
scrapy使用一:介绍及安装
scrapy框架:基于twisted异步网络框架来处理网络通讯,集成了爬虫(如之前用到的beatifulsoup,xpath)的功能。
scrapy架构图:
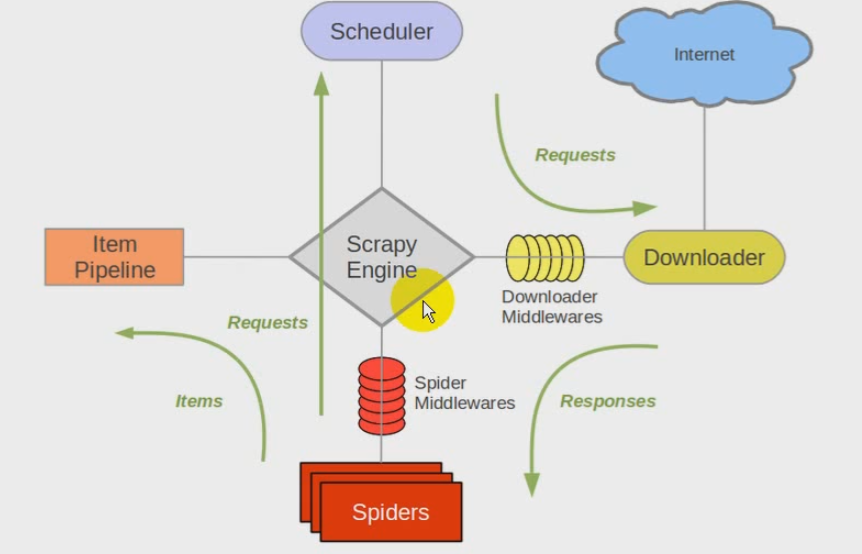
scrapy engine引擎:负责spider,itempipeline,downloader,scheduler中间的通讯、信号、数据传递等。
scheduler调度器:负责接受引擎发送过来的request请求,并按照一定的方式进行整理排列、入队,当引擎需要时,交还给引擎。
downloader下载器:负责下载scray engine引擎发送的所有requests请求,并将其获取到的response交还给引擎,由引擎交给spider来处理。
spider爬虫:负责处理所有的响应response,从中分析提取数据,获取item字段需要的数据,并将需要跟进的url提交给引擎,再次进入scheduler调度器
item pipeline管道:负责处理spider中获取到的item,并进行后期处理(详细分析、过滤、存储等)的地方
downloader middlewares下载中间件:当作是一个可以自定义扩展下载功能的组件,如自定义user agent等
spider middlewares(spider中间件):是一个可以自定义扩展和操作引擎和spider中间通信的功能组修的,如进入spider的responses和从spider出去的requests
scrapy流程:
1.引擎:hi spider,你要处理哪个网站?
2.spider:我要处理xxx.com网站
3.引擎:你把第一个需要处理的url给我吧
4.spider:给你,第一个url是xx.com
5.引擎:hi 调度器,这里有个request请求,你帮我排序入队。
6.调度器,好的,正在处理其它请求,你等一下。
7.引擎:hi 调度器,把你处理好的request请求给我。
8.调度器:给你,这是我处理好的request
9.引擎:hi 下载器,你按照老大的下载中间件的设置,帮我下载这个request请求。
10下载器:好的,给你,这是下载好的东西。如果下载失败,引擎告诉调度器,这个request下载失败了,你记录一下,待会再下载。
11.引擎:hi spider,这是下载好的东西,并且按照下载中间件处理过了。交还response给spider。
12.spider:处理完毕数据后,对于需要跟进的url。hi,引擎,这里有两个结果,这个是我需要跟进的url,还有这个是我获取的item数据。
13.引擎:hi ,管道。这儿有个item你帮我处理一下。hi,调度器。这是需要跟进的url,你帮我处理一下;然后从第四步开始循环,直到获取完需要的全部信息。
14.管道、调度器:好的,现在就做!
