
『MXNet』第三弹_Gluon模型参数
MXNet中含有init包,它包含了多种模型初始化方法。
from mxnet import init, nd from mxnet.gluon import nn net = nn.Sequential() net.add(nn.Dense(256, activation='relu')) net.add(nn.Dense(10)) net.initialize() x = nd.random.uniform(shape=(2,20)) y = net(x)
一、访问模型参数
我们知道可以通过[]来访问Sequential类构造出来的网络的特定层。对于带有模型参数的层,我们可以通过Block类的params属性来得到它包含的所有参数。例如我们查看隐藏层的参数:
print(net[0].params) print(net[0].collect_params())
dense0_ ( Parameter dense0_weight (shape=(256, 20), dtype=float32) Parameter dense0_bias (shape=(256,), dtype=float32) ) dense0_ ( Parameter dense0_weight (shape=(256, 20), dtype=float32) Parameter dense0_bias (shape=(256,), dtype=float32) )
有意思的是,
print(net.params) print(net.collect_params())
sequential0_ ( ) sequential0_ ( Parameter dense0_weight (shape=(256, 20), dtype=float32) Parameter dense0_bias (shape=(256,), dtype=float32) Parameter dense1_weight (shape=(10, 256), dtype=float32) Parameter dense1_bias (shape=(10,), dtype=float32) )
为了访问特定参数,我们既可以通过名字来访问字典里的元素,也可以直接使用它的变量名。下面两种方法是等价的,但通常后者的代码可读性更好,
(net[0].params['dense0_weight'], net[0].weight)
(Parameter dense0_weight (shape=(256, 20), dtype=float32),
Parameter dense0_weight (shape=(256, 20), dtype=float32))
Parameter类
data和grad函数来访问:
net[0].weight.data() net[0].weight.grad()
声明方法一
至于Parameter类,是指mxnet.gluon.Parameter,声明需要名字和尺寸:
my_param = gluon.Parameter('exciting_parameter_yay', shape=(3, 3))
my_param.initialize()
声明方法二
我们还可以使用Block自带的ParameterDict类的成员变量params。顾名思义,这是一个由字符串类型的参数名字映射到Parameter类型的模型参数的字典。
我们可以通过get函数从ParameterDict创建Parameter,同样的声明需要名字和尺寸:
params = gluon.ParameterDict()
params.get("param2", shape=(2, 3))
params
( Parameter param2 (shape=(2, 3), dtype=<class 'numpy.float32'>) )
形如net.params返回的就是一个ParameterDict类,自己的层class书写时,就是用这个方式创建参数并被层class感知(收录进层隶属的ParameterDict类中)。
二、初始化模型参数
[-0.07, 0.07]之间均匀分布的随机数,偏差参数则全为0. 但经常我们需要使用其他的方法来初始话权重,MXNet的init模块里提供了多种预设的初始化方法。例如下面例子我们将权重参数初始化成均值为0,标准差为0.01的正态分布随机数。
# 非首次对模型初始化需要指定 force_reinit net.initialize(init=init.Normal(sigma=0.01), force_reinit=True)
- mxnet.init模块
- force_reinit为了防止用户失误将参数全部取消
自定义初始化函数
有时候我们需要的初始化方法并没有在init模块中提供,这时我们有两种方法来自定义参数初始化。
一种是实现一个Initializer类的子类
使得我们可以跟前面使用init.Normal那样使用它。在这个方法里,我们只需要实现_init_weight这个函数,将其传入的NDArray修改成需要的内容。下面例子里我们把权重初始化成[-10,-5]和[5,10]两个区间里均匀分布的随机数,教程只讲了weight初始化,后面查看源码还有bias的,以及一些其他的子方法,理论上用时再研究,不过方法二明显更简单易用……
class MyInit(init.Initializer):
def _init_weight(self, name, data):
print('Init', name, data.shape)
data[:] = nd.random.uniform(low=-10, high=10, shape=data.shape)
data *= data.abs() >= 5
net.initialize(MyInit(), force_reinit=True)
net[0].weight.data()[0]
第二种方法是我们通过Parameter类的set_data函数
可以直接改写模型参数。例如下例中我们将隐藏层参数在现有的基础上加1.
