总结linux安全模型

|
设置文件的所有者chown
|
修改文件的属主,也可以修改文件属组
|
chown [OPTION]... [OWNER][:[GROUP]] FILE...
chown [OPTION]... --reference=RFILE FILE...
|
OWNER
#只修改所有者
OWNER:GROUP #同时修改所有者和属组
:GROUP
#只修改属组,冒号也可用 . 替换
--reference=RFILE
#参考指定的的属性,来修改
-R #递归,此选项慎用,非常危险!
|
|
设置文件的属组信息chgrp
|
只修改文件的属组
|
chgrp [OPTION]... GROUP FILE...
chgrp [OPTION]... --reference=RFILE FILE...
|
-R 递归
|
|
文件的权限主要针对三类对象进行定义
|
owner 属主, u
group 属组, g
other 其他, o
|
用户的最终权限,是从左向右进行顺序匹配,即,所有者,所属组,其他人,一旦匹配权限立即生效,不再向
右查看其权限
r和w权限对root 用户无效
只要所有者,所属组或other三者之一有x权限,root就可以执行
|
|
|
三种权限
|
r Readable 4
w Writable 2
x eXcutable 1
|
针对文件:
r 可使用文件查看类工具,比如:cat,可以获取其内容
w 可修改其内容,文件的是否被删除和文件的权限无关
x 可以把此文件提请内核启动为一个进程,即可以执行(运行)此文件(此文件的内容必须是可执行)
文件权限常见组合
--- 0
r 4
r-x 5
rw 6
rwx 7
|
针对目录:
r 可以使用ls查看此目录中文件名列表,但无法看到文件的属性meta信息,包括inode号,不能查看文件的内容
w 可在此目录中创建文件,也可删除此目录中的文件,而和此被删除的文件的权限无关
x 可以cd进入此目录,可以使用ls -l file或stat file 查看此目录中指定文件的元数据,当预先知道文件名称时,也可以查看文件的内容,属于目录的可访问的最小权限
X 分配给目录或有部分x权限的文件的x权限,对无任意x权限的文件则不会分配x权限
目录权限常见组合
- 不能访问目录
r-x 只读目录
rwx 可读也可写目录
|
|
数学法的权限
|
 |
||
|
八进制数字
|
--- 000 0
--x 001 1
-w- 010 2
-wx 011 3
r-- 100 4
r-x 101 5
rw- 110 6
rwx 111 7
|
例如:
rw-r----- 640
rwxr-xr-x 755
|
|
|
修改文件权限chmod
|
chmod [OPTION]... MODE[,MODE]... FILE...
chmod [OPTION]... OCTAL-MODE FILE...
#参考RFILE文件的权限,将FILE的修改为同RFILE
chmod [OPTION]... --reference=RFILE FILE...
|
MODE:who opt permission
who:u,g,o,a
opt:+,-,=
permission:r,w,x
修改指定一类用户的所有权限
u=
g= o= ug=
a= u=,g=
修改指定一类用户某个或某个权限
u+ u- g+ g- o+ o- a+ a- + -
-R: 递归修改权限
|
|
|
新建文件和目录的默认权限
|
umask 的值可以用来保留在创建文件权限
|
实现方式:
新建文件的默认权限: 666-umask,如果所得结果某位存在执行(奇数)权限,则将其权限+1,偶数不变
新建目录的默认权限: 777-umask
非特权用户umask默认是 002
root的umask 默认是 022
|
查看umask
umask
#模式方式显示
umask –S
#输出可被调用
umask –p
修改umask
umask #
范例:
持久保存umask
umask 002
umask u=rw,g=r,o=
全局设置: /etc/bashrc
用户设置:~/.bashrc
|
|
Linux文件系统上的特殊权限
|
|||
|
SUID
|
作用于二进制可执行文件上,用户将继承此程序所有者的权限
|
前提:进程有属主和属组;文件有属主和属组
任何一个可执行程序文件能不能启动为进程,取决发起者对程序文件是否拥有执行权限
启动为进程之后,其进程的属主为发起者,进程的属组为发起者所属的组
进程访问文件时的权限,取决于进程的发起者
二进制的可执行文件上SUID权限功能:
任何一个可执行程序文件能不能启动为进程:取决发起者对程序文件是否拥有执行权限
启动为进程之后,其进程的属主为原程序文件的属主
SUID只对二进制可执行程序有效
SUID设置在目录上无意义
|
chmod u+s FILE...
chmod 4xxx FILE
chmod u-s FILE...
|
|
SGID
|
作用于二进制可执行文件上,用户将继承此程序所有组的权限
作于于目录上, 此目录中新建的文件的所属组将自动从此目录继承
|
二进制的可执行文件上SGID权限功能:
任何一个可执行程序文件能不能启动为进程:取决发起者对程序文件是否拥有执行权限
启动为进程之后,其进程的属组为原程序文件的属组
chmod g+s FILE...
chmod 2xxx FILE
chmod g-s FILE...
|
目录上的SGID权限功能:
默认情况下,用户创建文件时,其属组为此用户所属的主组,一旦某目录被设定了SGID,则对此目录有
写权限的用户在此目录中创建的文件所属的组为此目录的属组,通常用于创建一个协作目录
chmod g+s DIR...
chmod 2xxx DIR
chmod g-s DIR...
|
|
STICKY
|
作用于目录上,此目录中的文件只能由所有者自已来删除
|
具有写权限的目录通常用户可以删除该目录中的任何文件,无论该文件的权限或拥有权
在目录设置Sticky 位,只有文件的所有者或root可以删除该文件
sticky 设置在文件上无意义
|
chmod o+t DIR...
chmod 1xxx DIR
chmod o-t DIR...
