
『计算机视觉』Mask-RCNN_训练网络其二:train网络结构&损失函数
Github地址:Mask_RCNN
『计算机视觉』Mask-RCNN_论文学习
『计算机视觉』Mask-RCNN_项目文档翻译
『计算机视觉』Mask-RCNN_推断网络其一:总览
『计算机视觉』Mask-RCNN_推断网络其二:基于ReNet101的FPN共享网络
『计算机视觉』Mask-RCNN_推断网络其三:RPN锚框处理和Proposal生成
『计算机视觉』Mask-RCNN_推断网络其四:FPN和ROIAlign的耦合
『计算机视觉』Mask-RCNN_推断网络其五:目标检测结果精炼
『计算机视觉』Mask-RCNN_推断网络其六:Mask生成
『计算机视觉』Mask-RCNN_推断网络终篇:使用detect方法进行推断
『计算机视觉』Mask-RCNN_锚框生成
『计算机视觉』Mask-RCNN_训练网络其一:数据集与Dataset类
『计算机视觉』Mask-RCNN_训练网络其二:train网络结构&损失函数
『计算机视觉』Mask-RCNN_训练网络其三:训练Model
一、training网络简介
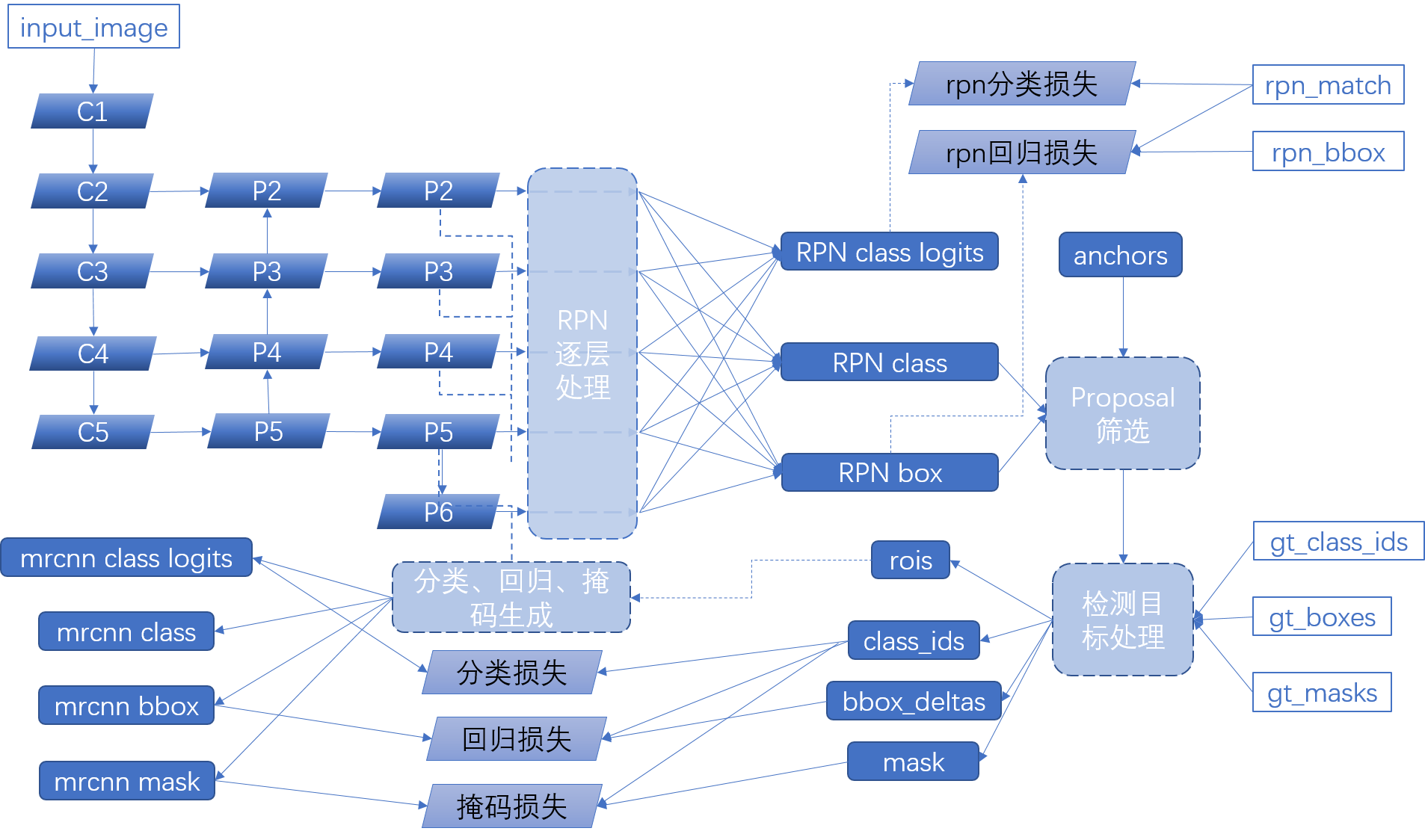
流程和inference大部分一致,在下图中我们将之前inference就介绍过的分类、回归和掩码生成流程压缩到一个块中,以便其他部分更为清晰。而两者主要不同之处为:
- 网络输入:输入tensor增加到了7个之多(图上画出的6个以及image_meta),大部分是计算Loss的标签前置
- 损失函数:添加了5个损失函数,2个用于RPN计算,2个用于最终分类回归instance,1个用于掩码损失计算
- 原始标签处理:推理网络中,Proposeal筛选出来的rpn_rois直接用于生成分类回归以及掩码信息,而training中这些候选区需要和图片标签信息进行运算,生成有训练价值的输出,进行后面的生成以及损失函数计算
首先初始化并载入预训练参数(下节会介绍本部分相关操作),
然后经由下面几行代码,即可进行训练,

网络输入
build函数在train方法中被调用(model.py),涉及巨多预处理函数设计,需要的时候自行进入train方法查看(更确切的说是在data_generator方法,由train调用),
- images: [batch, H, W, C]
- image_meta: [batch, (meta data)] Image details. See compose_image_meta()
- rpn_match: [batch, N] Integer (1=positive anchor, -1=negative, 0=neutral)
- rpn_bbox: [batch, N, (dy, dx, log(dh), log(dw))] Anchor bbox deltas.
- gt_class_ids: [batch, MAX_GT_INSTANCES] Integer class IDs
- gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)]
- gt_masks: [batch, height, width, MAX_GT_INSTANCES]. The height and width
are those of the image unless use_mini_mask is True, in which
case they are defined in MINI_MASK_SHAPE.
原始标签处理
然后我们在开篇流程图中标注了一个名为"检测目标处理"的框,对应代码如下:
# Generate detection targets
# Subsamples proposals and generates target outputs for training
# Note that proposal class IDs, gt_boxes, and gt_masks are zero
# padded. Equally, returned rois and targets are zero padded.
rois, target_class_ids, target_bbox, target_mask =\
DetectionTargetLayer(config, name="proposal_targets")([
target_rois, input_gt_class_ids, gt_boxes, input_gt_masks])
其目的是将原始的图像信息input和proposal们进行计算融合,输出可以用于Loss计算的标准的格式,文档很清晰,
"""Subsamples proposals and generates target box refinement, class_ids,
and masks for each.
Inputs:
proposals: [batch, N, (y1, x1, y2, x2)] in normalized coordinates. Might
be zero padded if there are not enough proposals.
gt_class_ids:[batch, MAX_GT_INSTANCES] Integer class IDs.
gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)] in normalized
coordinates.
gt_masks: [batch, height, width, MAX_GT_INSTANCES] of boolean type
Returns: Target ROIs and corresponding class IDs, bounding box shifts,
and masks.
rois: [batch, TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized
coordinates
target_class_ids: [batch, TRAIN_ROIS_PER_IMAGE]. Integer class IDs.
target_deltas: [batch, TRAIN_ROIS_PER_IMAGE, (dy, dx, log(dh), log(dw)]
target_mask: [batch, TRAIN_ROIS_PER_IMAGE, height, width]
Masks cropped to bbox boundaries and resized to neural
network output size.
Note: Returned arrays might be zero padded if not enough target ROIs.
