

『计算机视觉』经典RCNN_其二:Faster-RCNN
一、Faster-RCNN简介
『计算机视觉』Faster-RCNN学习_其一:目标检测及RCNN谱系
一篇讲的非常明白的文章:一文读懂Faster RCNN
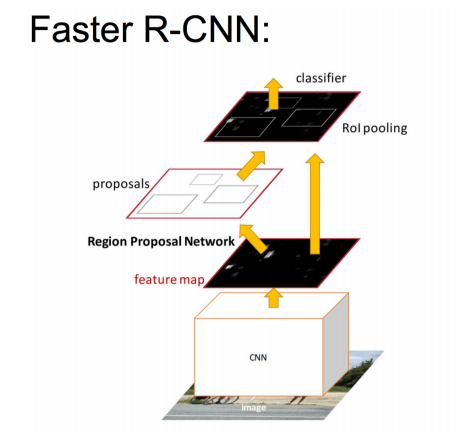
(1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN生成建议窗口(proposals),每张图片保留约300个建议窗口;
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
相比FAST-RCNN,主要两处不同
(1)使用RPN(Region Proposal Network)代替原来的Selective Search方法产生建议窗口;
(2)产生建议窗口的CNN和目标检测的CNN共享
改进
快速产生建议框:FASTER-RCNN创造性地采用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有本质的提高.
RPN简介
放到整体网络中如下,
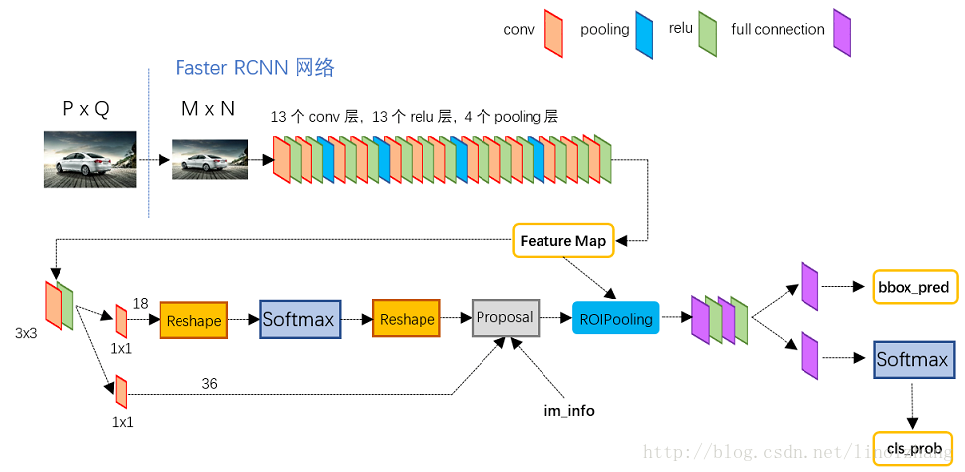
对于共享的Feature Map,RPN使用3*3的滑窗,每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高),对应36个坐标、18个分类。
训练过程中,
1)丢弃跨越边界的anchor;
2)与样本重叠区域大于0.7的anchor标记为前景,重叠区域小于0.3的标定为背景;
总结一下:
• 在feature map上滑动窗口
• 建一个神经网络用于物体分类+框位置的回归
• 滑动窗口的位置提供了物体的大体位置信息
• 框的回归提供了框更精确的位置
这里的分类只需要区分候选框内特征为前景或者背景,这里的边框回归也是为了之后获得更精确的目标位置。

损失函数
故整个网络包含四个损失函数;
• RPN calssification(anchor good.bad),判断anchor前景背景类别
• RPN regression(anchor->propoasal),计算anchor和gt box的偏差,利用mask仅计算前景anchor
• Fast R-CNN classification(over classes),判断proposal分类,包含类别数C+背景
• Fast R-CNN regression(proposal ->box),计算proposal和gt box的偏差,利用mask仅计算类别的proposal
注意到前两个损失函数目标是修正anchor,后两个损失函数目标是修正proposal,实际上产生了众多anchors后,会进行筛选(非极大值抑制并按照前景得分排序等等),选出特定比例的前景背景anchors作为proposal进行后面的运算。

二、代码解读

Faster-RCNN网络设计很是复杂,个人觉得但看论文或者其他材料并不能很好的理解这套流程,本篇我们从实际的代码出发,看看到底是这套网络系统到底是如何设计的。
anchor和proposal
region proposal(或者简称proposal,或者简称ROI),可以说RPN网络的目的就是为了得到proposal,这些proposal是对ground truth更好的刻画(和anchor相比,坐标更贴近ground truth,毕竟anchor的坐标都是批量地按照scale和aspect ratio复制的)。如果你还记得在系列二中关于网络结构的介绍,那么你就应该了解到RPN网络的回归支路输出的值(offset)作为smooth l1损失函数的输入之一时,其含义就是使得proposal和anchor之间的offset(RPN网络的回归支路输出)尽可能与ground truth和anchor之间的offset(RPN网络的回归支路的回归目标)接近。
调包部分
涉及了mx基础框架和一个作者自己创建的operate,
import mxnet as mx from symnet import proposal_target
特征提取器一
如开篇的图,这里是最上面一行的网络,即提取Feature Map的部分,使用了4个pooling层,意味着原始图像:Feature Map = 16:1,

def get_vgg_feature(data):
# group 1
conv1_1 = mx.symbol.Convolution(
data=data, kernel=(3, 3), pad=(1, 1), num_filter=64, workspace=2048, name="conv1_1")
relu1_1 = mx.symbol.Activation(data=conv1_1, act_type="relu", name="relu1_1")
conv1_2 = mx.symbol.Convolution(
data=relu1_1, kernel=(3, 3), pad=(1, 1), num_filter=64, workspace=2048, name="conv1_2")
relu1_2 = mx.symbol.Activation(data=conv1_2, act_type="relu", name="relu1_2")
pool1 = mx.symbol.Pooling(
