爬虫小试牛刀(爬取学校通知公告)
- 完成抓取并解析DGUT通知公告12页数据,并提交excel文件格式数据,数据需要包含日期标题,若能够实现将详情页主体内容与发布人信息数据也一并抓取更佳
- 提交内容:Excel数据文件
爬虫开始
首先看到页面呈现规则的各个方框,这意味着它们之间的一定是一样的
此处该有图
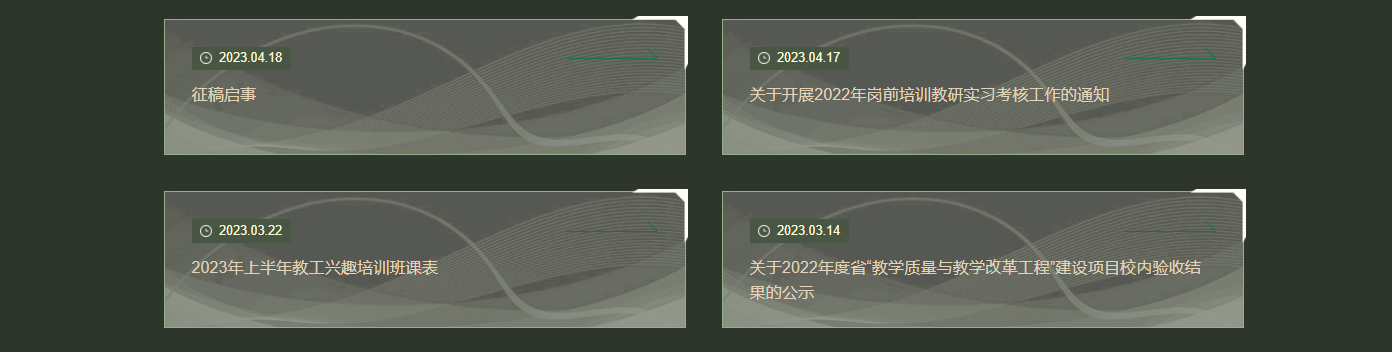
我们点开后台可以看见属于通知活动的代码中很多这类
<li>
<a href="../info/1042/48792.htm" target="_blank" title="关于开展2018届毕业生中期发展评价的通知">
<div class="box">
<div class="time">
<div class="ll">
<img src="../images/list_box_07_ico.png" alt="">2023.06.09
</div>
<div class="rr">
<img src="../images/list_box_24_ico.png" alt="">
</div>
</div>
<h5 class="overfloat-dot-2">关于开展2018届毕业生中期发展评价的通知</h5>
</div>
</
那么我们可以分别截取一下几个标签,分别是
时间标签:<div class="ll">
标题标签:<h5 class="overfloat-dot-2">
前期工作准备结束了,让我们打开pycharm,引入本次的包
import requests #经典请求包
from bs4 import BeautifulSoup
import pandas as pd #生成xlsx文档包
为了我们的页面的中文正常输出,我们必须对获取的内容进行一个转码
url = 'example.com' + str(page) + '.htm'
r = requests.get(url)
r.encoding = 'utf-8'
我观察到页面的顺序并不是从1往后的,而是从第12页为1.html,第11页为2.html,以此类推,而第一页则是index/tzgg.htm。
所以我的循环体设置循环12次,最后一次如果返回的是404的话,则访问的上面的网页
if r.status_code == 404:
url = 'example.com/index/tzgg.htm'
r = requests.get(url)
r.encoding = 'utf-8'
根据开头的标签,接下来就可以直接获取该标签上面的内容
title = article.find('h5', {'class': 'overfloat-dot-2'}).text.strip()
date = article.find('div', {'class': 'll'}).text.strip()
此时你会发现我没有解释这个article怎么来的,是因为我发现如果只是按照上面的方法直接获取
所以为了区别开其他的同种标签,页面范围内比
articles = soup.find('section', {'class': 'n_container'})
articles = articles.find_all('li')
到这里,时间和标题我们就得到了。接下来我们需要到详情页去获取发布者名字
同样,详情页的url也在
href = article.find('a', href=True)
href = href['href']
article_detail_url = 'example.com' + href
然后通过再访问这个链接进去以同样的方式获取发布者名字,还得和上文一样,分开是不是第一页的子链接,如果是则需要更换第一页的url才能防止返回404状态。
article_detail_url = 'example.com/index/tzgg/' + href
# 获取详情页信息
detail_r = requests.get(article_detail_url)
if detail_r.status_code == 404:
url = 'example.com'+href
detail_r=requests.get(url)
detail_r.encoding = 'utf-8'
detail_soup = BeautifulSoup(detail_r.text, 'html.parser')
author = detail_soup.find('h6').find_all('span')[2].text
我们需要的信息就完全抓取下来了。本次任务就结束了,接下来的导出excel文件
# 将数据存储成DataFrame,并导出为Excel文件
df = pd.DataFrame(data_list, columns=['日期', '标题', '发布者'])
df.to_excel('通知公告.xlsx', index=False)
总结
这次做完通知公告爬虫,感觉不是很难,因为网站没有对请求头进行限制,所以让我直接request就行了。
不过这次让我对python在爬虫之类的作用更加感兴趣,希望下次能了解更多的这类知识,以后也能学会如何防爬虫的知识。
本文来自博客园,作者:hellciw,转载请注明原文链接:https://www.cnblogs.com/hellciw/p/17492550.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号