"""
这个处理之后,结构同inference中的介绍,
mrcnn_class_logits, mrcnn_class, mrcnn_bbox =\
fpn_classifier_graph(rois, mrcnn_feature_maps, input_image_meta,
config.POOL_SIZE, config.NUM_CLASSES,
train_bn=config.TRAIN_BN,
fc_layers_size=config.FPN_CLASSIF_FC_LAYERS_SIZE)
mrcnn_mask = build_fpn_mask_graph(rois, mrcnn_feature_maps,
input_image_meta,
config.MASK_POOL_SIZE,
config.NUM_CLASSES,
train_bn=config.TRAIN_BN)
损失函数
然后就是损失函数了(浩浩荡荡10来行……),注意output_rois这一行,我们之前就提过,keras中接收tf的Tensor只能作为class的初始化参数,而不能作为网络数据流,所以这里加了一层封装,
output_rois = KL.Lambda(lambda x: x * 1, name="output_rois")(rois)
# Losses
rpn_class_loss = KL.Lambda(lambda x: rpn_class_loss_graph(*x), name="rpn_class_loss")(
[input_rpn_match, rpn_class_logits])
rpn_bbox_loss = KL.Lambda(lambda x: rpn_bbox_loss_graph(config, *x), name="rpn_bbox_loss")(
[input_rpn_bbox, input_rpn_match, rpn_bbox])
class_loss = KL.Lambda(lambda x: mrcnn_class_loss_graph(*x), name="mrcnn_class_loss")(
[target_class_ids, mrcnn_class_logits, active_class_ids])
bbox_loss = KL.Lambda(lambda x: mrcnn_bbox_loss_graph(*x), name="mrcnn_bbox_loss")(
[target_bbox, target_class_ids, mrcnn_bbox])
mask_loss = KL.Lambda(lambda x: mrcnn_mask_loss_graph(*x), name="mrcnn_mask_loss")(
[target_mask, target_class_ids, mrcnn_mask])
二、损失函数简介
RPN分类损失
我们先看一下RPN真实标签生成函数中的一段注释,
# Match anchors to GT Boxes
# If an anchor overlaps a GT box with IoU >= 0.7 then it's positive.
# If an anchor overlaps a GT box with IoU < 0.3 then it's negative.
# Neutral anchors are those that don't match the conditions above,
# and they don't influence the loss function.
# However, don't keep any GT box unmatched (rare, but happens). Instead,
# match it to the closest anchor (even if its max IoU is < 0.3).
然后看本损失函数,
def rpn_class_loss_graph(rpn_match, rpn_class_logits):
"""RPN anchor classifier loss.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_class_logits: [batch, anchors, 2]. RPN classifier logits for FG/BG.
"""
# Squeeze last dim to simplify
rpn_match = tf.squeeze(rpn_match, -1)
# Get anchor classes. Convert the -1/+1 match to 0/1 values.
anchor_class = K.cast(K.equal(rpn_match, 1), tf.int32)
# Positive and Negative anchors contribute to the loss,
# but neutral anchors (match value = 0) don't.
indices = tf.where(K.not_equal(rpn_match, 0))
# Pick rows that contribute to the loss and filter out the rest.
rpn_class_logits = tf.gather_nd(rpn_class_logits, indices)
anchor_class = tf.gather_nd(anchor_class, indices)
# Cross entropy loss
loss = K.sparse_categorical_crossentropy(target=anchor_class,
output=rpn_class_logits,
from_logits=True)
loss = K.switch(tf.size(loss) > 0, K.mean(loss), tf.constant(0.0))
return loss
真实标签有{1, 0, -1}三种,logits结果在0~1分布,而在RPN分类结果中,真实标签为0的anchors不参与损失函数的构建,所以我们将标签为0的真实标签剔除,然后将-1标签转换为0进行交叉熵计算。
RPN回归损失
def rpn_bbox_loss_graph(config, target_bbox, rpn_match, rpn_bbox):
"""Return the RPN bounding box loss graph.
config: the model config object.
target_bbox: [batch, max positive anchors, (dy, dx, log(dh), log(dw))].
Uses 0 padding to fill in unsed bbox deltas.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_bbox: [batch, anchors, (dy, dx, log(dh), log(dw))]
"""
# input_rpn_bbox, input_rpn_match, rpn_bbox
# Positive anchors contribute to the loss, but negative and
# neutral anchors (match value of 0 or -1) don't.
rpn_match = K.squeeze(rpn_match, -1) # [batch, anchors]
indices = tf.where(K.equal(rpn_match, 1))
# Pick bbox deltas that contribute to the loss
rpn_bbox = tf.gather_nd(rpn_bbox, indices) # [n, 4]
# Trim target bounding box deltas to the same length as rpn_bbox.
batch_counts = K.sum(K.cast(K.equal(rpn_match, 1), tf.int32), axis=1) # 1标签数目
# target_bbox: [batch, max positive anchors, (dy, dx, log(dh), log(dw))]
# rpn_match: [batch]
target_bbox = batch_pack_graph(target_bbox, batch_counts,
config.IMAGES_PER_GPU)
loss = smooth_l1_loss(target_bbox, rpn_bbox)
loss = K.switch(tf.size(loss) > 0, K.mean(loss), tf.constant(0.0))
return loss
仅仅真实标签为1的类参与回归运算,
- 对于target_bbox,虽然对每张图片其框数一致且和rpn_match的第二维度相等,但是对于图片i只有前面的Ni个框有意义(而不是和anchors一一对应的),后面为0填充,Ni值等于对应图片的rpn_match等于1的数目
- (推测)target_bbox中bbox坐标的排列顺序等于rpn_match中的标识顺序,所以使用rpn_match索引出rpn_bbox对应1的位置后直接和target_bbox的前Ni运算即可
def batch_pack_graph(x, counts, num_rows):
"""Picks different number of values from each row
in x depending on the values in counts.
