train.groupby(['session_id','level_group'])[c].agg('mean')
tmp.name = tmp.name + '_mean'
dfs.append(tmp)
for c in NUMS:
tmp = train.groupby(['session_id','level_group'])[c].agg('std')
tmp.name = tmp.name + '_std'
dfs.append(tmp)
for c in EVENTS:
train[c] = (train.event_name == c).astype('int8')
for c in EVENTS + ['elapsed_time']:
tmp = train.groupby(['session_id','level_group'])[c].agg('sum')
tmp.name = tmp.name + '_sum'
dfs.append(tmp)
train = train.drop(EVENTS,axis=1)
df = pd.concat(dfs,axis=1)
df = df.fillna(-1)
df = df.reset_index()
df = df.set_index('session_id')
return df
Pandas.drop()函数:删除某一行,删除列要加axis=?。
Traning :
sklearn交叉验证(KFold)的几个变种:
如果能熟练使用kfold的几个变种用来切分训练集和测试集,在很多比赛中会有惊人的上分效果。
基于kfold主要有三个交叉验证的方法:
1. KFold
2. StratifiedKFold
3. GroupKFold
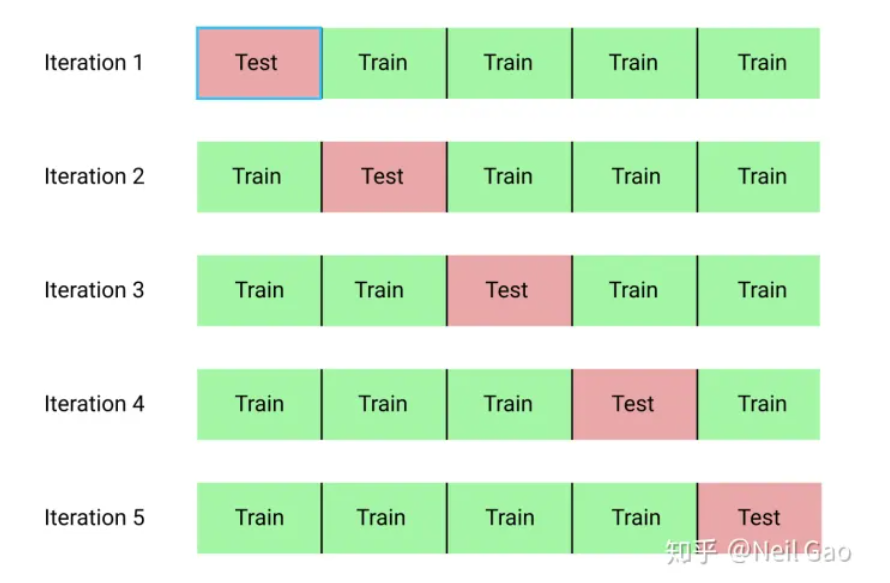
KFold的目的就是通过多次切分,同一个模型可以训练多次,可以有效地防止单次的切分可能导致的训练集和测试集分布差异过大,
5折KFold本质上就是把数据集平均切成5份,然后每次选取其中1份作为测试集,剩下的4份作为训练集来构造模型,重复切5次,每次选取的1/5测试集都不一样,如上图所示,最后同一个模型在5次切分上各训练一次,预测结果也会取5次的平均值,可以有效地提高模型的鲁棒性,防止模型在过拟合到某一次的切分的训练集的数据上。
一般我们会设置KFold的参数random_state为某一个整数,这样可以保证代码可以复现,否则每次运行上面的代码,切分出来的结果都是不一样的。
注意到KFold是均匀切分数据集的,而通常的数据集里,预测目标的分布可能是不平均的,甚至是非常倾斜的,比如在反欺诈的数据中,正样本的数量会比负样本多一个量级,当然我们可以对正样本做部分采样,也可以对负样本做数据增强,但是这样会损失掉一些样本,
而StratifiedKFold就是为了解决正负样本分布不均的切分问题的(多标签样本同样适用),
StraitifiedKFold(分层)会根据预测目标里各个样本的分布比例来切分样本,使得切分后的训练集和测试集里的各个样本的比例都尽可能和全样本相同。
事实上,我们有时候可能不希望某一组或某一类型的样本被切分到训练集和测试集中,而是希望这组数据全部都在训练集中或者全部在测试集中,比如医疗影像数据,我们希望某个病人的完整数据要么全在训练集中,要么全部在测试集中,而GroupKFold就可以实现我们的目标:
