
『计算机视觉』R-FCN:Object Detection via Region-based Fully Convolutional Networks
一、网络介绍
参考文章:R-FCN详解
论文地址:Object Detection via Region-based Fully Convolutional Networks
R-FCN是Faster-RCNN的改进型,其速度提升了2.5倍以上,并略微提高了准确度。
二、论文创新
提出Position-sensitive score maps来解决目标检测的位置敏感性问题
位置敏感性

分类网络的位置不敏感性
检测网络的位置敏感性
三、R-FCN思路
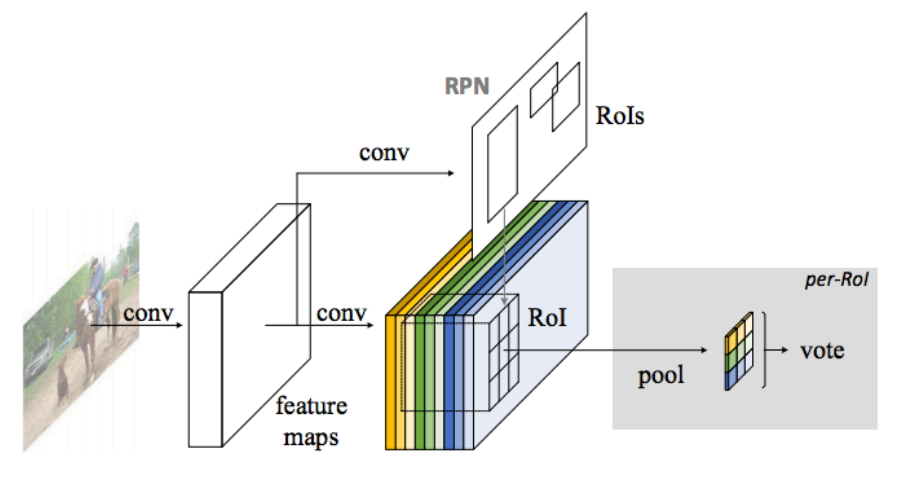
如下图所示,主体部分和Faster-RCNN一样:
- 图片首先进入特征提取网络
- 然后进行分支操作:
- RPN部分没什么改变,输出两个损失函数判断anchor是否是前景,然后筛选出特定个数的候选框
- 下面支路进行卷积输出即为position-sensitive score map,本层不改变大小,输出维度是重点:K*K*(C+1)
- 下图并未画出来,还需要一个卷积支路输出K*K*4通道的特征,称作位置敏感得分映射,用于回归位置修正
position-sensitive score map 分类信息处理
下面我们来着重讲解下面支路的处理。
接前一段所述,我们的到K*K*(C+1)维的features,这里的C+1表示的就是分类数(包含背景类别),而K我们可以理解为Faster-RCNN的ROIing后输出的尺度K*K,以下图为例,这里我们的K实际就是3,对应着ROIPooling后输出3*3的小图,了解了这个事实,我们来讲解为什么这样做。
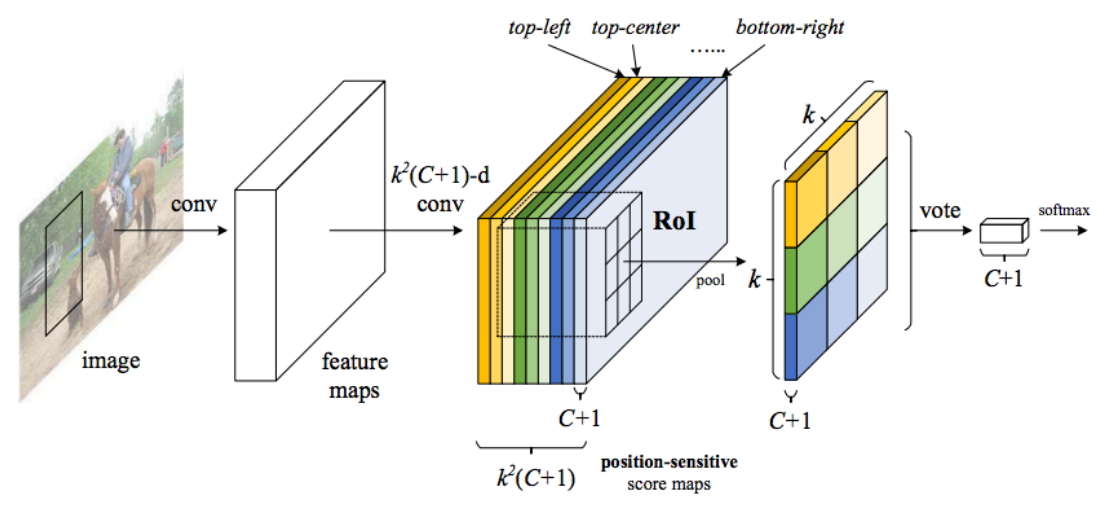
看到上图,了解Faster-RCNN的同学可能疑惑:K*K*(C+1)的features为什么ROIPooling后维度变为C+1了?实际上这里的操作并不是标准的ROIPooling:我们的features实际被分成K*K组,每组C+1层,每组对应ROIPooling后的结果的一个位置(如图ROIPooling输出3*3共九个点,所以我们需要9组)。
RPN获取候选框后,我们在position-sensitive score map找到对应的位置,然后对应位置ROI操作对应的features组,以上图来看,输出左上角的橙色数字来源于第一组的C+1层features的候选框区域的左上角(比较拗口,对比颜色很容易理解)。
这么做的目的就是:我们希望这K*K组features,每组对应于候选物体的对应部分(比如识别一匹马,其中一组对应一匹马图片的左上角位置,这里经常出现马头、马尾巴这样),使得分类任务具有位置敏感性。
ROI示意如下:


和Faster-RCNN类似,从RPN产生后开始,各个候选区域的处理(ROI及其之后)不再共享,有多少候选框,计算多少次。
分类信息ROI结果处理
ROI之后获得的K*K*(C+1)特征对应于C+1个分类,直接求和(或者平均池化)为C+1向量即可,softmax处理一下,获取最终的分类信息。
回归信息处理
我们的到的是K*K*4通道的features,类似分类,使用ROI处理,获取K*K大小4通道的特征,进而类似获取4个值作为该ROI的x,y,w,h的偏移量,其思路和分类完全相同。
Loss计算及其分析
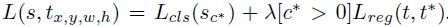
这个Loss就是两阶段目标检测框架常用的形式。包括一个分类Loss和一个回归Loss。lamdy用来平衡两者的重要性。对于任意一个RoI,我们需要计算它的softmax损失,和当其不属于背景时的回归损失。这很简单,因为每个RoI都被指定属于某一个GT box或者属于背景,即先选择和GT box具有最大重叠率(IOU)的Rol,然后在剩余的Rol中选择与GT box的重叠率值大于0.5Rol进行匹配操作,最后将剩余的Rol都归为背景类。即每个Rol都有了对应的标签,我们就可以根据监督学习常用的方法来训练它。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号