
『论文笔记』MoCo:Momentum Contrast for Unsupervised Visual Representation Learning
“
作者:田永龙
链接:https://www.zhihu.com/question/355779873/answer/895625711
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
”
对比是在正负例之间进行的,那负例越多,这个任务就越难,于是一个优化方向就是增加负例。
纯粹的增大batch size是不行的,总会受到GPU内存限制。一个可行的办法就是增加memory bank,把之前编码好的样本存储起来,计算loss的时候一起作为负例:

但这样有个问题是存储好的编码都是之前的编码器计算的,而xq的编码器一直在更新,会有两侧不一致的情况,影响目标优化。一个可行方法之一就是用最新的左侧encoder更新编码再放入memory bank,但这依然避免不了memory bank中表示不一致的情况,实验效果很差。还有研究用动量去更新样本表示,但这样必须存储所有样本,消耗过多内存。
所以何凯明在2019年底推出了MoCo(Momentum Contrast)模型,延续memory bank的思想,使用动量的方式更新encoder参数,解决新旧候选样本编码不一致的问题:
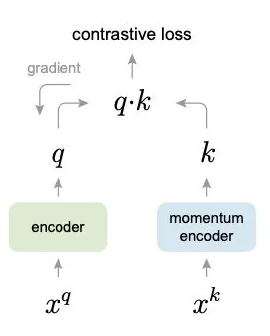

x_q:代表某一图片(定义为P_q)的图像增强操作(旋转、平移、剪切等)后的一个矩阵;
x_k:代表多张图片(定义为P_K, 其中P_K包含P_q)的图像增强操作后的多个矩阵的矩阵集;
encoder,momentum encoder:分别代表两个编码网络,这两个网络的结构相同,参数不同;
q:x_q经过encoder网络编码后的一个向量;
k:x_k经过momentum encoder网络编码后的多个向量;
contrastive loss(即L_q):
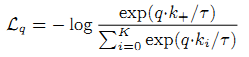
其中:
k_+是指x_k矩阵集中的那个来自对P_q图片的一次增强操作后形成的矩阵,经过momentum encoder网络编码后,形成的一个向量;
k_i是指x_k矩阵集中的每一个矩阵,经过momentum encoder网络编码后,形成的一个向量;这样的向量一共有K+1个(包含k_+),其中只有k_+是来自P_q图片,其它均来自“非”P_q图片;
T是一个常数;训练过程:
最小化L_q,通过后反馈仅调整更新encoder网络参数;而momentum encoder网络参数通过如下公式(momentum update)直接更新:
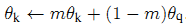
其中θ_k是指momentum encoder网络参数,θ_q是指encoder网络参数,m是一个介于0.0~ 1.0的动量系数。
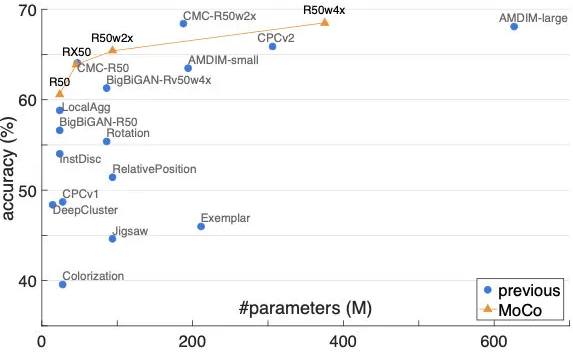
这样每次入队的新编码都是上一步更新后的编码器输出,以很低的速度慢慢迭代,与旧编码尽量保持一致。实验发现,m=0.999时比m=0.9好上很多。最终在ImageNet的实验效果也远超前人,成为当时的SOTA:
训练过程如下:
1 初始化
准备一批图片Ps(如共1000000张图片,编号0~1000000)。
创建encoder和momentum encoder两个模型,这两个模型的网络结构是一样的,初始参数也是一样的(训练开始后两者参数将不再一样)。
从Ps中选择前n张(如n=5000)进行数据增强操作得5000个矩阵,并将这些矩阵输入到momentum encoder生成5000个d维(如d=128)向量;定义这5000个128维的向量集合为Queue(Queue将是动态更新的)。
2 训练单元
2.1 从Ps中提取1张(第5001张)新图片pi;
2.2 对pi进行一次数据增强得矩阵x_q_i,其shape=[1, 224, 224, 3];对pi再进行一次数据增强得矩阵集x_k_i,其shape=[1, 224, 224,3];其中x_q_i和x_k_i两者并不相同,但是都是pi的一次增强。
2.3 将x_q_i输入到encoder网络得矩阵q_i,其shape=[1, 128];将x_k_i输入到momentum encoder网络得矩阵k_i,其shape=[1, 128]。
2.4 从Queue中取出所有向量(共k个)k_is,其shape=[k, 128]。
2.5 定义q_i为q,其shape=[1,128];将k_i和k_is合并定义为Ks,其shape=[k+1, 128]。
2.6 更新网络参数
由如下公式计算loss(其中k+是k_i,其它ki均来自k_is):
最小化该loss函数,由后反馈仅更新encoder网络参数;而momentum encoder网络参数由如下公式更新(其中θ_k,θ_q分别是momentum encoder网络和encoder网络参数):
2.7 更新Queue
删除Queue的第一个元素,并在其最后添加元素k_i;操作后Queue的size不变。
2.8 实际训练是批量进行的,即Ps中同时取出N(如n=256)张新图片,同时进行上述处理,Queue的更新的最小单元也是256个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号