data=relu1_2, pool_type="max", kernel=(2, 2), stride=(2, 2), name="pool1")
# group 2
conv2_1 = mx.symbol.Convolution(
data=pool1, kernel=(3, 3), pad=(1, 1), num_filter=128, workspace=2048, name="conv2_1")
relu2_1 = mx.symbol.Activation(data=conv2_1, act_type="relu", name="relu2_1")
conv2_2 = mx.symbol.Convolution(
data=relu2_1, kernel=(3, 3), pad=(1, 1), num_filter=128, workspace=2048, name="conv2_2")
relu2_2 = mx.symbol.Activation(data=conv2_2, act_type="relu", name="relu2_2")
pool2 = mx.symbol.Pooling(
data=relu2_2, pool_type="max", kernel=(2, 2), stride=(2, 2), name="pool2")
# group 3
conv3_1 = mx.symbol.Convolution(
data=pool2, kernel=(3, 3), pad=(1, 1), num_filter=256, workspace=2048, name="conv3_1")
relu3_1 = mx.symbol.Activation(data=conv3_1, act_type="relu", name="relu3_1")
conv3_2 = mx.symbol.Convolution(
data=relu3_1, kernel=(3, 3), pad=(1, 1), num_filter=256, workspace=2048, name="conv3_2")
relu3_2 = mx.symbol.Activation(data=conv3_2, act_type="relu", name="relu3_2")
conv3_3 = mx.symbol.Convolution(
data=relu3_2, kernel=(3, 3), pad=(1, 1), num_filter=256, workspace=2048, name="conv3_3")
relu3_3 = mx.symbol.Activation(data=conv3_3, act_type="relu", name="relu3_3")
pool3 = mx.symbol.Pooling(
data=relu3_3, pool_type="max", kernel=(2, 2), stride=(2, 2), name="pool3")
# group 4
conv4_1 = mx.symbol.Convolution(
data=pool3, kernel=(3, 3), pad=(1, 1), num_filter=512, workspace=2048, name="conv4_1")
relu4_1 = mx.symbol.Activation(data=conv4_1, act_type="relu", name="relu4_1")
conv4_2 = mx.symbol.Convolution(
data=relu4_1, kernel=(3, 3), pad=(1, 1), num_filter=512, workspace=2048, name="conv4_2")
relu4_2 = mx.symbol.Activation(data=conv4_2, act_type="relu", name="relu4_2")
conv4_3 = mx.symbol.Convolution(
data=relu4_2, kernel=(3, 3), pad=(1, 1), num_filter=512, workspace=2048, name="conv4_3")
relu4_3 = mx.symbol.Activation(data=conv4_3, act_type="relu", name="relu4_3")
pool4 = mx.symbol.Pooling(
data=relu4_3, pool_type="max", kernel=(2, 2), stride=(2, 2), name="pool4")
# group 5
conv5_1 = mx.symbol.Convolution(
data=pool4, kernel=(3, 3), pad=(1, 1), num_filter=512, workspace=2048, name="conv5_1")
relu5_1 = mx.symbol.Activation(data=conv5_1, act_type="relu", name="relu5_1")
conv5_2 = mx.symbol.Convolution(
data=relu5_1, kernel=(3, 3), pad=(1, 1), num_filter=512, workspace=2048, name="conv5_2")