|
|
特殊权限数字法
|
SUID SGID STICKY
000 0
001 1
010 2
011 3
100 4
101 5
110 6
111 7
例如:chmod 4777 /tmp/a.txt
|
权限位映射
|
SUID: user,占据属主的执行权限位
s:属主拥有x权限
S:属主没有x权限
SGID: group,占据属组的执行权限位
s: group拥有x权限
S:group没有x权限
Sticky: other,占据other的执行权限位
t:other拥有x权限
T:other没有x权限
|
|
设定文件特殊属性
|
设置文件的特殊属性,可以访问 root 用户误操作删除或修改文件
|
不能删除,改名,更改
chattr +i file
只能追加内容,不能删除,改名
chattr +a file
显示特定属性
lsattr
|
例如:/etc/passwd文件处于被锁状态
|
|
访问控制列表 ACL
|
||
|
ACL
|
Access Control List,实现灵活的权限管理
|
|
|
除了文件的所有者,所属组和其它人,可以对更多的用户设置权限
CentOS7 默认创建的xfs和ext4文件系统具有ACL功能
CentOS7 之前版本,默认手工创建的ext4文件系统无ACL功能,需手动增加
|
tune2fs –o acl /dev/sdb1
mount –o acl /dev/sdb1 /mnt/test
|
|
|
ACL生效顺序
|
所有者,自定义用户,所属组|自定义组,其他人
|
|
|
setfacl
|
可设置ACL权限
|
#setfacl -m u:zxc:- a.txt
|
|
getfacl
|
可查看设置的ACL权限
|
#getfacl a.txt
|
|
mask 权限
|
mask只影响除所有者和other的之外的人和组的最大权限
mask需要与用户的权限进行逻辑与运算后,才能变成有限的权限(Effective Permission)
用户或组的设置必须存在于mask权限设定范围内才会生效
|
setfacl -m mask::rx file
#setfacl -m mask::rw f1.txt
#setfacl -m u:wang:rwx f1.txt
|
|
--set选项会把原有的ACL项都删除,用新的替代,需要注意的是一定要包含UGO的设置,不能象-m一样
只是添加ACL就可以
|
setfacl --set u::rw,u:wang:rw,g::r,o::- file1
|
|

|
文件内容查看
|
||
|
cat
查看文本内容
|
cat
[OPTION]…
[FILE]…
-E:显示行结束符$
-A:显示所有控制符
-n:对显示出的每一行进行编号
-b:非空行编号
-s:压缩连续的空行成一行
|
[08:55:46 root@rocky data]#cat -E j.log
123$
$
111$
|
|
nl
显示行号,相当于cat -b
|
-b a 无论是否是空行都列出行号
-b t 空行不列出行号(默认)
-n ln 行号在显示栏的最左边显示且空行不列出行号
-n rn 行号在显示栏的最右边显示,且空行不列出行号,不填充0
-n rz 行号在显示栏的最右边显示,且加0
|
每一行编号
#nl -b a 1.txt
#cat -n 1.txt
非空行编号
#nl -b t 1.txt
#cat -b 1.txt
|
|
tac
逆向显示文本内容
|
-s:使用指定字符串代替换行作为分隔标志
tac 1.txt 2.txt > tac.txt 文件合并
|
[09:22:35 root@rocky data]#echo "1,2" | tac -s ,
2
1,
[09:26:44 root@rocky data]#seq 3
1
2
3
[09:26:47 root@rocky data]#seq 3 | tac
3
2
1
|
|
rev
将同一行的内容逆向显示
|
反转“hello world”
#echo "hello world" | rev
反转日志文件中的后三行文本
#tail -n3 log.txt | rev
|
[09:32:47 root@rocky data]#rev
abcde
edcba
[09:32:55 root@rocky data]#echo {1..10} | rev
01 9 8 7 6 5 4 3 2 1
|
|
hexdump
以 ASCII、十进制、十六进制或八进制显示文件内容
|
hexdump[options]FILE[...]
-b 单字节八进制显示。
-c 单字节字符显示。
-C 规范化“十六进制+ASCII”显示。
-d 两字节十进制显示。
-e <format_string> 以指定的格式字符串显示数据。
-f <format_file> 指定包含一个或多个换行分隔格式字符串的文件。内容使用#号开头表示注释。
-n 只解释输入的指定长度个字节。
-o 两字节八进制显示。
-s 跳过开头指定长度个字节。
-v 显示时不压缩相似的行。-v选项使hextump显示所有输入数据。没有-v选项,任何数量的输出行组,如果与前一组相同,将被替换为由一个星号构成的行。
-x 两字节十六进制显示。
|
查看头文件
hexdump -C -n 512 /dev/sda
|
|
more
可以实现分页查看文件,可以配合管道实现输出信息的分页
|
more [OPTIONS...] FILE...
-d: 显示翻页及退出提示
|
[10:14:14 root@rocky ~]#more /var/log/messages
|
|
less
实现分页查看文件或STDIN输出,less 命令是man命令使用的分页器
|
查看时有用的命令包括:
/文本 搜索 文本
n/N 跳到下一个 或 上一个匹配
|
#less 配合管道对其它命令的执行结果进行分页显示
[root@centos8 ~]#tree -d /etc |less
/etc
├── alternatives
|
|
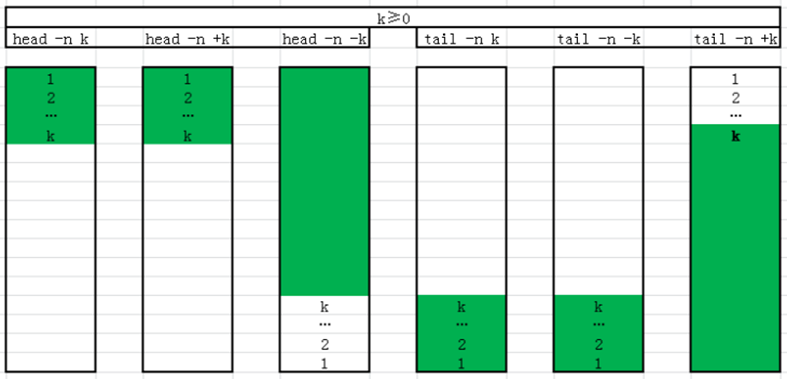
head
可以显示文件或标准输入的前面行
|
head [OPTION]... [FILE]...
-c # 指定获取前#字节
-n # 指定获取前#行,#如果为负数,表示从文件头取到倒数第#前
-# 同上
|
[root@centos8 ~]#cat /dev/urandom | tr -dc '[:alnum:]'| head -c10 |
tee pass.txt | passwd --stdin mage
|
|
tail
查看文件或标准输入的倒数行
tail 和head 相反
|
tail [OPTION]... [FILE]...
-c # 指定获取后#字节
-n # 指定获取后#行,如果#是负数,表示从第#行开始到文件结束
-# 同上
-f 跟踪显示文件fd新追加的内容,常用日志监控,相当于 --follow=descriptor,当文件删除再新
建同名文件,将无法继续跟踪文件
-F 跟踪文件名,相当于--follow=name --retry,当文件删除再新建同名文件,将可以继续跟踪文
件
tailf 类似 tail –f,当文件不增长时并不访问文件,节约资源,CentOS8已经无此工具
|
#只查看最新发生的日志
[root@centos8 ~]#tail -fn0 /var/log/messages
[root@centos8 ~]#tail -0f /var/log/messages
#取IP行
[root@centos8 data]#ifconfig | head -2 | tail -1
|
|
look
显示文件中以特定字符串开始的行
|
look [选项] string files
-d 只对比数字和英文字母,其他忽略
-f 忽略字符的大小写
-a 使用字典文件/usr/dict/web2
-t 指定字符串结束符
|
在look执行二进制搜索时,必须对文件中的行进行排序。如果未指定文件,则使用文件“/usr/share/dict/words“,只比较字母数字字符,忽略字母字符的大小写。
#look hello z.c
hello world,
|
|
文本处理工具
|
||
|
cut
提取文本文件或STDIN数据的指定列
|
cut [OPTION]... [FILE]...
-d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段,例如:3
#,#[,#]:离散的多个字段,例如:1,3,6
#-#:连续的多个字段, 例如:1-6
混合使用:1-3,7
-c 按字符切割
--output-delimiter=STRING指定输出分隔符
|
#cut -d: -f1,3-4,7 /etc/passwd
#ifconfig |head -n2 |tail -n1|tr -s " " |cut -d " " -f3
#cut -d: -f1,3,7 --output-delimiter="---" /etc/passwd
#echo {1..10}| cut -d ' ' -f1-10 --output-delimiter="+" |bc
#df | tail -n +2|tr -s ' ' |cut -d' ' -f5 |tr -d %
|
|
paste
合并多个文件同行号的列到一行
|
paste [OPTION]... [FILE]...
-d #分隔符:指定分隔符,默认用TAB
-s #所有行合成一行显示
|
#paste -d":" alpha.log seq.log
#paste -s seq.log
#paste -s -d: f1.log f2.log
[root@centos8 ~]#seq 10 |paste -s -d+|bc
55
批量修改密码
[root@centos8 ~]#paste -d: user.txt pass.txt|chpasswd
|
|
文本分析工具
|
||
|
wc
统计文件的行总数、单词总数、字节总数和字符总数
可以对文件或STDIN中的数据统计
|
-l 只计数行数
-w 只计数单词总数
-c 只计数字节总数
-m 只计数字符总数
-L 显示文件中最长行的长度
|
#wc story.txt
39 237 1901 story.txt
行数 单词数 字节数
#df | tail -n $(echo `df | wc -l`-1|bc)
|
|
sort
文本排序
把整理过的文本显示在STDOUT,不改变原始文件
|
sort [options] file(s)
-r 执行反方向(由上至下)整理
-R 随机排序
-n 执行按数字大小整理
-h 人类可读排序,如: 2K 1G
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique),合并重复项,即去重
-t c 选项使用c做为字段界定符
-k # 选项按照使用c字符分隔的 # 列来整理能够使用多次
|
#统计日志访问量
#cut -d" " -f1 /var/log/nginx/access_log |sort -u|wc -l
#查看分区利用率最高值
#df | tr -s " " %|cut -d% -f5|tr -d '[:alpha:]' | sort -nr|head -n1
|
|
uniq
从输入中删除前后相接的重复的行
|
uniq [OPTION]... [FILE]...
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
uniq常和sort 命令一起配合使用:
sort userlist.txt | uniq -c
|
统计日志访问量最多的请求
#lastb -f btmp-34 | tr -s ' ' |cut -d ' ' -f3|sort |uniq -c |sort -nr | head -3
并发连接最多的远程主机IP
#ss -nt|tail -n+2 |tr -s ' ' : |cut -d: -f6|sort|uniq -c|sort -nr |head -n2
#取文件的共同行
#cat test1.txt test2.txt | sort |uniq -d
#取文件的不同行
#cat test1.txt test2.txt | sort |uniq -u
|
|
diff
比较两个文件之间的区别
|
-u 选项来输出“统一的(unified)”diff格式文件,最适用于补丁文件
|
#diff -u f1.txt f2.txt
#diff -u f1.txt f2.txt > f.patch
|
|
path
复制在其它文件中进行的改变(要谨慎使用)
|
-b 选项来自动备份改变了的文件
|
diff -u foo.conf foo2.conf > foo.patch
patch -b foo.conf foo.patch
|
|
vimdiff
相当于 vim -d
|
#vimdiff f1.txt f2.txt
|
:qa
退出所有窗口
Vim中切换窗口(在文件之间切换)
切换窗口:Ctrl + w + (h/j/k/l) 。
即h左、j下、k上、l右,表示窗口切换的方向。
|
|
cmp
查看二进制文件的不同
|
#cmp /bin/dir /bin/ls
|
#cmp /bin/dir /bin/ls
#跳过前735个字节,观察后面30个字节
[root@centos8 ~]#hexdump -s 735 -Cn 30 /bin/ls
[root@centos8 ~]#hexdump -s 735 -Cn 30 /bin/dir
|
|
文件查找工具
|
||
|
locate
在文件系统上查找符合条件的文件
非实时查找(数据库查找)
|
locate [OPTION]... [PATTERN]...
