
关于爬虫能做的事情,源自知乎刘飞,原嘟嘟美甲产品总监、原锤子科技产品经理
该轮到我祭出我当年研究生期间在实验室里参与或旁观的各种有用或者有趣的课题了:
1. 建立机器翻译的语料库。
这是我研究生期间的核心课题,我先来介绍下背景。
大家其实都用过谷歌翻译、百度翻译,虽然确实槽点很多,但不妨碍机器翻译相较过去已经达到基本可用的程度了。
我大概说下机器翻译的原理。
在几十年前,计算机学家们的思路是,既然是人工智能的范畴,就让计算机懂得语法规则、知道词语含义,跟小孩子上学时学习的语言课程一样去做训练,就应该可以了。
但结果是,基于语义和语法规则的机器翻译效果糟糕得一塌糊涂。
究其原因,还是每个词语的含义实在太多、每句话的语境不同意思也会不同,更别说不同语言中要表达清楚同一个意思的方式也完全不同。
比如下图这个,你觉得英语国家的人能看懂吗:
其实,当时也有另一派,叫做统计派。他们认为,就跟当年战胜国际象棋世界冠军的“深蓝(深蓝(美国国际象棋电脑))”一样,应当用统计的方式去做。大家知道,“深蓝”并没有领会象棋的下法,而只是熟悉几百万的棋局,懂得怎样走从概率上看起来是最正确的。
机器翻译也是这样,完全可以输入人工翻译的大量语料,然后做出统计模型,让计算机尽可能地熟悉别人是怎么翻译的,从而耳濡目染,也能“假装”可以翻译了。
但那个年代并没有条件收集大量语料信息。后来很多年后,谷歌出现了,随之出现的还有它的超大数据规模和超强的计算能力,于是谷歌的统计机器翻译系统也就是全球正确率最高的系统之一了。而目前你所用过的、见到的机器翻译工具,全都是用的统计方法。
故事大概就是这样。目前学术界的机器翻译方法中,统计机器翻译基本是垄断的地位。而效果的好坏,则基本就看语料库的规模。(想了解更多,推荐阅读 数学之美 (豆瓣) 的第2章“‘自然语言处理 — 从规则到统计”及第3章“统计语言模型”)
所以你知道了,我的任务就是跟同学做一个爬虫和简易的分析系统,从而建立一个大规模的语料库。
网上双语的资源还是挺多的,大都像这种:
我们的爬取步骤大概是:
1. 对当前网页进行简易判断,如果有双语嫌疑,则收录整理出来双语的正文;如果没有,弃用;
2. 将正文内容进行详细判断,确定是双语文本,则进行段落对齐和句子对齐,整理到语料库;如果没有,弃用;
3. 对当前网页的所有链接网页,重复步骤 1
有详细介绍的我们申请的专利在这里:http://www.soopat.com/Patent/201210442487
其实我们当时的双语判断算法和对齐算法这些都不是难点,难点在机器配置、爬虫设计和服务器维护上。我们几乎天天流窜在机房(配置机器、接线、装机)、实验室(编写、运行代码)、网络中心(跪求带宽)、学校物业(空调他妈又坏了)这几个地方,总是没法消停。
最痛苦的是,假期里回家远程访问下爬虫,发现 down 机了... 整个假期的宝贵时间就浪费了。
这是我们当时在又闷又热又吵的机房的照片:
好在最后我们终于爬到了要求的语料规模,并且通过了国家项目的验收。现在这些包括中英俄日的庞大语料正在百度翻译中起到重要的作用,如果你用过百度翻译,不妨给我点个感谢 ^_^
如果你对机器翻译感兴趣,也可以自己爬点双语语料,做个翻译器玩玩。这是一个极其简易的搭建教程:机器翻译系统的搭建。可以用它介绍的 1500 句对,也可以自己多爬一些。搭建好之后,你输入一句话,看到机器像模像样地回一句半生不熟的翻译,还是有可能会被萌到的。
当然,要是你希望像我们一样搭建千万级甚至亿级的语料库,并且做一个翻译器,那你需要有特别强大计算能力和存储能力的服务器、非常宽的带宽,以及强大的耐心和毅力...