relu5_2 = mx.symbol.Activation(data=conv5_2, act_type="relu", name="relu5_2")
conv5_3 = mx.symbol.Convolution(
data=relu5_2, kernel=(3, 3), pad=(1, 1), num_filter=512, workspace=2048, name="conv5_3")
relu5_3 = mx.symbol.Activation(data=conv5_3, act_type="relu", name="relu5_3")
return relu5_3
特征提取器二
下面是最后的一小部分网络,我们将筛选出来的proposal作用于Feature Map,得到候选区域,然后使用ROIPooling得到大小一致的候选区域,这些区域送入本部分网络,得到用于分类、回归的特征,
def get_vgg_top_feature(data):
# group 6
flatten = mx.symbol.Flatten(data=data, name="flatten")
fc6 = mx.symbol.FullyConnected(data=flatten, num_hidden=4096, name="fc6")
relu6 = mx.symbol.Activation(data=fc6, act_type="relu", name="relu6")
drop6 = mx.symbol.Dropout(data=relu6, p=0.5, name="drop6")
# group 7
fc7 = mx.symbol.FullyConnected(data=drop6, num_hidden=4096, name="fc7")
relu7 = mx.symbol.Activation(data=fc7, act_type="relu", name="relu7")
drop7 = mx.symbol.Dropout(data=relu7, p=0.5, name="drop7")
return drop7
主体函数
函数接口
def get_vgg_train(anchor_scales, anchor_ratios, rpn_feature_stride,
rpn_pre_topk, rpn_post_topk, rpn_nms_thresh, rpn_min_size, rpn_batch_rois,
num_classes, rcnn_feature_stride, rcnn_pooled_size, rcnn_batch_size,
rcnn_batch_rois, rcnn_fg_fraction, rcnn_fg_overlap, rcnn_bbox_stds):
首先定义了一些用于接收数据&标签信息的占位符变量,
num_anchors = len(anchor_scales) * len(anchor_ratios)
data = mx.symbol.Variable(name="data") # 图片信息:[batch, channel, height, width]
im_info = mx.symbol.Variable(name="im_info")
gt_boxes = mx.symbol.Variable(name="gt_boxes") # 真实框信息:[obj数量, 5]
# anchor标签:-1、0、1 (无效、背景、目标)
rpn_label = mx.symbol.Variable(name='label') # [batch, 2, 中心点行数*每个位置anchors数目, 中心点列数]
# 根据初始anchor和ground truth计算出来的offset
rpn_bbox_target = mx.symbol.Variable(name='bbox_target') # [batch, 4*每个位置anchors数目, 中心点行数, 中心点列数]
# mask,如果anchor标签是1,则mask对应值为1,anchor标签是0或-1,则mask对应值为0
rpn_bbox_weight = mx.symbol.Variable(name='bbox_weight') # [batch, 4*每个位置anchors数目, 中心点行数, 中心点列数]
获取卷积特征

# shared convolutional layers
conv_feat = get_vgg_feature(data)
使用3×3的滑窗,进行卷积,
# RPN layers
rpn_conv = mx.symbol.Convolution(
data=conv_feat, kernel=(3, 3), pad=(1, 1), num_filter=512, name="rpn_conv_3x3")
rpn_relu = mx.symbol.Activation(data=rpn_conv, act_type="relu", name="rpn_relu")
每个滑动窗口位置生成9个候选窗口(不同尺度、不同宽高),对应36个坐标、18个分类,(即根据每张图片的feat map大小,生成对应数量的中心点,以及候选框体)
RPN calssification(anchor good.bad)
下面是计算全部候选窗口对应2分类的部分,生成损失函数的第一部分:全部候选窗含/不含obj的二分类损失,