-i 不区分大小写的搜索
-n N 只列举前N个匹配项目
-r 使用基本正则表达式
查询系统上预建的文件索引数据库 /var/lib/mlocate/mlocate.db
执行updatedb可以更新数据库
locate和updatedb命令来自于mlocate包
|
#搜索名称或路径中包含“conf"的文件
locate conf
#使用Regex来搜索以“.conf"结尾的文件
locate -r '\.conf$'
文件新创建和删除,无法马上更新locate数据库
|
|
find
在文件系统上查找符合条件的文件
实时查找
通过遍历指定路径完成文件查找
|
find [OPTION]... [查找路径] [查找条件] [处理动作]
指定搜索目录层级:
-maxdepth level 最大搜索目录深度,指定目录下的文件为第1级
-mindepth level 最小搜索目录深度
对每个目录先处理目录内的文件,再处理目录本身:
-depth
-d
根据文件名和inode查找:
-name "文件名称" #支持使用glob,如:*, ?, [], [^],通配符要加双引号引起来
-iname "文件名称" #不区分字母大小写
-inum n #按inode号查找
-samefile name #相同inode号的文件
-links n #链接数为n的文件
-regex “PATTERN" #以PATTERN匹配整个文件路径,而非文件名称
根据属主、属组查找:
-user USERNAME #查找属主为指定用户(UID)的文件
-group GRPNAME #查找属组为指定组(GID)的文件
-uid UserID #查找属主为指定的UID号的文件
-gid GroupID #查找属组为指定的GID号的文件
-nouser #查找没有属主的文件
-nogroup #查找没有属组的文件
|
根据文件类型查找:
-type TYPE
TYPE可以是以下形式:
f: 普通文件
d: 目录文件
l: 符号链接文件
s:套接字文件
b: 块设备文件
c: 字符设备文件
p: 管道文件
空文件或目录:
-empty
组合条件:
与:-a ,默认多个条件是与关系,所以可以省略-a
或:-o
非:-not !
排除目录:
#查找/etc/下,除/etc/security目录的其它所有.conf后缀的文件
find /etc -path '/etc/security' -a -prune -o -name "*.conf"
根据文件大小来查找:
-size [+|-]#UNIT #常用单位:k, M, G,c(byte),注意大小写敏感
#UNIT: #表示(#-1, #],如:6k 表示(5k,6k]
-#UNIT #表示[0,#-1],如:-6k 表示[0,5k]
+#UNIT #表示(#,∞),如:+6k 表示(6k,∞)
|
|
find
|
根据时间戳:
#以“天"为单位
-atime [+|-]#
# #表示[#,#+1)
+# #表示[#+1,∞]
-# #表示[0,#)
-mtime
-ctime
#以“分钟"为单位
-amin
-mmin
-cmin
根据权限查找:
-perm [/|-]MODE
MODE #精确权限匹配
/MODE #任何一类(u,g,o)对象的权限中只要有一位匹配即可,或关系,+ 从CentOS 7开始淘汰
-MODE #每一类对象都必须同时拥有指定权限,与关系
0 表示不关注
正则表达式:
-regextype type
-regex pattern
|
处理动作:
-print:默认的处理动作,显示至屏幕
-ls:类似于对查找到的文件执行"ls -dils"命令格式输出
-fls file:查找到的所有文件的长格式信息保存至指定文件中,相当于 -ls > file
-delete:删除查找到的文件,慎用!
-ok COMMAND {} \; 对查找到的每个文件执行由COMMAND指定的命令,对于每个文件执行命令之前,都会
交互式要求用户确认
-exec COMMAND {} \; 对查找到的每个文件执行由COMMAND指定的命令
{}: 用于引用查找到的文件名称自身
|
|
例子:
|
find /etc -maxdepth 2 -mindepth 2
#find -regex ".*\.txt$"
#查看/home的目录
find /home –type d -ls
#find /app -type d -empty
!A -a !B = !(A -o B)
!A -o !B = !(A -a B)
#找出/tmp目录下,属主不是root,且文件名不以f开头的文件
find /tmp \( -not -user root -a -not -name 'f*' \) -ls
find /tmp -not \( -user root -o -name 'f*' \) –ls
#排除/proc和/sys目录
find / \( -path "/sys" -o -path "/proc" \) -a -prune -o -type f -a -mmin -1
|
find -perm 755 会匹配权限模式恰好是755的文件
只要当任意人有写权限时,find -perm /222就会匹配
只有当每个人都有写权限时,find -perm -222才会匹配
只有当其它人(other)有写权限时,find -perm -002才会匹配
find /you/find/dir -regextype posix-extended -regex "regex"
#备份配置文件,添加.orig这个扩展名
find -name ".conf" -exec cp {} {}.orig \;
#提示删除存在时间超过3天以上的joe的临时文件
find /tmp -ctime +3 -user joe -ok rm {} \;
#在主目录中寻找可被其它用户写入的文件
find ~ -perm -002 -exec chmod o-w {} \;
#查找/data下的权限为644,后缀为sh的普通文件,增加执行权限
find /data –type f -perm 644 -name "*.sh" –exec chmod 755 {} \;
|
|
xargs
参数替换
由于很多命令不支持管道|来传递参数,xargs用于产生某个命令的参数,xargs 可以读入 stdin 的数
据,并且以空格符或回车符将 stdin 的数据分隔成为参数
另外,许多命令不能接受过多参数,命令执行可能会失败,xargs 可以解决
|
注意:文件名或者是其他意义的名词内含有空格符的情况
find | xargs COMMAND
#显示10个数字
[root@centos8 ~]#seq 10 | xargs
1 2 3 4 5 6 7 8 9 10
#删除当前目录下的大量文件
ls | xargs rm
find -name "*.sh" | xargs ls -Sl
[root@centos8 data]#echo {1..4} |xargs
1 2 3 4
[root@centos8 data]#echo {1..4} |xargs -n1
1
2
3
4
[root@centos8 data]#echo {1..4} |xargs -n2
1 2
3 4
#批量创建和删除用户
echo user{1..10} |xargs -n1 useradd
echo user{1..100} | xargs -n1 userdel -r
|
#这个命令是错误的
find /sbin/ -perm /700 | ls -l
#查找有特殊权限的文件,并排序
find /bin/ -perm /7000 | xargs ls -Sl
#此命令和上面有何区别?