注意:只有当调度器中不存在任何request了,整个程序才会停止。如果下载失败的url,scrapy会重新下载。
制作scrapy爬虫,一共需要4步:
- 新建项目:scrapy startproject xxxxx
- 明确目标:编写 items.py,明确你想要抓取的目标
- 制作爬虫:spiders/xxxxspider.py,制作爬虫开爬取网页
- 存储内容:pipelines.py,设计管道存储爬取内容
scrapy的安装:
- windows或linux:pip install scrapy
- ubuntu:安装非python依赖:sudo apt-get install python-dev python-pip libxml2-dev libxstl1-dev zlibig-dev libffi-dev libssl-dev,然后再sudo pip install scrapy
在命令终端,执行scrapy,如果成功,则安装成功。
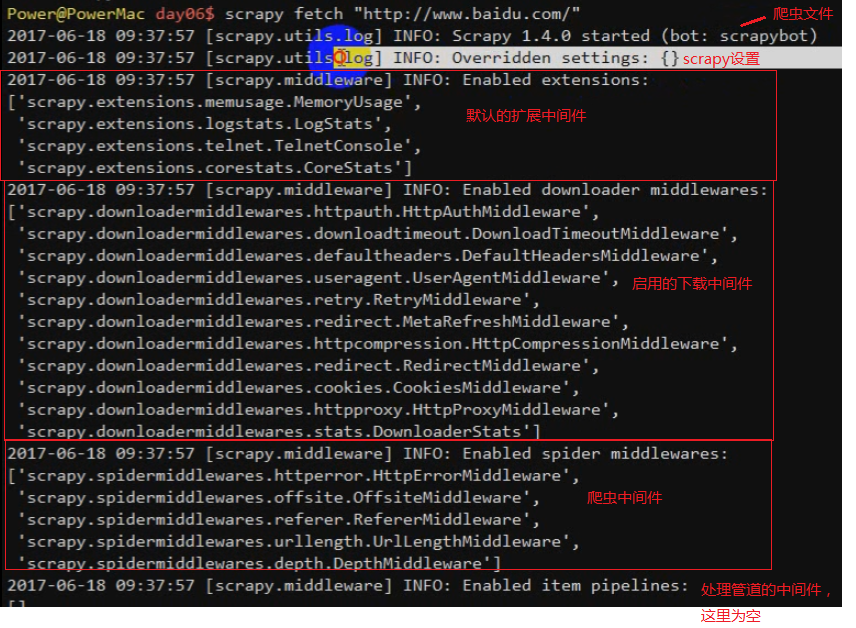
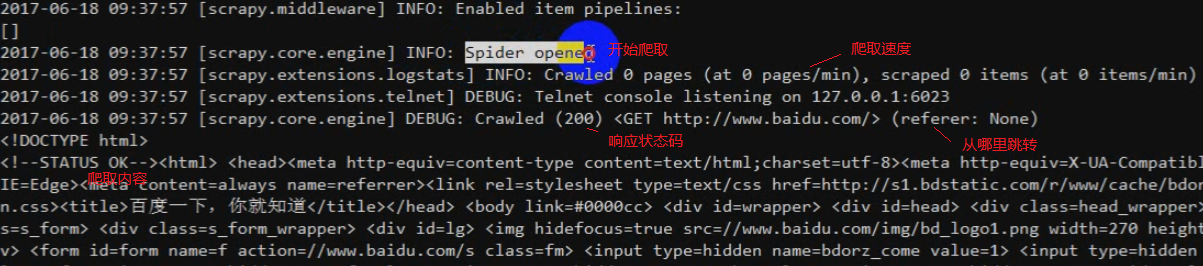
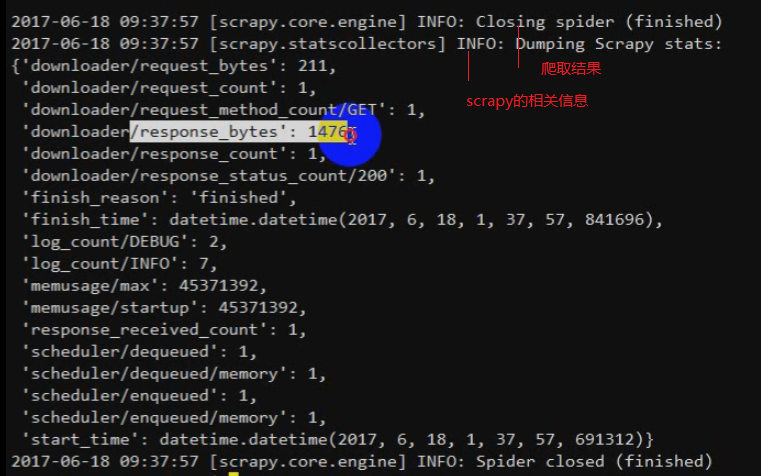
scrapy的官方文档:https://scrapy-chs.readthedocs.io/zh_CN/latest/
posted on 2018-10-03 15:27 myworldworld 阅读(126) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号