# rpn classification: obj / not_obj
# [batch, 2*每个位置anchors数目, 中心点行数, 中心点列数]
rpn_cls_score = mx.symbol.Convolution(
data=rpn_relu, kernel=(1, 1), pad=(0, 0), num_filter=2 * num_anchors, name="rpn_cls_score")
# [batch, 2, 中心点行数*每个位置anchors数目, 中心点列数]
rpn_cls_score_reshape = mx.symbol.Reshape(
data=rpn_cls_score, shape=(0, 2, -1, 0), name="rpn_cls_score_reshape")
# 获取交叉熵回传梯度,对于出现了-1的图片梯度直接全部置为0
# 在Faster RCNN算法中,anchor一共有3种标签:-1、0、1,分别表示无效、背景、目标
rpn_cls_prob = mx.symbol.SoftmaxOutput(data=rpn_cls_score_reshape, label=rpn_label, multi_output=True,
normalization='valid', use_ignore=True, ignore_label=-1, name="rpn_cls_prob")
# 切换为含/不含obj两通道,对每一个anchor是否有obj进行softmax处理
# [batch, 2, 中心点行数*每个位置anchors数目, 中心点列数]
rpn_cls_act = mx.symbol.softmax(
data=rpn_cls_score_reshape, axis=1, name="rpn_cls_act")
# [batch, 2*每个位置anchors数目, 中心点行数, 中心点列数]
# Reshpe方法不同于reshape方法,详情见此方法文档
rpn_cls_act_reshape = mx.symbol.Reshape(
data=rpn_cls_act, shape=(0, 2 * num_anchors, -1, 0), name='rpn_cls_act_reshape')
RPN regression(anchor->propoasal)
下面计算全部候选窗口对应4个坐标值的部分,生成损失函数第二部分:全部候选框坐标回归,

# rpn bbox regression
# [batch, 4*每个位置anchors数目, 中心点行数, 中心点列数]
rpn_bbox_pred = mx.symbol.Convolution(
data=rpn_relu, kernel=(1, 1), pad=(0, 0), num_filter=4 * num_anchors, name="rpn_bbox_pred")
# rpn_bbox_weight: anchor的mask,如果某个anchor的标签是1,则mask对应值为1,anchor的标签是0或-1,则mask对应值为0
# rpn_bbox_target: 根据初始anchor和ground truth计算出来的offset
rpn_bbox_loss_ = rpn_bbox_weight * mx.symbol.smooth_l1(name='rpn_bbox_loss_',
scalar=3.0,
data=(rpn_bbox_pred - rpn_bbox_target))
# 获取回归梯度
# grad_scale: 表示回归损失占RPN网络总损失比,该参数相差几个量级对结果影响也不大
rpn_bbox_loss = mx.sym.MakeLoss(name='rpn_bbox_loss', data=rpn_bbox_loss_, grad_scale=1.0 / rpn_batch_rois)
候选框生成
我们会获取数量繁多的候选框(即上面得到的候选框含有obj的得分和候选框坐标修正值),首先会根据框体含有obj的概率进行一次初筛,然后经由非极大值抑制算法筛选2000个候选框进入下一步的操作;在第二步中,我们会获取最终的128个候选框、它们各自对应的标签、它们坐标回归的目标、以及标定它们正负的坐标掩码,用于精确的训练候选框,生成目标边框。这个一步的操作使用了作者新建的操作节点,具体实现见源码,这里只简单介绍该操作的输入输出以及作用。
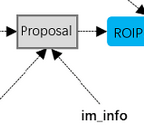
另注,函数返回的候选框5个属性与后面的ROIPooling一脉相承,[候选框对应batch中图片的索引,候选框坐标×4],后面使用这个值可以直接进行ROIPooling。
# rpn proposal
# 获取指定数目的候选框proposal
# [2000个候选框, 5个属性]
# 5个属性: batch中图片index,4个坐标
rois = mx.symbol.contrib.MultiProposal(
cls_prob=rpn_cls_act_reshape, # cls_prob: [batch, 2*每个位置anchors数目, 中心点行数, 中心点列数]
bbox_pred=rpn_bbox_pred, # bbox_pred: [batch, 4*每个位置anchors数目, 中心点行数, 中心点列数]