find /bin/ -perm -7000 | xargs ls -Sl
#以字符nul分隔
find -type f -name "*.txt" -print0 | xargs -0 rm
#并发执行多个进程
seq 100 |xargs -i -P10 wget -P /data http://10.0.0.8/{}.html
#并行下载bilibili视频
yum install python3-pip -y
pip3 install you-get
seq 60 | xargs -i -P3 you-get https://www.bilibili.com/video/BV14K411W7UF?p={}
|
|
文本格式化命令
|
||
|
printf
格式化输出的命令
与 echo 类似
|
用法
printf FORMAT [ARGUMENT]...
printf OPTION
选项
-v VAR
将输出分配给 shell 变量 VAR 而不是在标准输出上显示。
--help
展示帮助文档并退出。
--version
展示版本信息并退出。
FORMAT 以 C语言的 printf 格式控制输出。格式字符如下:
\"
双引号。
\\
反斜杠。
\a
响铃。
\b
退格。
\c
取消后续输出。
\e
向右删除一个字符。
\f
换页。
\n
换行。
\r
回车。
\t
水平制表。
\v
垂直制表。
\NNN
八进制数 NNN 所代表的 ASCII 码字符。
\xHH
十六进制 HH 对应的8位字符。HH 可以是一到两位。
\uHHHH
十六进制 HHHH 对应的 Unicode 字符。HHHH 一到四位。
\UHHHHHHHH十六进制 HHHHHHHH 对应的 Unicode 字符。HHHHHHHH 一到八位。
%%
百分号。
%b
在相应的参数中展开反斜杠转义序列。
%q
以可重用为 shell 输入的方式引用参数。
%(fmt)T
输出使用 FMT 作为 strftime 的格式字符串产生的日期时间字符串。
|
[root@server ~]# printf "%5.5f\n" 370
370.00000
[root@server ~]# printf "%010.5f\n" 370
0370.00000
[root@server ~]# printf "%10.5f\n" 370
370.00000
[root@server ~]# printf "%+d\n" 370
+370
[root@server ~]# printf "%-d\n" 370
370
|
|
文本处理三剑客
|
||
|
grep
主要对文本的(正则表达式)行基于模式进行过滤
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查;打印匹配到的行
模式:由正则表达式字符及文本字符所编写的过滤条件
|
grep [OPTIONS] PATTERN [FILE...]
--color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,即取反
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
-w 匹配整个单词
-E 使用ERE,相当于egrep
-F 不支持正则表达式,相当于fgrep
-P 支持Perl格式的正则表达式
-f file 根据模式文件处理
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接
|
取两个文件的相同行
#grep -f /data/f1.txt /data/f2.txt
#cat /data/f1.txt /data/f2.txt| sort | uniq -d
分区利用率最大的值
#df |grep '^/dev/sd' |grep -oE '\<[0-9]{,3}%'|grep -Eo '[0-9]+' |sort -nr|head -n1
哪个IP和当前主机连接数最多的前三位
#ss -nt | grep "^ESTAB" |tr -s ' ' : |cut -d: -f6|sort |uniq -c|sort -nr|head -n3
连接状态的统计
# ss -nta | tail -n +2 |cut -d" " -f1|sort |uniq -c
#egrep -v '^(#|$)' /etc/httpd/conf/httpd.conf
#ifconfig eth0 | grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}'|head -1
过滤掉文件的注释(包括#号的行)和空行
#grep -Ev '^$|#' /etc/fstab
算出所有人的年龄总和
#grep -Eo "[0-9]+" /data/age.txt | tr '\n' + | grep -Eo ".*[0-9]"|bc
#grep -oE '[0-9]+' /data/age.txt| paste -s -d+|bc
|
|
sed
stream editor,文本编辑工具
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。模式空间(PatternSpace)。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象.一行一行的处理,打开速度非常快,执行速度也很快
|
sed [option]... 'script;script;...' [inputfile...]