net[0].weight.set_data(net[0].weight.data()+1) net[0].weight.data()[0]
[ -4.36596727 8.57739449 9.98637581 1. 9.8275547 1. 6.98405075 1. 1. 1. 8.48575974 1. 1. 7.89100075 7.97887039 -5.11315536 1. 6.46652031 -8.73526287 10.48517227] <NDArray 20 @cpu(0)>
三、共享模型参数
在有些情况下,我们希望在多个层之间共享模型参数。我们在“模型构造”这一节看到了如何在Block类里forward函数里多次调用同一个类来完成。这里将介绍另外一个方法,它在构造层的时候指定使用特定的参数。如果不同层使用同一份参数,那么它们不管是在前向计算还是反向传播时都会共享共同的参数。
原理:层函数params API接收其他层函数的params属性即可
在下面例子里,我们让模型的第二隐藏层和第三隐藏层共享模型参数:
from mxnet import nd
from mxnet.gluon import nn
net = nn.Sequential()
shared = nn.Dense(8, activation='relu')
net.add(nn.Dense(8, activation='relu'),
shared,
nn.Dense(8, activation='relu', params=shared.params),
nn.Dense(10))
net.initialize()
x = nd.random.uniform(shape=(2,20))
net(x)
net[1].weight.data()[0] == net[2].weight.data()[0]
[ 1. 1. 1. 1. 1. 1. 1. 1.]
<NDArray 8 @cpu(0)>
我们在构造第三隐藏层时通过params来指定它使用第二隐藏层的参数。由于模型参数里包含了梯度,所以在反向传播计算时,第二隐藏层和第三隐藏层的梯度都会被累加在shared.params.grad()里。
四、模型延后初始化
从下面jupyter可以看到模型参数实际初始化的时机:既不是调用initialize时,也不是没次运行时,仅仅第一次送入数据运行时会调用函数进行参数初始化,所以MXNet不需要定义指定输入数据尺寸的关键也在这里。
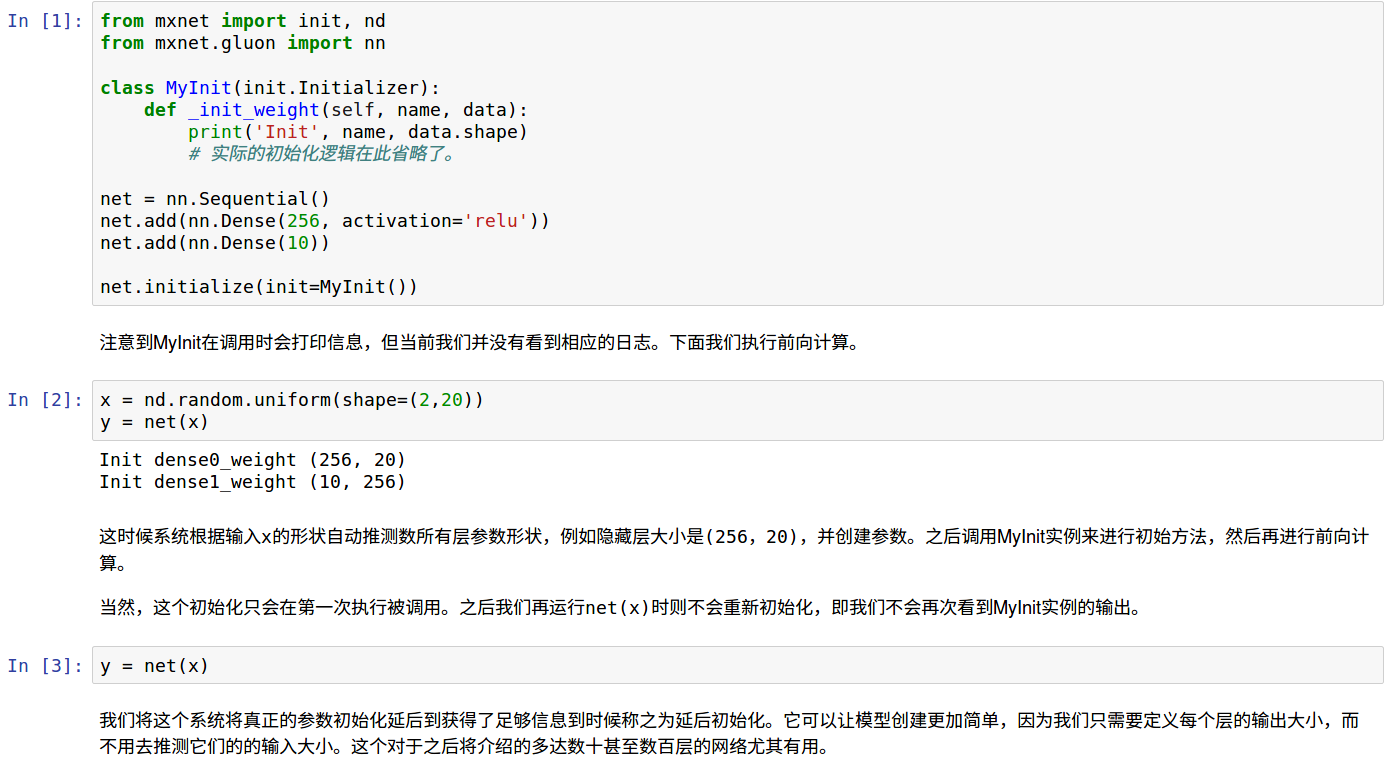
立即初始化参数
基于以上,当模型获悉数据尺寸时不会发生延后,
- 已经运行过,指定重新初始化时不会延后
- 定义过程中,指定in_units的模型不会延后
代码如下,
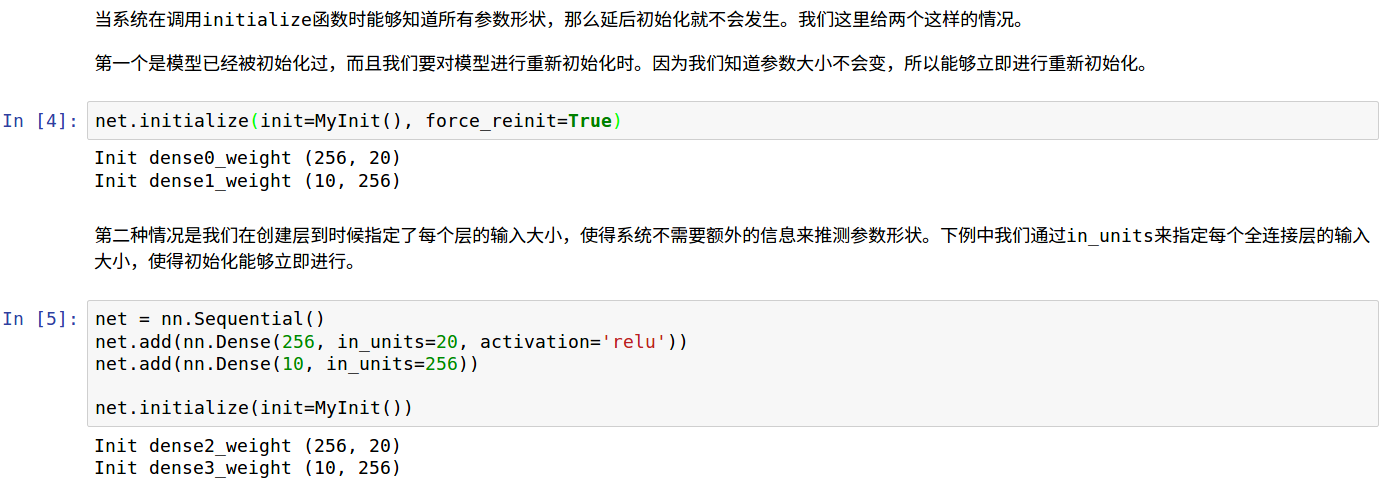
最后一格代码块中,第二个dense层去掉in_uints的话仅仅第一个dense会立即初始化。
数据形状改变时网络行为
如果在下一次net(x)前改变x形状,包括批量大小和特征大小,会发生什么?
批量大小改变不影响,特征大小改变会报错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号