im_info=im_info, # mx.symbol.Variable(name="im_info")
feature_stride=rpn_feature_stride, # 16
scales=anchor_scales, ratios=anchor_ratios, # (0.5, 1, 2)
rpn_pre_nms_top_n=rpn_pre_topk, # 12000,对RPN网络输出的anchor进行NMS操作之前的proposal最大数量
# 输入proposal的数量大于12000时,对这些proposal的预测为foreground的概率(也叫score,
# 换句话说就是预测标签为1的概率)从高到低排序,然后选择前面12000个
rpn_post_nms_top_n=rpn_post_topk, # 2000,经过NMS过滤之后得到的proposal数量
threshold=rpn_nms_thresh, # 0.7,是NMS算法阈值
rpn_min_size=rpn_min_size, # 16
name = 'rois'
)
# rcnn roi proposal target
# 根据上一步获取的proposal(即rois)和真实框(gt_boxes)进行筛选
# 获取128个proposal,对应的128个label,对应的128个真实坐标,128个坐标掩码(构建损失函数使用)
group = mx.symbol.Custom(rois=rois, # 2000*5的roi信息
gt_boxes=gt_boxes, # n*5的ground truth信息,n表示object数量
op_type='proposal_target',
num_classes=num_classes, # num_classes是实际要分类的类别数加上背景类
batch_images=rcnn_batch_size, # 1
batch_rois=rcnn_batch_rois, # 128
fg_fraction=rcnn_fg_fraction, # 0.25,正样本所占的比例
fg_overlap=rcnn_fg_overlap, # 0.5
box_stds=rcnn_bbox_stds # (0.1, 0.1, 0.2, 0.2)
)
rois = group[0] # rois (128, 5)
label = group[1] # roi对应的标签(128)
bbox_target = group[2] # 坐标回归的目标,维度是(128,84), 其中84来自(20+1)*4
bbox_weight = group[3] # 坐标回归时候的权重,维度是(128,84),对于foreground都是1,对于backgroud都是0
在RPN网络得到proposal后还会经过一系列的过滤操作才会得到送入检测网络的proposal,节点proposal_target会将2000个proposal过滤成128个,且为这128个proposal分配标签、回归目标、定义正负样本的1:3比例等,这部分算是RPN网络和检测网络(Fast RCNN)的衔接,值得注意的是该节点不接受后面层数传递而来的梯度,且向前传递梯度强制为0,已即网络训练由其割裂为两个部分(尽管两部分仍然相连)。
ROIPooling层
将任意大小的输入层下采样为同样大小的输出层,方便后面的计算。这里我们使用候选框(128个)寻找各自对应的图片,并将各自对应的区域裁剪出来,然后pooling为同样的大小,
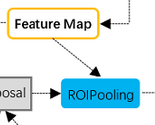
本层的两条虚线输入中上面一条表示batch图像特征,下面一条表示候选框输入
# rcnn roi pool
# [128个候选框, 512个通道, 7行, 7列]
roi_pool = mx.symbol.ROIPooling(
name='roi_pool',
data=conv_feat,
rois=rois,
pooled_size=rcnn_pooled_size, # (7, 7),输出大小
spatial_scale=1.0 / rcnn_feature_stride # 16, feat/raw_img
)
将对应的候选区域(注意此时抠图完成,已经不是候选框了)经由vgg的分类头部分(实际上就是对候选区域再进一步抽象提取特征)进行处理,
# rcnn top feature
# [128, 4096],对每个roi提取最终的vgg特征
top_feat = get_vgg_top_feature(roi_pool)
最后的两个损失函数生成过程,对128个候选区域的抽象特征进行分类(此时不是含/不含obj,而是直接进行21分类),并对每一个抽象特征回归出4个坐标值,
两个损失函数标签均来自上面自定义节点的输出:
label = group[1] # roi对应的标签(128)
bbox_target = group[2] # 坐标回归的目标,维度是(128,84), 其中84来自(20+1)*4
bbox_weight = group[3] # 坐标回归时候的权重,维度是(128,84),对于foreground都是1,对于backgroud都是0
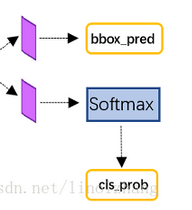