-n 不输出模式空间内容到屏幕,即不自动打印
-e 多点编辑
-f FILE 从指定文件中读取编辑脚本
-r, -E 使用扩展正则表达式
-i.bak 备份文件并原处编辑
-s 将多个文件视为独立文件,而不是单个连续的长文件流
#说明:
-ir 不支持
-i -r 支持
-ri 支持
-ni 危险选项,会清空文件
script 格式:
'地址命令'
地址格式:
1. 不给地址:对全文进行处理
2. 单地址:
#:指定的行,$:最后一行
/pattern/:被此处模式所能够匹配到的每一行
3. 地址范围:
#,# #从#行到第#行,3,6 从第3行到第6行
#,+# #从#行到+#行,3,+4 表示从3行到第7行
/pat1/,/pat2/
#,/pat/
/pat/,#
4. 步进:~
1~2 奇数行
2~2 偶数行
|
命令:
p 打印当前模式空间内容,追加到默认输出之后
Ip 忽略大小写输出
d 删除模式空间匹配的行,并立即启用下一轮循环
a [\]text 在指定行后面追加文本,支持使用\n实现多行追加
i [\]text 在行前面插入文本
c [\]text 替换行为单行或多行文本
w file 保存模式匹配的行至指定文件
r file 读取指定文件的文本至模式空间中匹配到的行后
= 为模式空间中的行打印行号
! 模式空间中匹配行取反处理
q 结束或退出sed
查找替换:
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
替换修饰符:
g 行内全局替换
p 显示替换成功的行
w /PATH/FILE 将替换成功的行保存至文件中
I,i 忽略大小写
|
|
sed
|
高级命令
P 打印模式空间开端至\n内容,并追加到默认输出之前
h 把模式空间中的内容覆盖至保持空间中
H 把模式空间中的内容追加至保持空间中
g 从保持空间取出数据覆盖至模式空间
G 从保持空间取出内容追加至模式空间
x 把模式空间中的内容与保持空间中的内容进行互换
n 读取匹配到的行的下一行覆盖至模式空间
N 读取匹配到的行的下一行追加至模式空间
d 删除模式空间中的行
D 如果模式空间包含换行符,则删除直到第一个换行符的模式空间中的文本,并不会读取新的输入行,而使
用合成的模式空间重新启动循环。如果模式空间不包含换行符,则会像发出d命令那样启动正常的新循环
|
#默认sed会将输入信息直接输出
#sed '/^#/d;/^$/d' /etc/httpd/conf/httpd.conf
#不显示注释行和空行
#删除所有以#开头的行
[root@centos8 ~]#sed -i '/^#/d' fstab
#只显示非#开头的行
[root@centos8 ~]#sed -n '/^#/!p' fstab
#修改网卡配置
[root@centos8 ~]#sed -Ei.bak '/^GRUB_CMDLINE_LINUX/s/(.*)(")$/\1
net.ifnames=0\2/' /etc/default/grub
搜索替换和&
#sed -nr 's/r..t/&er/gp' /etc/passwd
获取分区利用率
#df | sed -En '/^\/dev\/sd/s@.* ([0-9]+)%.*@\1@p'
取IP 地址
#ifconfig eth0 | sed -rn '2s/(.*inet )([0-9].*)( netmask.*)/\2/p'
#取目录名
#echo /etc/sysconfig/ | sed -rn 's#(.*)/([^/]+)/?#\1#p'
#取基名
#echo /etc/sysconfig/ | sed -rn 's#(.*)/([^/]+)/?#\2#p'
取文件的前缀和后缀
#echo a.b.tar.gz | sed -rn 's@.*\.([^.]+)\.([^.]+)$@\1.\2@p'
将#开头的行删除#
#sed -ri.bak '/^#/s/^#//' /etc/fstab
变量实现多点编辑配置文件
#sed -ri.bak -e 's/^Listen 80/Listen '$port'/' -e "/ServerName/c ServerName `hostname`:$port" /etc/httpd/conf/httpd.conf
|
|
awk
Linux上的实现gawk,文本报告生成器
|
awk [options] 'program' var=value file…
awk [options] -f programfile var=value file…
print item1, item2, ...
逗号分隔符
输出item可以字符串,也可是数值;当前记录的字段、变量或awk的表达式
如省略item,相当于print $0
固定字符符需要用“ ” 引起来,而变量和数字不需要
|
取出分区利用率
#df | awk '{print $1,$5}'
#使用扩展的正则表达式
#df | awk -F"[[:space:]]+|%" '{print $5}'
|



总结文本处理的grep命令相关的基本正则和扩展正则表达式
一、 基本正则表达式
正则表达式的元字符分类:字符匹配、匹配次数、位置锚定、分组
①字符匹配:
. 匹配任意单个字符(除了\n),可以是一个汉字或其它国家的文字
[] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
[^] 匹配指定范围外的任意单个字符,示例:[^wang]
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
-----------------
\s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符
\S #匹配任何非空白字符。等价于 [^\f\r\t\v]
\w #匹配一个字母,数字,下划线,汉字,其它国家文字的字符,等价于[_[:alnum:]字]
\W #匹配一个非字母,数字,下划线,汉字,其它国家文字的字符,等价于[^_[:alnum:]字]
②匹配次数
用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* #匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* #任意长度的任意字符
\? #匹配其前面的字符出现0次或1次,即:可有可无
\+ #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
\{n\} #匹配前面的字符n次
\{m,n\} #匹配前面的字符至少m次,至多n次
\{,n\} #匹配前面的字符至多n次,<=n
\{n,\} #匹配前面的字符至少n次
③位置锚定
位置锚定可以用于定位出现的位置
^ #行首锚定, 用于模式的最左侧
$ #行尾锚定,用于模式的最右侧
^PATTERN$ #用于模式匹配整行
^$ #空行
^[[:space:]]*$ #空白行
\< 或 \b #词首锚定,用于单词模式的左侧
\> 或 \b #词尾锚定,用于单词模式的右侧
\<PATTERN\> #匹配整个单词
#注意: 单词是由字母,数字,下划线组成
④分组
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:\(root\)+
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
方式为: \1, \2, \3, ...
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
注意: \0 表示正则表达式匹配的所有字符
\(string1\(string2\)\)
\1 :string1\(string2\)
\2 :string2
注意: 后向引用 引用前面的分组括号中的模式所匹配字符,而非模式本身
⑤或者
或者:\|
a\|b #a或b
C\|cat #C或cat
\(C\|c\)at #Cat或cat
二、 扩展正则表达式
①字符匹配
. 任意单个字符
[wang] 指定范围的字符
[^wang] 不在指定范围的字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
②次数匹配
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
③位置锚定
^ 行首
$ 行尾
\<, \b 语首
\>, \b 语尾
④分组其他
() 分组
后向引用:\1, \2, ... 注意: \0 表示正则表达式匹配的所有字符
| 或者
a|b #a或b
C|cat #C或cat
(C|c)at #Cat或cat




|
lsblk
|
列出块设备
|
||
|
fdisk
|
创建分区命令:管理MBR分区
|
fdisk -l [-u] [device...]
查看分区
fdisk [device...]
管理MBR分区
|
p 分区列表
t 更改分区类型
n 创建新分区
d 删除分区
v 校验分区
u 转换单位
w 保存并退出
q 不保存并退出
|
|
gdisk
|
创建分区命令:管理GPT分区
|
gdisk [device...]
