
MASTER: Multi-aspect non-local network for scene text recognition
https://arxiv.org/pdf/1910.02562.pdf
总体介绍
基于Seq2Seq的OCR改进文章,提出两个问题,encoder特征间相似度太高导致注意力不准 & RNN-based的结构需要逐个step跑效率太低:
1、 such methods suffer from attention-drift problem because high similarity among encoded features leads to attention confusion under the RNN-based local attention mechanism.
2、RNN-based methods have low efficiency due to poor parallelization.
三个改进,加了2个自注意力机制 & 改进网络结构增强对空间的分辨能力 & 更有效的缓存机制加速:
(1) not only encodes the input-output attention but also learns self-attention which encodes feature-feature and target-target relationships inside the encoder and decoder
(2) learns a more powerful and robust intermediate representation to spatial distortion
(3) owns a great training efficiency because of high training parallelization and a high-speed inference because of an efficient memory-cache mechanism.
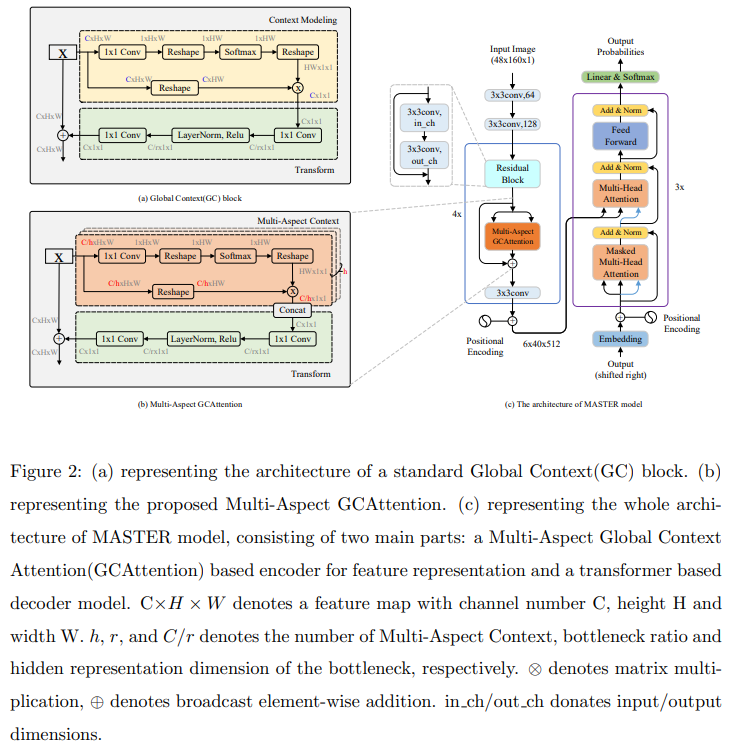
上图即为网络结构,
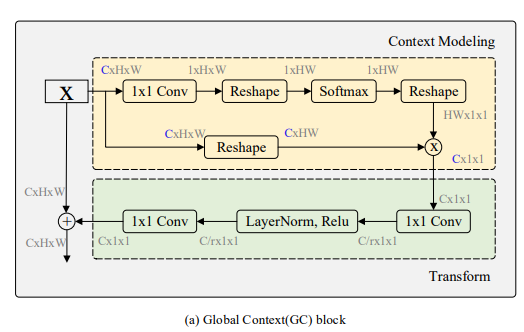
编码器种作者用Multi-Aspect Global Context Attention (GCAttention)结构改进了常规的resnet,从Fiegre2-a、Figure2-b可见GCA的结构:多头的Resnet Block。
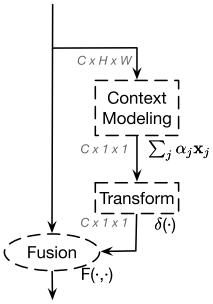
Global context
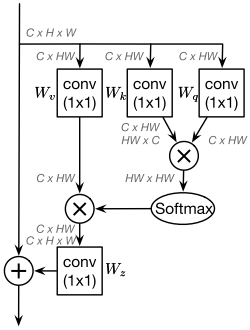
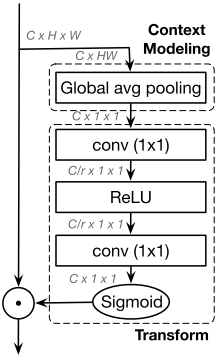
其中Figure2-a的结构(standard global context block)是比较老的ResNet改进了,是对non-local block的简化实现,下面这张图应该更为经典(解读见https://zhuanlan.zhihu.com/p/64988633):
| Non local | SENet | GCNet |
 |
 |
 |
Non local通过注意力机制给HW尺寸图的每个位置单独生成了HW尺寸的权重,HW的权重和C*HW的value作用生成每个位置的C*1*1的特征,共有HW个特征,GCNet的作者分析non local发现对于不同位置来说,它们的attention maps几乎是相同的,换句话说,虽然non-local block想要计算出每一个位置特定的全局上下文,但是经过训练之后,全局上下文是不受位置依赖的。即上non local图中的HW*HW的权重矩阵其实用1*HW即可(不同位置的权重统一表示),最后的特征也只有一个C*1*1。