# rcnn classification
# 对每个roi进行分类,并构建损失函数
cls_score = mx.symbol.FullyConnected(name='cls_score', data=top_feat, num_hidden=num_classes)
cls_prob = mx.symbol.SoftmaxOutput(name='cls_prob', data=cls_score, label=label, normalization='batch')
# rcnn bbox regression
# 对每个roi进行回归,并构建损失函数
bbox_pred = mx.symbol.FullyConnected(name='bbox_pred', data=top_feat, num_hidden=num_classes * 4)
bbox_loss_ = bbox_weight * mx.symbol.smooth_l1(name='bbox_loss_', scalar=1.0, data=(bbox_pred - bbox_target))
bbox_loss = mx.sym.MakeLoss(name='bbox_loss', data=bbox_loss_, grad_scale=1.0 / rcnn_batch_rois)
附、主体函数全览
def get_vgg_train(anchor_scales, anchor_ratios, rpn_feature_stride,
rpn_pre_topk, rpn_post_topk, rpn_nms_thresh, rpn_min_size, rpn_batch_rois,
num_classes, rcnn_feature_stride, rcnn_pooled_size, rcnn_batch_size,
rcnn_batch_rois, rcnn_fg_fraction, rcnn_fg_overlap, rcnn_bbox_stds):
num_anchors = len(anchor_scales) * len(anchor_ratios)
data = mx.symbol.Variable(name="data") # 图片信息:[batch, channel, height, width]
im_info = mx.symbol.Variable(name="im_info")
gt_boxes = mx.symbol.Variable(name="gt_boxes") # 真实框信息:[obj数量, 5]
# anchor标签:-1、0、1 (无效、背景、目标)
rpn_label = mx.symbol.Variable(name='label') # [batch, 2, 中心点行数*每个位置anchors数目, 中心点列数]
# 根据初始anchor和ground truth计算出来的offset
rpn_bbox_target = mx.symbol.Variable(name='bbox_target') # [batch, 4*每个位置anchors数目, 中心点行数, 中心点列数]
# mask,如果anchor标签是1,则mask对应值为1,anchor标签是0或-1,则mask对应值为0
rpn_bbox_weight = mx.symbol.Variable(name='bbox_weight') # [batch, 4*每个位置anchors数目, 中心点行数, 中心点列数]
# shared convolutional layers
conv_feat = get_vgg_feature(data)
# RPN layers
rpn_conv = mx.symbol.Convolution(
data=conv_feat, kernel=(3, 3), pad=(1, 1), num_filter=512, name="rpn_conv_3x3")
rpn_relu = mx.symbol.Activation(data=rpn_conv, act_type="relu", name="rpn_relu")
# rpn classification: obj / not_obj
# [batch, 2*每个位置anchors数目, 中心点行数, 中心点列数]
rpn_cls_score = mx.symbol.Convolution(
data=rpn_relu, kernel=(1, 1), pad=(0, 0), num_filter=2 * num_anchors, name="rpn_cls_score")
# [batch, 2, 中心点行数*每个位置anchors数目, 中心点列数]
rpn_cls_score_reshape = mx.symbol.Reshape(
data=rpn_cls_score, shape=(0, 2, -1, 0), name="rpn_cls_score_reshape")
# 获取交叉熵回传梯度,对于出现了-1的图片梯度直接全部置为0
# 在Faster RCNN算法中,anchor一共有3种标签:-1、0、1,分别表示无效、背景、目标
rpn_cls_prob = mx.symbol.SoftmaxOutput(data=rpn_cls_score_reshape, label=rpn_label, multi_output=True,
normalization='valid', use_ignore=True, ignore_label=-1, name="rpn_cls_prob")