类fdisk 的GPT分区工具
|
|
|
parted
|
创建分区命令:高级分区操作,可以是交互或非交互方式
|
||
|
partprobe
|
重新设置内存中的内核分区表版本,适合于除了CentOS 6 以外的其它版本 5,7,8
|
||
|
parted
|
磁盘分区;parted的操作都是实时生效的,小心使用
|
parted [选项]... [设备 [命令 [参数]...]...]
|
parted /dev/sdb mklabel gpt|msdos
parted /dev/sdb print
parted /dev/sdb mkpart primary 1 200 (默认M)
parted /dev/sdb rm 1
parted -l
列出所有硬盘分区信息
|
|
cat /proc/partitions
|
查看内核是否已经识别新的分区
|
||
|
新增分区用
partx -a /dev/DEVICE
kpartx -a /dev/DEVICE -f: force
#示例:
[root@centos6 ~]#partx -a /dev/sda
|
CentOS6 通知内核重新读取硬盘分区表
|
||
|
删除分区用
partx -d --nr M-N /dev/DEVICE
#示例:
[root@centos6 ~]#partx -d --nr 6-8 /dev/sda
|
|||
|
echo -e 'n\np\n\n\n+2G\nw\n' | fdisk /dev/sdc
|
非交互式创建分区
|
||
|
partx -a /dev/sda
|
同步分区表
|
||
|
支持的文件系统
|
/lib/modules/`uname -r`/kernel/fs
|
||
|
cat /proc/filesystems
|
|||
|
mkfs
|
创建文件系统
|
mkfs.FS_TYPE /dev/DEVICE
|
FS_TYPE:
ext4
xfs
btrfs
vfat
|
|
mkfs -t FS_TYPE /dev/DEVICE
|
-L 'LABEL' 设定卷标
|
||
|
mke2fs
|
ext系列文件系统专用管理工具
|
-t {ext2|ext3|ext4|xfs} 指定文件系统类型
-b {1024|2048|4096} 指定块 block 大小
-L ‘LABEL’ 设置卷标
-j 相当于 -t ext3, mkfs.ext3 = mkfs -t ext3 = mke2fs -j = mke2fs -t ext3
-i
# 为数据空间中每多少个字节创建一个inode;不应该小于block大小
-N
# 指定分区中创建多少个inode
-I 一个inode记录占用的磁盘空间大小,128---4096
-m
# 默认5%,为管理人员预留空间占总空间的百分比
-O FEATURE[,...] 启用指定特性
-O ^FEATURE 关闭指定特性
|
|
|
blkid
|
可以查看块设备属性信息
|
blkid [OPTION]... [DEVICE]
|
-U UUID 根据指定的UUID来查找对应的设备
-L LABEL 根据指定的LABEL来查找对应的设备
|
|
e2label
|
管理ext系列文件系统的LABEL
|
e2label DEVICE [LABEL]
|
|
|
findfs
|
查找分区
|
findfs [options] LABEL=
findfs [options] UUID=
|
#findfs UUID=f7f53add-b184-4ddc-8d2c-5263b84d1e15
#findfs `sed -En '/data/s#^([^ ]+).*#\1#p' /etc/fstab`
|
|
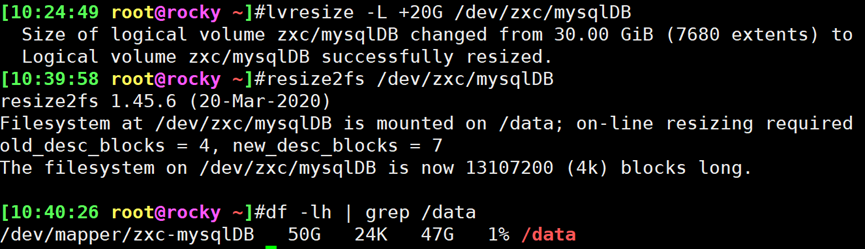
tune2fs
|
重新设定
ext
系列文件系统可调整参数的值
|
-l 查看指定文件系统超级块信息;super block
-L 'LABEL’ 修改卷标
-m # 修预留给管理员的空间百分比
-j 将ext2升级为ext3
-O 文件系统属性启用或禁用, -O ^has_journal
-o 调整文件系统的默认挂载选项,-o ^acl
-U UUID 修改UUID号
|
|
|
dumpe2fs
|
显示ext文件系统信息,将磁盘块分组管理
|
-h:查看超级块信息,不显示分组信息
#dumpe2fs /dev/sda1
|
|
|
xfs_info
|
显示示挂载或已挂载的 xfs 文件系统信息
|
xfs_info mountpoint|devname
|
#xfs_info /dev/sda7
|
|
fsck
|
文件系统检测和修复
|
fsck.FS_TYPE
fsck -t FS_TYPE
|
注意:一定不要在挂载状态下执行下面命令修复
FS_TYPE 一定要与分区上已经文件类型相同
-a 自动修复
-r 交互式修复错误
|
|
e2fsck
|
ext系列文件专用的检测修复工具
|
-y 自动回答为yes
-f 强制修复
-p 自动进行安全的修复文件系统问题
|
|
|
xfs_repair
|
xfs文件系统专用检测修复工具
|
-f 修复文件,而设备
-n 只检查
-d 允许修复只读的挂载设备,在单用户下修复 / 时使用,然后立即reboot
|
|
|
修改破坏的ext文件系统
|
[root@centos8 ~]#mount /dev/sdb2 /mnt
[root@centos8 ~]#cp /etc/fstab /mnt/f1
[root@centos8 ~]#cp /etc/fstab /mnt/f2
[root@centos8 ~]#ls /mnt
[root@centos8 ~]#dd if=/dev/zero of=/dev/sdb2 bs=1M count=1
[root@centos8 ~]#ls /mnt
[root@centos8 ~]#tune2fs -l /dev/sdb2
[root@centos8 ~]#df
[root@centos8 ~]#umount /mnt
[root@centos8 ~]#e2fsck /dev/sdb2
[root@centos8 ~]#e2fsck /dev/sdb2 -y
[root@centos8 ~]#tune2fs -l /dev/sdb2
[root@centos8 ~]#mount /dev/sdb2 /mnt
[root@centos8 ~]#ls /mnt
[root@centos8 ~]#cat /mnt/f1
|
||
|
mount
|
挂载文件系统
|