GCNet实际将Q、K分支进行了合并,既然重要程度和位置无关,那自然没必要保留各个位置的Q去求各个位置K的响应了,直接变换学习到即可。
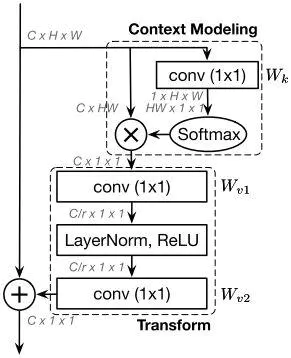
GCNet意义就是先计算了融合全局上下文信息的C个通道特征,然后捕获通道间的依赖,最后将各个通道的信息添加到原始特征上:
|

|
卷积也能拆分成空间依赖、通道依赖、特征融合三个步骤,Non-local和SENet有效主要是因为context modeling,卷积只能对局部区域进行context modeling,导致感受野受限制,而Non-local和SENet实际上是对整个输入feature进行context modeling,感受野可以覆盖到整个输入feature上,这对于网络来说是一个有益的语义信息补充。另外,网络仅仅通过卷积堆叠来提取特征,其实可以认为是用同一个形式的函数来拟合输入,导致网络提取特征缺乏多样性,而Non-local和SENet正好增加了提取特征的多样性,弥补了多样性的不足。GCNet充分结合了Non-local全局上下文建模能力强和SENet省计算量的优点,在各个计算机视觉任务上得到更好的结果。
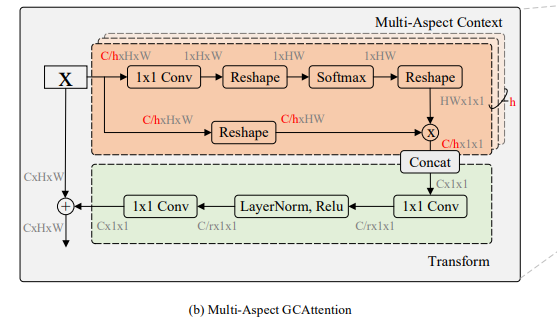
Multi-Apsect GCAttention (MAGC)
原GCNet输出C*1*1的特征中各个通道依赖同一个HW尺寸的权重,这不是很合理,作者采取多头的机制使得不同的通道对不同的位置的依赖权重不再相同。公式中计算alpha里的d我没怎么搞懂,说是为了抵消网络中不同的方差,
 |
|
embedding output实际就是attention输入 |

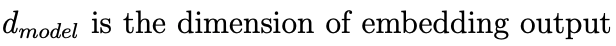
编码器就是GCA的堆叠,基于ResNet31实现。
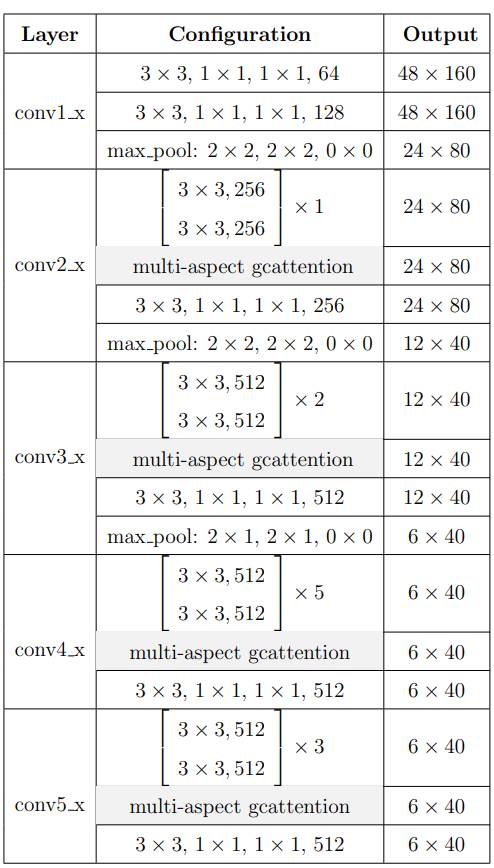
这里糅合了像素间的attn和通道间的attn,应该指的就是作者开篇时提到的改进1。
Decoder
 |
|
解码器每个block由3个元件组成: a Masked Multi-Head Attention, a Multi-Head Attention, a Feed-Forward Network (FFN). |
其实没啥好说的,3个原件都是是标准的transformer操作。
符号有10个数字52个大小写字母,以及4个特殊符号:
“<SOS>”, “<EOS>”, “<PAD>”, and “<UNK>” which indicate the start of the sequence, the end of the sequence, padding symbol and unknown characters (that are neither digit nor character)
原始transformer的attention实现如下,计算权重的位置实际上是[h, n, x, d_k]尺寸矩阵和[h, n, d_k, x]矩阵的矩阵乘法:
# QKV尺寸为:[h, n, x, d_k],表示head数目,batch size,字符数目,embeding维度
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
#首先取query的最后一维的大小,对应词嵌入维度
d_k = query.size(-1)
#按照注意力公式,将query与key的转置相乘,这里面key是将最后两个维度进行转置,再除以缩放系数得到注意力得分张量scores
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # [h, n, x, x] 即x对x的权重
