

『TensorFlow Internals』笔记_系统架构
一、架构概览
TensorFlow 的系统结构以 C API 为界,将整个系统分为前端和后端两个子系统:
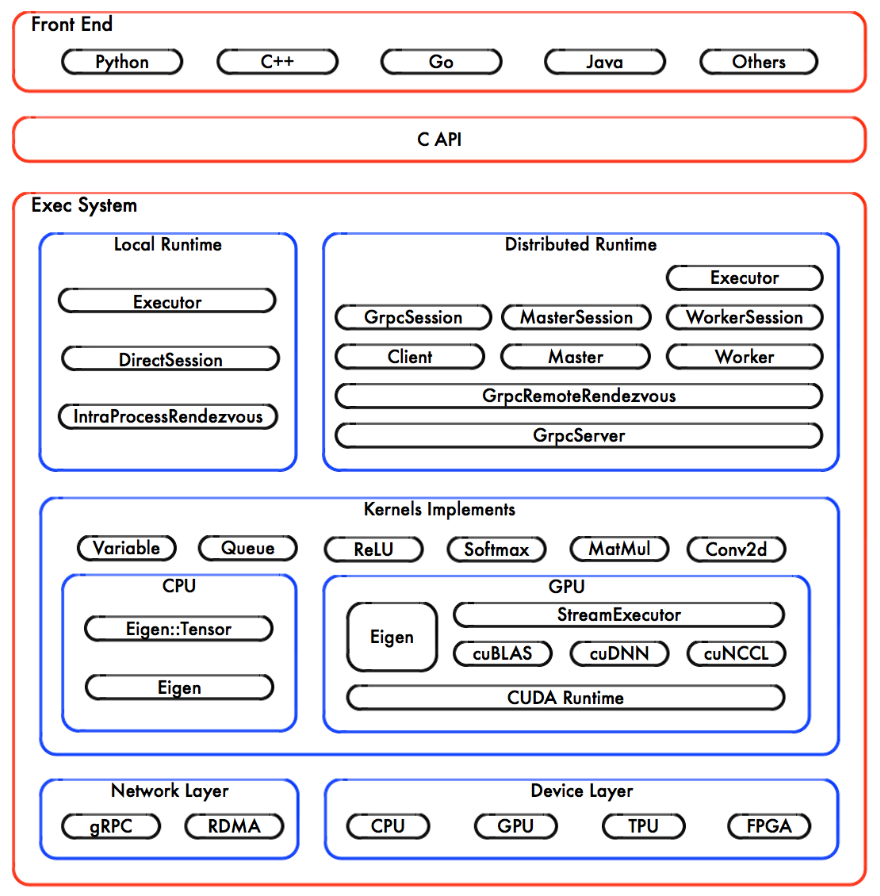
前端系统:提供编程模型,负责构造计算图;
后端系统:提供运行时环境,负责执行计算图,后端系统的设计和实现可以进一步分解为 4 层;
1. 运行层:分别提供本地模式和分布式模式,并共享大部分设计和实现;
2. 计算层:由各个 OP 的 Kernel 实现组成;在运行时,Kernel 实现执行 OP 的具
体数学运算;3. 通信层:基于 gRPC 实现组件间的数据交换,并能够在支持 IB 网络的节点间实
现 RDMA 通信;4. 设备层:计算设备是 OP 执行的主要载体,TensorFlow 支持多种异构的计算设备
类型。
从图操作的角度看待系统行为,TensorFlow 运行时就是完成计算图的构造、编排、及
其运行。
1. 表达图:构造计算图,但不执行图;
2. 编排图:将计算图的节点以最佳的执行方案部署在集群中各个计算设备上执行;
3. 运行图:按照拓扑排序执行图中的节点,并启动每个 OP 的 Kernel 计算。
二、主要模块
Client
前端系统主要组成部分,用于构造计算图,支持多种语言,python 的 API 最为完善。
注意本部仅仅构造计算图,不执行计算图,后面和后台计算引擎建立 Session 后,以之为桥梁,建立 Client 与 Master 的通道,将 Protobuf 格式的 GraphDef 序列化后传给 Master,才能启动图的执行计算过程。
Master
Client 执行 Session.run 时,传递整个计算图给 Master,完整的计算图称为Full Graph,随后, Master 根据 fetches、feeds 参数列表,反向遍历 Full Graph,按照依赖关系,剪枝图,得到最小依赖子图,称为 Client Graph。
接着,Master 负责将 Client Graph 按照任务的名称分裂 ( SplitByTask ) 为多个 GraphPartition;其中,每个 Worker 对应一个 Graph Partition。随后,Master 将 Graph Partition分别注册到相应的 Worker 上,以便在不同的 Worker 上并发执行这些 Graph Partition。最后,Master 将通知所有 Work 启动相应 Graph Partition 的执行过程。
其中,Work 之间可能存在数据依赖关系,Master 并不参与两者之间的数据交换,它们两两之间互相通信,独立地完成交换数据,直至完成所有计算。
Worker
对于每一个任务,TensorFlow 都将启动一个 Worker 实例。Worker 主要负责如下 3 个方面的职责:
1. 处理来自 Master 的请求;
2. 对注册的 Graph Partition 按照本地计算设备集实施二次分裂 ( SplitByDevice ) ,并通知各个计算设备并发执行各个 Graph Partition;
3. 按照拓扑排序算法在某个计算设备上执行本地子图,并调度 OP 的 Kernel 实现;
4. 协同任务之间的数据通信。
首先,Worker 收到 Master 发送过来的图执行命令,此时的计算图相对于 Worker 是完整的,也称为
Full Graph,它对应于 Master 的一个 Graph Partition。随后,Worker 根据当前可用的硬件环境,包括
(GPU/CPU) 资源,按照 OP 设备的约束规范,再将图分裂(SplitByDevice)为多个 Graph
Partition;其中,每个计算设备对应一个 Graph Partition。
接着,Worker 启动所有的 Graph Partition 的执行。最后,对于每一个计算设备,Worker将按照计算图中节点之间的依赖关系执行拓扑排序算法,并依次调用 OP 的 Kernel 实现,完成 OP 的运算 ( 一种典型的多态实现技术 ) 。
其中,Worker 还要负责将 OP 运算的结果发送到其他的 Worker 上去,或者接受来自其他 Worker 发送给它的运算结果,以便实现 Worker 之间的数据交互。TensorFlow 特化实现了源设备和目标设备间的 Send/Recv。
1. 本地 CPU 与 GPU 之间,使用 cudaMemcpyAsync 实现异步拷贝;
2. 本地 GPU 之间,使用端到端的 DMA 操作,避免主机端 CPU 的拷贝。
对于任务间的通信,TensorFlow 支持多种通信协议。
1. gRPC over TCP;
2. RDMA over Converged Ethernet。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号