mount [-fnrsvw] [-t vfstype] [-o options] device mountpoint
device:指明要挂载的设备
设备文件:例如:/dev/sda5
卷标:-L 'LABEL', 例如 -L 'MYDATA'
UUID: -U 'UUID':例如 -U '0c50523c-43f1-45e7-85c0-a126711d406e'
伪文件系统名称:proc, sysfs, devtmpfs, configfs
mountpoint:挂载点目录必须事先存在,建议使用空目录
mount 常用命令选项
-t fstype 指定要挂载的设备上的文件系统类型,如:ext4,xfs
-r readonly,只读挂载
-w read and write, 读写挂载,此为默认设置,可省略
-n 不更新/etc/mtab,mount不可见
-a 自动挂载所有支持自动挂载的设备(定义在了/etc/fstab文件中,且挂载选项中有auto功能)
-L 'LABEL' 以卷标指定挂载设备
-U 'UUID' 以UUID指定要挂载的设备
-B, --bind 绑定目录到另一个目录上
|
|
|
-o options:(挂载文件系统的选项),多个选项使用逗号分隔
async
异步模式,内存更改时,写入缓存区buffer,过一段时间再写到磁盘中,效率高,但不安全
sync
同步模式,内存更改时,同时写磁盘,安全,但效率低下
atime/noatime 包含目录和文件
diratime/nodiratime 目录的访问时间戳
auto/noauto 是否支持开机自动挂载,是否支持-a选项
exec/noexec 是否支持将文件系统上运行应用程序
dev/nodev 是否支持在此文件系统上使用设备文件
suid/nosuid 是否支持suid和sgid权限
remount 重新挂载
ro/rw 只读、读写
user/nouser 是否允许普通用户挂载此设备,/etc/fstab使用
acl/noacl 启用此文件系统上的acl功能
loop 使用loop设备
_netdev
当网络可用时才对网络资源进行挂载,如:NFS文件系统
defaults 相当于rw, suid, dev, exec, auto, nouser, async
挂载规则:
一个挂载点同一时间只能挂载一个设备
一个挂载点同一时间挂载了多个设备,只能看到最后一个设备的数据,其它设备上的数据将被隐藏
一个设备可以同时挂载到多个挂载点
通常挂载点一般是已存在空的目录
|
|||
|
umount
|
卸载文件系统
|
umount 设备名|挂载点
|
|
|
查看挂载情况
|
通过查看/etc/mtab文件显示当前已挂载的所有设备
mount
#查看内核追踪到的已挂载的所有设备
cat /proc/mounts
查看挂载点情况
findmnt
MOUNT_POINT|device
查看正在访问指定文件系统的进程
lsof MOUNT_POINT
fuser -v MOUNT_POINT
终止所有在正访问指定的文件系统的进程
fuser -km MOUNT_POINT
|
||
|
swapon
|
启用swap分区
|
swapon [OPTION]... [DEVICE]
|
-a
#激活所有的交换分区
-p PRIORITY #指定优先级(-1到32767之间),值越大,优先级越高.也可在/etc/fstab文件中的第4列指定:pri=value
|
|
创建swap分区
|
[root@centos8 ~]#echo -e 'n\np\n\n\n+2G\nt\n82\nw\n' | fdisk /dev/sdc
[root@centos8 ~]#mkswap /dev/sdc1
[root@centos8 ~]#blkid /dev/sdc1
[root@centos8 ~]#vim /etc/fstab
UUID=d3140a7a-65b7-4cb7-8a2b-12d38aa98c6f swap
swap defaults 0 0
[root@centos8 ~]#swapon -a
[root@centos8 ~]#free -h
[root@centos8 ~]#cat /proc/swaps
|
||
|
swapoff
|
禁用swap分区
|
swapoff [OPTION]...[DEVICE]
|
[root@centos8 ~]#sed -i.bak '/swap/d' /etc/fstab
[root@centos8 ~]#swapoff -a
|
|
以文件实现swap功能
|
[root@centos8 ~]#dd if=/dev/zero of=/swapfile bs=1M count=1024
[root@centos8 ~]#mkswap /swapfile
[root@centos8 ~]#blkid /swapfile >> /etc/fstab
[root@centos8 ~]#/etc/fstab
/swapfile swap
swap
defaults
0 0 #不要用
UUID,使用文件的路径
[root@centos8 ~]#chmod 600 /swapfile
[root@centos8 ~]#swapon -a
[root@centos8 ~]#swapon -s
|
||
|
RAID等级
|
最少硬盘
|
最大容错
|
可用容量
|
读取性能
|
写入性能
|
安全性
|
目的
|
应用场景
|
|
单一硬盘
|
(参考)
|
0
|
1
|
1
|
1
|
无
|
||
|
JBOD
|
1
|
0
|
n
|
1
|
1
|
无(同RAID0)
|
增加容量
|
个人(暂时)存储备份
|
|
0
|
1
|
0
|
n
|
n
|
n
|
一个硬盘异常,全部硬盘都会异常
|
追求最大容量、速度
|
影片剪接缓存用途
|
|
1
|
2
|
n-1
|
1
|
n
|
1
|
高,一个正常即可
|
追求最大安全性
|
个人、企业备份
|
|
5
|
3
|
1
|
n-1
|
n-1
|
n-1
|
高
|
追求最大容量、最小预算
|
个人、企业备份
|
|
6
|
4
|
2
|
n-2
|
n-2
|
n-2
|
安全性较RAID5高
|
同RAID5,但较安全
|
个人、企业备份
|
|
10
|
4
|
高
|
综合RAID 0/1优点,理论速度较快
|
大型数据库、服务器
|
||||
|
50
|
6
|
高
|
提升数据安全
|
|||||
|
60
|
8
|
高
|
提升数据安全
|






 浙公网安备 33010602011771号
浙公网安备 33010602011771号