2. 社会计算方面的统计和预测
很多朋友已经提到了可以通过爬虫得到的数据做一些社会计算的分析。我们实验室爬取了大规模的新浪微博内容数据(可能是非商用机构中最多的),并针对这些数据做了很多有趣的尝试。
2.1 情绪地图
@Emily L 提到了著名的根据情绪预测股市的论文:http://battleofthequants.net/wp-content/uploads/2013/03/2010-10-15_JOCS_Twitter_Mood.pdf 。其实我们也仿照做了国内的,不过没有预测,只是监测目前微博上大家的情绪,也是极有趣的。
我们把情绪类型分为“喜悦”“愤怒”“悲伤”“恐惧”“惊奇”,并且对能体现情绪的词语进行权重的标记,从而给每天每个省份都计算出一个情绪指数。
界面大概是这样: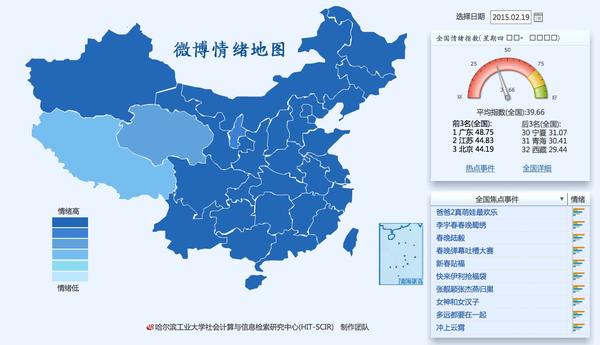
可以直观看到全国各省份的情绪。不过实际上我感觉省份的区别不明显,最明显的是每天全国情绪指数的变动。
比如春节是 2 月 18 日,那天的情绪指数是 41.27,前一天是 33.04,后一天则是 39.66。跟除夕夜都在吐槽和抱怨春晚,而大年初一则都在拜年情绪高涨,初二有所回落这样的状况预估是一致的。
比如今年 1 月 2 日,上海踩踏事故开始登上各大媒体头条,成了热点话题,整个微博的情绪指数就骤降到 33.99 。
再比如 5 月份情绪指数最高的是 5·20,因为今年开始流行示爱和表白;其次就是五一假期那几天。同样跟现实状况的预估是一致的。
访问地址:http://123.126.42.100:5929/flexweb/index.html
2.2 饮食地图
我们抽取出所有美食相关词语,然后基于大家提到的美食次数,做了这么一份饮食地图。你可以查看不同省份、不同性别的用户、不同的时间段对不同类别食物的关注程度。
比如你可以看到广东整体的美食关注:
还可以把男的排除掉,只看女的: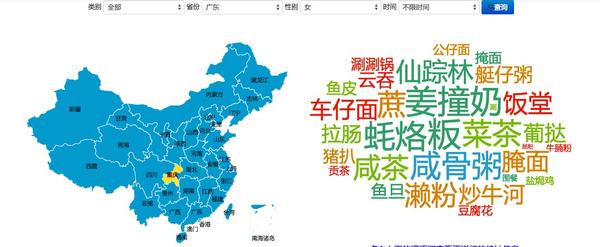
还可以具体到,看广东女性每天早上会提到什么喝的: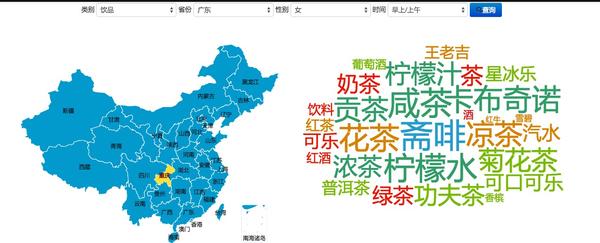
访问地址:微博用户饮食习惯分析
2.3 票房预测
这是我们实验室最大胆的尝试,希望利用微博上大家表现出来的,对某部电影的期待值和关注度,来预测其票房。
细节就不介绍了,目前对某些电影的预测比较准,某些则差很多。因为显然,很多电影是大家不用说也会默默买票,而很多电影是大家乐于讨论但不愿出钱到电影院去看的。
界面是这样的: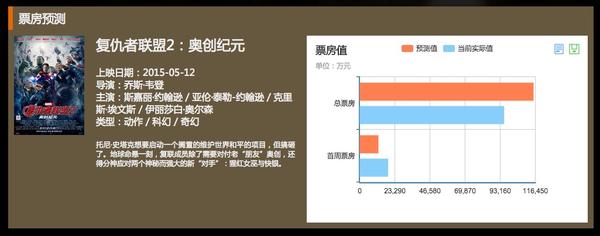
访问地址:电影票房预测-SCIR
最后贴上我们实验室的官方网站:哈尔滨工业大学社会计算与信息检索研究中心
3. 写在后面
现在国内的社交平台(微博、豆瓣、知乎)已经积累了很多信息,在上面可分析的事情太多啦。大到政府部门需要的舆情监控,小到可以看看喜欢的姑娘最近情绪如何。
其中有些会特别有价值,比如一些重要的预测(股市预测、票房预测),真的做成了的话商业价值根本不可估量;还有些会特别有趣,比如看看 5·20 的时候大家最爱说的情话是什么,看看我跟李开复之间最近的关系链是什么。
说到这,我突然很想做个知乎的分析。
在内容方面,比如看看全知乎的文字里最常出现的人名到底是 @张佳玮还是 @梁边妖;比如看看政治或者历史话题下,以表达情绪的词作为依据,大家的正能量多还是负能量多;比如看看当大家提到哪些东西时,情绪会最激动(中医?老罗?穆斯林?)。
在关系方面,比如看看我的朋友、传说中认识所有知乎女 V 的 @丁澤宇 到底还有哪个女 V 没有关注;比如看看知乎有哪些社交达人,虽然没多少赞但关系链却在大 V 们中间;比如看看有没有关注了我同时还被 @朱炫 关注的,这样我可以托他给我介绍大师兄。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号