
『Scrapy』全流程爬虫demo
建立好的爬虫工程如下:
item.py
它用来存储解析后的响应文件:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class ScrapyItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # pass name = scrapy.Field() title = scrapy.Field() info = scrapy.Field()
这是一个类似字典的数据结构,通过dict(items)可以直接转换为字典,以上面为例,其实例具有'name','title','info'三个key值。
spider爬虫
sipder需要调用item字典用于临时存储解析出来的数据,注意使用yield来动态化整个过程
这里面没有着重介绍解析过程,原因是我现在也不太懂
import scrapy from Scrapy.items import ScrapyItem class ITcastSpider(scrapy.Spider): # 名称 name = 'itcast' # 限制域 allowed_domains = 'itcast.cn' # 起始域 start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] def parse(self, response): node_list = response.xpath("//div[@class='li_txt']") for node in node_list: item = ScrapyItem() # name = node.xpath('./h3/text()').extract() title = node.xpath('./h4/text()').extract() info = node.xpath('./p/text()').extract() item['name'] = name[0] item['title'] = title[0] item['info'] = info[0] yield item
由于我本身对html并不熟悉,为了理解一下我去原网页查看了一下源码,对应部分的结构如下:

spider的补充说明
一,视频spider中的return是返回给引擎,引擎会根据返回值的内容的做出不同处理,
- 如果是上面的item实例,则会交给管线程序处理,
- 如果是list或者其他普通数据结构的话可以在crawl命令位置添加-o输出到文件,有一下四种输出,但是这种方法无法修改编码方式,
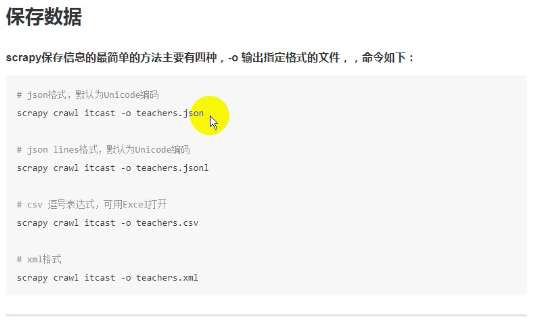
- return的是请求的话会进入新一轮的爬取,
![]()
二,有关response,这是一个响应对象,response.xpath()后是一个xpath对象,
print(node.xpath('./h3/text()'))
print(name)
print(name[0])
看看输出,
[<Selector xpath='./h3/text()' data='杨老师'>]
['杨老师']
杨老师
也就是说.extract()方法可以把xpath对象的data部分提取出来作为一个字符串列表。
另一处就是xpath对象的提取规则了,//表示全匹配(任意匹配)而./表示当前匹配xpath对象下的级,text()就是文本对象了,不单单是xpath,response的解析方式还有其他的,css也是可以的,本节不过多讨论。
settings.py
指定管道文件,下面的语句原本是注释掉的,我们需要取消注释并可以做出修改,字典中的数字表示优先级,0~1000,越小优先度越高,spider解析出来的item数据会按照优先级依次流入各个管道做后续处理(存储之类的),由于是依次,所以管道处理数据后返回值必须是原始数据,这在后面会看到
# Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'Scrapy.pipelines.ScrapyPipeline': 300, }
pipelines.py

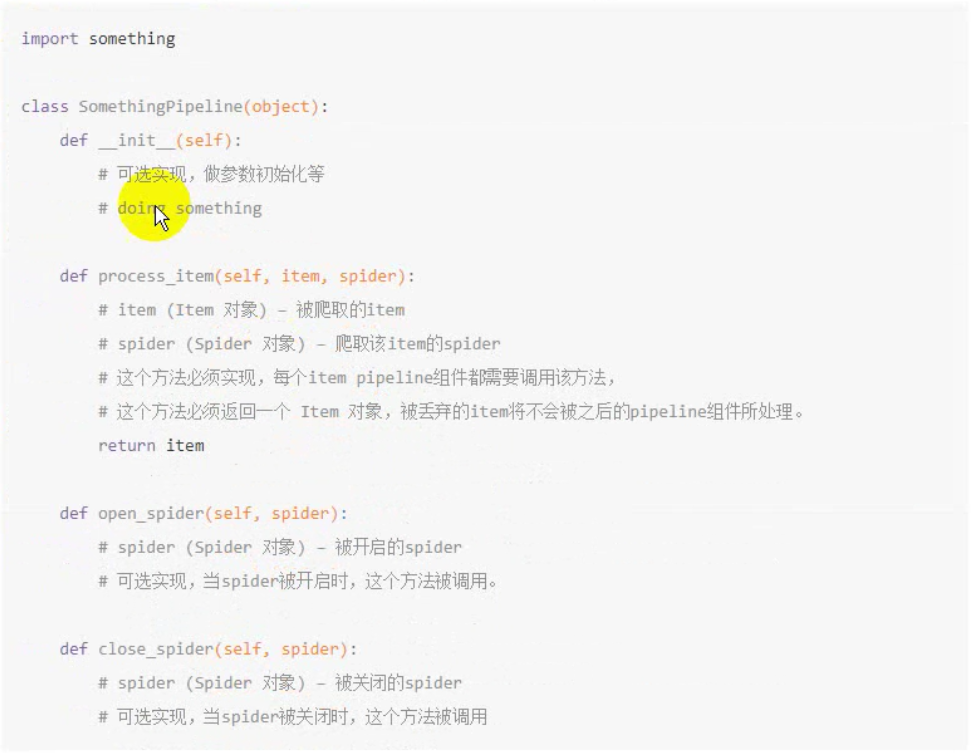
__init__()和close_spider()会被自动调用与爬虫起始与结束,process_item()会在每次出现返回值都被调用,并将自己的返回值交给下一优先级的管线
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class ScrapyPipeline(): def __init__(self): self.f = open('itcast_pipeline.json', 'w') def process_item(self, item, spider): content = json.dumps(dict(item), ensure_ascii=False) + '\n' self.f.write(content) # 必须return这个,可以传给下一管道 return item def close_spider(self,spider): self.f.close()
如果在这里面添加print(item),会看到输出如下,每次一行:
{'info': '五年以上教学经验及多年开发经验,精通C/S架构、B/S架构,涉足.NET、IOS等技术平台及各种数据库系统。精通多种主流编程语言。课上行云流水,通俗易懂,由浅入深,诙谐幽默。待学员如初恋,一个肯为学员玩命教学的男人! ', 'title': '高
级讲师', 'name': '杨老师'}
json.dumps()操作将字典转化为str,而json.loads()做反向变换,它们和保存文件的尾缀没有关系,由于默认是ascii格式保存一般中文会加上ensure_ascii=False:
In [1]: import json In [2]: a = {'name': 'wang', 'age': 29} In [3]: b = json.dumps(a) In [4]: print b, type(b) {"age": 29, "name": "wang"} <type 'str'> In [11]: json.loads(b) Out[11]: {u'age': 29, u'name': u'wang'} In [12]: print type(json.loads(b)) <type 'dict'>
运行
scrapy check itcast # 检查逻辑是否有错误
scrapy crawl itcast # 运行爬虫,注意,指定的是爬虫类的名称属性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号