#接着判断是否使用掩码张量
if mask is not None:
#使用tensor的masked_fill方法,将掩码张量和scores张量每个位置一一比较,如果掩码张量则对应的scores张量用-1e9这个置来替换
scores = scores.masked_fill(mask == 0, -1e9)
#对scores的最后一维进行softmax操作,使用F.softmax方法,这样获得最终的注意力张量
p_attn = F.softmax(scores, dim = -1)
#之后判断是否使用dropout进行随机置0
if dropout is not None:
p_attn = dropout(p_attn)
#最后,根据公式将p_attn与value张量相乘获得最终的query注意力表示,同时返回注意力张量
return torch.matmul(p_attn, value), p_attn
# 每次计算时先对[n, h, x, d_k]的最后一维进行线性变换,输出仍为[n, h, x, d_k]
# 1) Do all the linear projections in batch from d_model => h x d_k
# 首先利用zip将输入QKV与三个线性层组到一起,然后利用for循环,将输入QKV分别传到线性层中,做完线性变换后,开始为每个头分割输入,这里使用view方法对线性变换的结构进行维度重塑,多加了一个维度h代表头,这样就意味着每个头可以获得一部分词特征组成的句子,其中的-1代表自适应维度,计算机会根据这种变换自动计算这里的值,然后对第二维和第三维进行转置操作,为了让代表句子长度维度和词向量维度能够相邻,这样注意力机制才能找到词义与句子位置的关系,从attention函数中可以看到,利用的是原始输入的倒数第一和第二维,这样我们就得到了每个头的输入
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
# 得到每个头的输入后,接下来就是将他们传入到attention中,这里直接调用我们之前实现的attention函数,同时也将mask和dropout传入其中
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)作者优化的点在于:
问题1、attn前对QKV进行的线性变换每个block都会进行一次,每个step也都会进行一次
问题2、attn内部计算QK权重的位置,每个step计算时都会输出[h, n, x, x]尺寸,实际上不需要x对x个位置的attn,只需要当前位置对x个位置的attn
基于此,
针对问题1,作者先将b个transformer block的attn中的encoder输入的K、V的线性变换做好,避免每个step重复计算
针对问题2、在每个transformer block的self attn部分运算时,将当前step的输入进行线性变换映射出的k、v进行缓存,下一step不需要重复计算之前的q、k的线形变换
由于两个缓存,每个step的输入仅为当前step的特征,不再包含之前step的特征,故“In each decoding step, q is always a 1D vector instead of a 2D matrix in traditional decoding framework”,也就是说[h, n, 1, d_x]取代[h, n, x, d_x]作为当前步骤的输入:

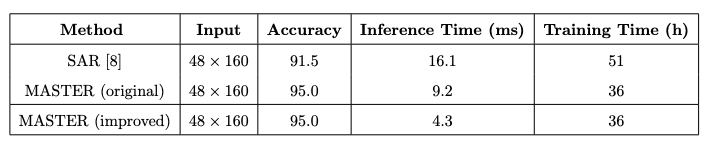
V100上单张推理速度比SAR还快,感觉综合效果很不错,不过SAR在mmocr的指标也到95%了(在mmocr上也是略逊master一筹倒是):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号