# 切换为含/不含obj两通道,对每一个anchor是否有obj进行softmax处理
# [batch, 2, 中心点行数*每个位置anchors数目, 中心点列数]
rpn_cls_act = mx.symbol.softmax(
data=rpn_cls_score_reshape, axis=1, name="rpn_cls_act")
# [batch, 2*每个位置anchors数目, 中心点行数, 中心点列数]
# Reshpe方法不同于reshape方法,详情见此方法文档
rpn_cls_act_reshape = mx.symbol.Reshape(
data=rpn_cls_act, shape=(0, 2 * num_anchors, -1, 0), name='rpn_cls_act_reshape')
# rpn bbox regression
# [batch, 4*每个位置anchors数目, 中心点行数, 中心点列数]
rpn_bbox_pred = mx.symbol.Convolution(
data=rpn_relu, kernel=(1, 1), pad=(0, 0), num_filter=4 * num_anchors, name="rpn_bbox_pred")
# rpn_bbox_weight: anchor的mask,如果某个anchor的标签是1,则mask对应值为1,anchor的标签是0或-1,则mask对应值为0
# rpn_bbox_target: 根据初始anchor和ground truth计算出来的offset
rpn_bbox_loss_ = rpn_bbox_weight * mx.symbol.smooth_l1(name='rpn_bbox_loss_',
scalar=3.0,
data=(rpn_bbox_pred - rpn_bbox_target))
# 获取回归梯度
# grad_scale: 表示回归损失占RPN网络总损失比,该参数相差几个量级对结果影响也不大
rpn_bbox_loss = mx.sym.MakeLoss(name='rpn_bbox_loss', data=rpn_bbox_loss_, grad_scale=1.0 / rpn_batch_rois)
# rpn proposal
# 获取指定数目的候选框proposal
# [2000个候选框, 5个属性]
# 5个属性: batch中图片index,4个坐标
rois = mx.symbol.contrib.MultiProposal(
cls_prob=rpn_cls_act_reshape, # cls_prob: [batch, 2*每个位置anchors数目, 中心点行数, 中心点列数]
bbox_pred=rpn_bbox_pred, # bbox_pred: [batch, 4*每个位置anchors数目, 中心点行数, 中心点列数]
im_info=im_info, # mx.symbol.Variable(name="im_info")
feature_stride=rpn_feature_stride, # 16
scales=anchor_scales, ratios=anchor_ratios, # (0.5, 1, 2)
rpn_pre_nms_top_n=rpn_pre_topk, # 12000,对RPN网络输出的anchor进行NMS操作之前的proposal最大数量
# 输入proposal的数量大于12000时,对这些proposal的预测为foreground的概率(也叫score,
# 换句话说就是预测标签为1的概率)从高到低排序,然后选择前面12000个
rpn_post_nms_top_n=rpn_post_topk, # 2000,经过NMS过滤之后得到的proposal数量
threshold=rpn_nms_thresh, # 0.7,是NMS算法阈值
rpn_min_size=rpn_min_size, # 16
name = 'rois'
)
# rcnn roi proposal target
# 根据上一步获取的proposal(即rois)和真实框(gt_boxes)进行筛选
# 获取128个proposal,对应的128个label,对应的128个真实坐标,128个坐标掩码(构建损失函数使用)
group = mx.symbol.Custom(rois=rois, # 2000*5的roi信息
gt_boxes=gt_boxes, # n*5的ground truth信息,n表示object数量
op_type='proposal_target',
num_classes=num_classes, # num_classes是实际要分类的类别数加上背景类
batch_images=rcnn_batch_size, # 1
batch_rois=rcnn_batch_rois, # 128
fg_fraction=rcnn_fg_fraction, # 0.25,正样本所占的比例
fg_overlap=rcnn_fg_overlap, # 0.5
box_stds=rcnn_bbox_stds # (0.1, 0.1, 0.2, 0.2)
)
rois = group[0] # rois (128, 5)