x: [batch, max positive anchors, (dy, dx, log(dh), log(dw))]
counts: [batch]
"""
outputs = []
for i in range(num_rows):
outputs.append(x[i, :counts[i]])
return tf.concat(outputs, axis=0)
损失函数使用smooth_l1_loss(坐标回归都用这个?)
def smooth_l1_loss(y_true, y_pred):
"""Implements Smooth-L1 loss.
y_true and y_pred are typically: [N, 4], but could be any shape.
"""
diff = K.abs(y_true - y_pred)
less_than_one = K.cast(K.less(diff, 1.0), "float32")
loss = (less_than_one * 0.5 * diff**2) + (1 - less_than_one) * (diff - 0.5)
return loss
附
我在数据准备函数build_rpn_targets中查询到如下片段,可以佐证上面说法(下面的rpn_box对应上面的target_bbox),即target_box和anchor并不一一对应,仅根据正样本标签数目进行填充,
代码片段1(两者注册长度都不一样):
# RPN Match: 1 = positive anchor, -1 = negative anchor, 0 = neutral
rpn_match = np.zeros([anchors.shape[0]], dtype=np.int32)
# RPN bounding boxes: [max anchors per image, (dy, dx, log(dh), log(dw))]
rpn_bbox = np.zeros((config.RPN_TRAIN_ANCHORS_PER_IMAGE, 4))
代码片段2:
# For positive anchors, compute shift and scale needed to transform them
# to match the corresponding GT boxes.
ids = np.where(rpn_match == 1)[0]
ix = 0 # index into rpn_bbox
# TODO: use box_refinement() rather than duplicating the code here
for i, a in zip(ids, anchors[ids]):
# Closest gt box (it might have IoU < 0.7)
gt = gt_boxes[anchor_iou_argmax[i]]
# Convert coordinates to center plus width/height.
# GT Box
gt_h = gt[2] - gt[0]
gt_w = gt[3] - gt[1]
gt_center_y = gt[0] + 0.5 * gt_h
gt_center_x = gt[1] + 0.5 * gt_w
# Anchor
a_h = a[2] - a[0]
a_w = a[3] - a[1]
a_center_y = a[0] + 0.5 * a_h
a_center_x = a[1] + 0.5 * a_w
# Compute the bbox refinement that the RPN should predict.
rpn_bbox[ix] = [
(gt_center_y - a_center_y) / a_h,
(gt_center_x - a_center_x) / a_w,
np.log(gt_h / a_h),
np.log(gt_w / a_w),
]
# Normalize
rpn_bbox[ix] /= config.RPN_BBOX_STD_DEV
ix += 1
return rpn_match, rpn_bbox
MRCNN分类损失函数
如果分类得分最高class不对应于本数据集,则不贡献Loss值。
def mrcnn_class_loss_graph(target_class_ids, pred_class_logits,
active_class_ids):
"""Loss for the classifier head of Mask RCNN.
target_class_ids: [batch, num_rois]. Integer class IDs. Uses zero
padding to fill in the array.
pred_class_logits: [batch, num_rois, num_classes]
active_class_ids: [batch, num_classes]. Has a value of 1 for
classes that are in the dataset of the image, and 0
for classes that are not in the dataset.
"""
# During model building, Keras calls this function with
# target_class_ids of type float32. Unclear why. Cast it
# to int to get around it.
target_class_ids = tf.cast(target_class_ids, 'int64')
# Find predictions of classes that are not in the dataset.
pred_class_ids = tf.argmax(pred_class_logits, axis=2)
# TODO: Update this line to work with batch > 1. Right now it assumes all
# images in a batch have the same active_class_ids
pred_active = tf.gather(active_class_ids[0], pred_class_ids)
# Loss
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=target_class_ids, logits=pred_class_logits) # [batch, num_rois]
# Erase losses of predictions of classes that are not in the active
# classes of the image.
loss = loss * pred_active # [batch, num_rois]~{0, 1} * [batch, num_rois]
# Computer loss mean. Use only predictions that contribute
# to the loss to get a correct mean.
loss = tf.reduce_sum(loss) / tf.reduce_sum(pred_active)
return loss
涉及到active_class_ids相关如下,即将该图片隶属数据集中所有的class标记为1,不隶属本数据集合的class标记为0,计算Loss贡献时交叉熵会对每个框进行输出一个值,如果这个框最大的得分class并不属于其数据集,则不计本框Loss:
active_class_ids = KL.Lambda(
lambda x: parse_image_meta_graph(x)["active_class_ids"]
)(input_image_meta)