label = group[1] # roi对应的标签(128)
bbox_target = group[2] # 坐标回归的目标,维度是(128,84), 其中84来自(20+1)*4
bbox_weight = group[3] # 坐标回归时候的权重,维度是(128,84),对于foreground都是1,对于backgroud都是0
# rcnn roi pool
# [128个候选框, 512个通道, 7行, 7列]
roi_pool = mx.symbol.ROIPooling(
name='roi_pool',
data=conv_feat,
rois=rois,
pooled_size=rcnn_pooled_size, # (7, 7),输出大小
spatial_scale=1.0 / rcnn_feature_stride # 16, feat/raw_img
)
# rcnn top feature
# [128, 4096],对每个roi提取最终的vgg特征
top_feat = get_vgg_top_feature(roi_pool)
# rcnn classification
# 对每个roi进行分类,并构建损失函数
cls_score = mx.symbol.FullyConnected(name='cls_score', data=top_feat, num_hidden=num_classes)
cls_prob = mx.symbol.SoftmaxOutput(name='cls_prob', data=cls_score, label=label, normalization='batch')
# rcnn bbox regression
# 对每个roi进行回归,并构建损失函数
bbox_pred = mx.symbol.FullyConnected(name='bbox_pred', data=top_feat, num_hidden=num_classes * 4)
bbox_loss_ = bbox_weight * mx.symbol.smooth_l1(name='bbox_loss_', scalar=1.0, data=(bbox_pred - bbox_target))
bbox_loss = mx.sym.MakeLoss(name='bbox_loss', data=bbox_loss_, grad_scale=1.0 / rcnn_batch_rois)
# reshape output
# [1, 128], [1, 128, 21], [1, 128, 84]
label = mx.symbol.Reshape(data=label, shape=(rcnn_batch_size, -1), name='label_reshape')
cls_prob = mx.symbol.Reshape(data=cls_prob, shape=(rcnn_batch_size, -1, num_classes), name='cls_prob_reshape')
bbox_loss = mx.symbol.Reshape(data=bbox_loss, shape=(rcnn_batch_size, -1, 4 * num_classes), name='bbox_loss_reshape')
print(cls_score.infer_shape(**{'data': (1, 3, 1000, 600), 'gt_boxes': (5, 5)})[1])
# group output
# mx.symbol.BlockGrad会阻止经由节点label回传的梯度
group = mx.symbol.Group([rpn_cls_prob, # anchors分类损失:[batch, 2, 中心点行数*每个位置anchors数目, 中心点列数]
rpn_bbox_loss, # anchors回归损失:[batch, 4*每个位置anchors数目, 中心点行数, 中心点列数]
cls_prob, # 候选框分类损失:[1, 128, 21]
bbox_loss, # 候选框回归损失:[1, 128, 84]
mx.symbol.BlockGrad(label) # 候选框标签:[1, 128]
])
return group
if __name__=='__main__':
net = get_vgg_train(anchor_scales=(8, 16, 32),
anchor_ratios=(0.5, 1, 2),
rpn_feature_stride=16,
rpn_pre_topk=12000,
rpn_post_topk=2000,
rpn_nms_thresh=0.7,
rpn_min_size=16,
rpn_batch_rois=256,
num_classes=21,
rcnn_feature_stride=16, # 4个pooling层
rcnn_pooled_size=(7, 7),
rcnn_batch_size=1,
rcnn_batch_rois=128,
rcnn_fg_fraction=0.25,
rcnn_fg_overlap=0.5,
rcnn_bbox_stds=(0.1, 0.1, 0.2, 0.2))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号