# # Active classes
# # Different datasets have different classes, so track the
# # classes supported in the dataset of this image.
# active_class_ids = np.zeros([dataset.num_classes], dtype=np.int32)
# source_class_ids = dataset.source_class_ids[dataset.image_info[image_id]["source"]]
# active_class_ids[source_class_ids] = 1
MRCNN回归损失函数
仅计算真实标签非背景class(分类数大于0);
由于预测对于每个框体的每个类别都有回归输出([batch, num_rois, num_classes, (dy, dx, log(dh), log(dw))]),仅计算真实类别的回归Loss
代码如下:
def mrcnn_bbox_loss_graph(target_bbox, target_class_ids, pred_bbox):
"""Loss for Mask R-CNN bounding box refinement.
target_bbox: [batch, num_rois, (dy, dx, log(dh), log(dw))]
target_class_ids: [batch, num_rois]. Integer class IDs.
pred_bbox: [batch, num_rois, num_classes, (dy, dx, log(dh), log(dw))]
"""
# Reshape to merge batch and roi dimensions for simplicity.
target_class_ids = K.reshape(target_class_ids, (-1,)) # [batch*num_rois]
target_bbox = K.reshape(target_bbox, (-1, 4))
pred_bbox = K.reshape(pred_bbox, (-1, K.int_shape(pred_bbox)[2], 4))
# Only positive ROIs contribute to the loss. And only
# the right class_id of each ROI. Get their indices.
# class_ids: N, where(class_ids > 0): [M, 1] 即where会升维
positive_roi_ix = tf.where(target_class_ids > 0)[:, 0] # [M]
positive_roi_class_ids = tf.cast(
tf.gather(target_class_ids, positive_roi_ix), tf.int64)
# [(框序号,真实类别id),……]
indices = tf.stack([positive_roi_ix, positive_roi_class_ids], axis=1)
# Gather the deltas (predicted and true) that contribute to loss
target_bbox = tf.gather(target_bbox, positive_roi_ix)
pred_bbox = tf.gather_nd(pred_bbox, indices)
# Smooth-L1 Loss
loss = K.switch(tf.size(target_bbox) > 0,
smooth_l1_loss(y_true=target_bbox, y_pred=pred_bbox),
tf.constant(0.0))
loss = K.mean(loss)
return loss
MRCNN掩码损失函数
keras的二进制交叉熵实际调用的就是sigmoid交叉熵的后端,详见:『TensorFlow』分类问题与交叉熵
def mrcnn_mask_loss_graph(target_masks, target_class_ids, pred_masks):
"""Mask binary cross-entropy loss for the masks head.
target_masks: [batch, num_rois, height, width].
A float32 tensor of values 0 or 1. Uses zero padding to fill array.
target_class_ids: [batch, num_rois]. Integer class IDs. Zero padded.
pred_masks: [batch, proposals, height, width, num_classes] float32 tensor
with values from 0 to 1.
"""
# Reshape for simplicity. Merge first two dimensions into one.
target_class_ids = K.reshape(target_class_ids, (-1,))
mask_shape = tf.shape(target_masks)
target_masks = K.reshape(target_masks, (-1, mask_shape[2], mask_shape[3]))
pred_shape = tf.shape(pred_masks)
pred_masks = K.reshape(pred_masks,
(-1, pred_shape[2], pred_shape[3], pred_shape[4]))
# Permute predicted masks to [N, num_classes, height, width]
pred_masks = tf.transpose(pred_masks, [0, 3, 1, 2])
# Only positive ROIs contribute to the loss. And only
# the class specific mask of each ROI.
positive_ix = tf.where(target_class_ids > 0)[:, 0]
positive_class_ids = tf.cast(
tf.gather(target_class_ids, positive_ix), tf.int64)
indices = tf.stack([positive_ix, positive_class_ids], axis=1)
# Gather the masks (predicted and true) that contribute to loss
y_true = tf.gather(target_masks, positive_ix)
y_pred = tf.gather_nd(pred_masks, indices)
# Compute binary cross entropy. If no positive ROIs, then return 0.
# shape: [batch, roi, num_classes]
loss = K.switch(tf.size(y_true) > 0,
K.binary_crossentropy(target=y_true, output=y_pred),
tf.constant(0.0))
loss = K.mean(loss)
return loss

 浙公网安备 33010602011771号
浙公网安备 33010602011771号